-
-
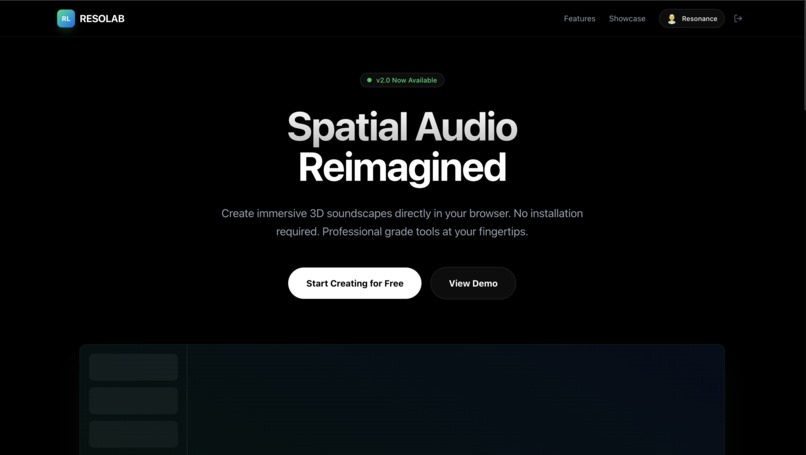
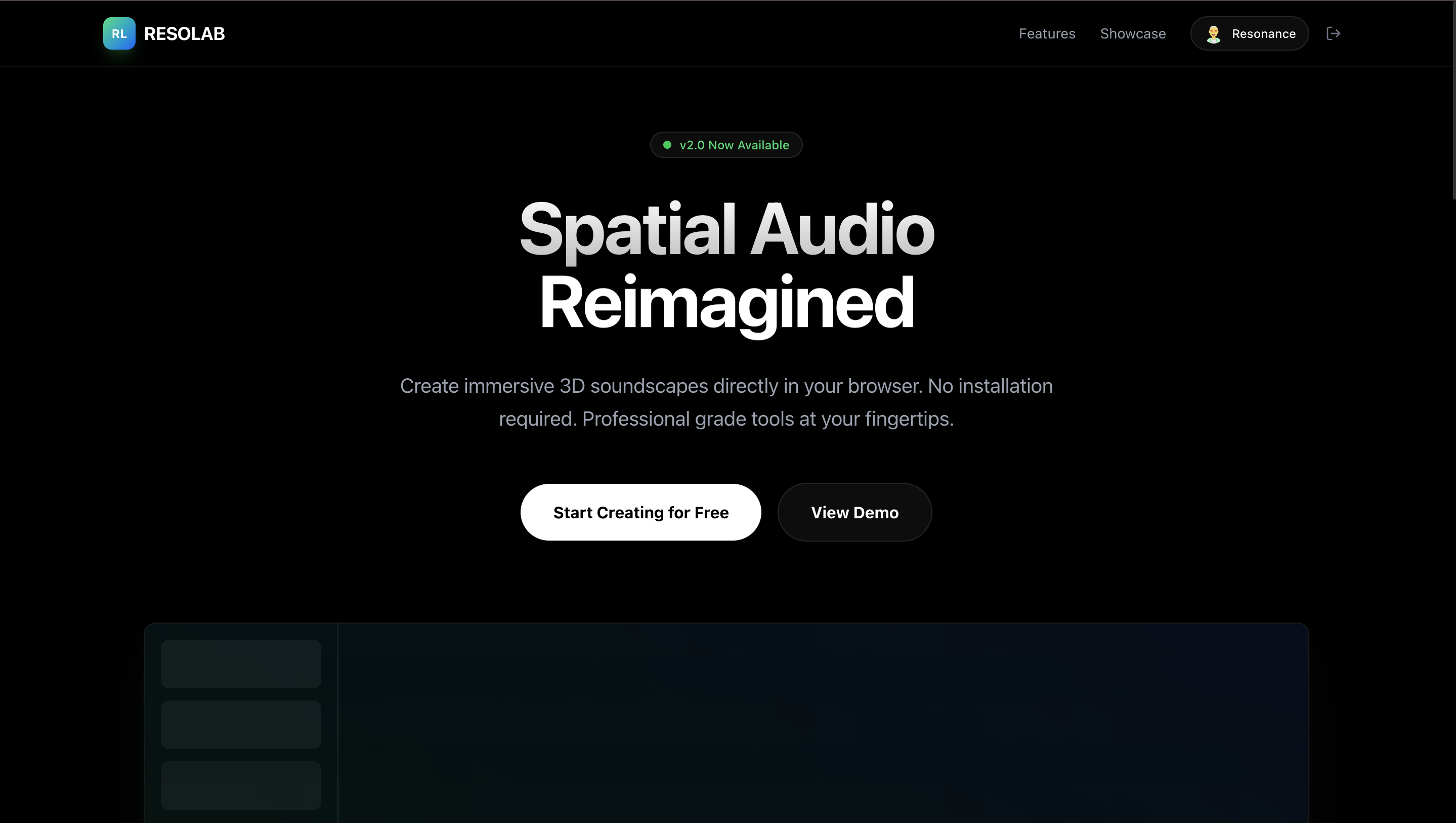
Landing Page
-
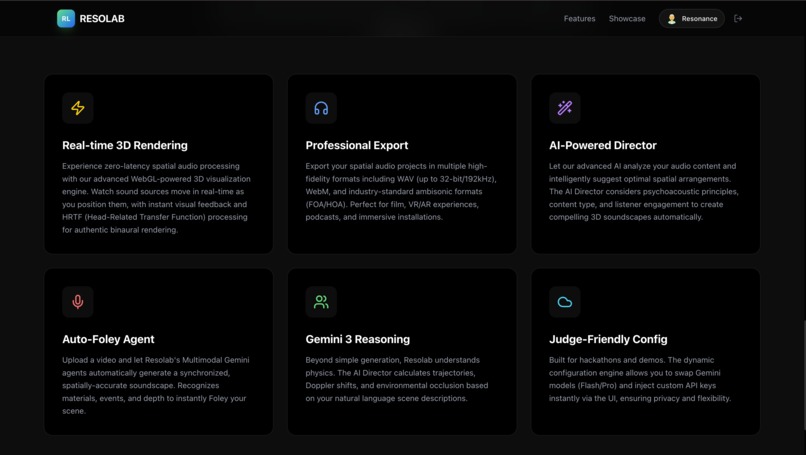
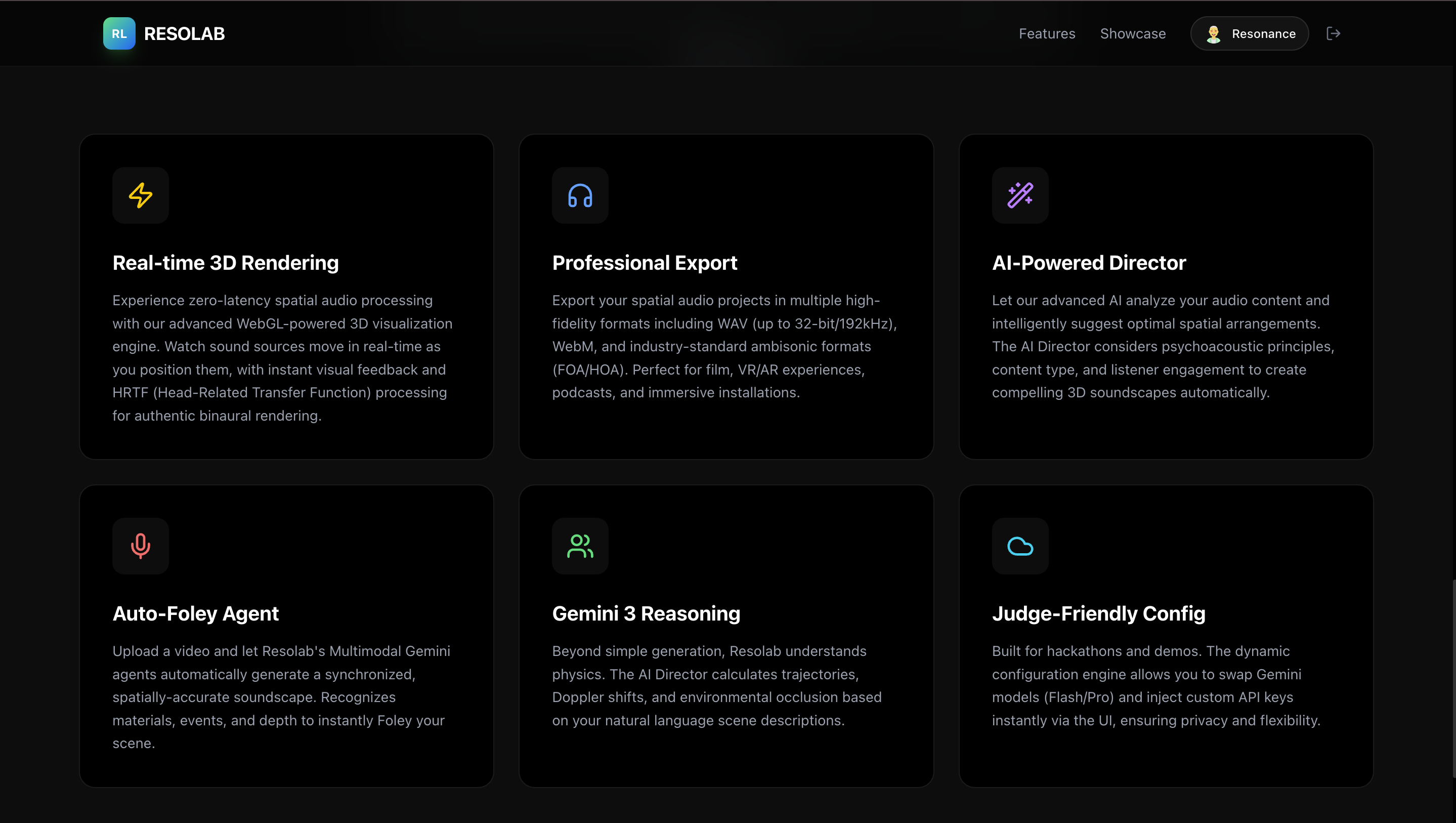
Features
-
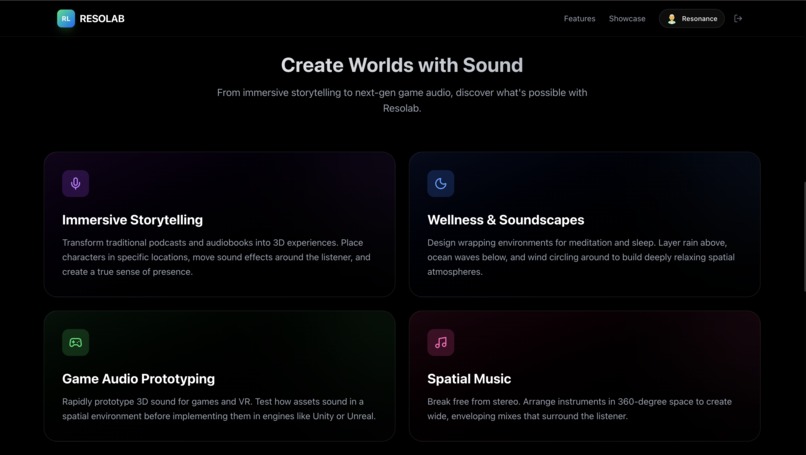
Possible Use-cases
-
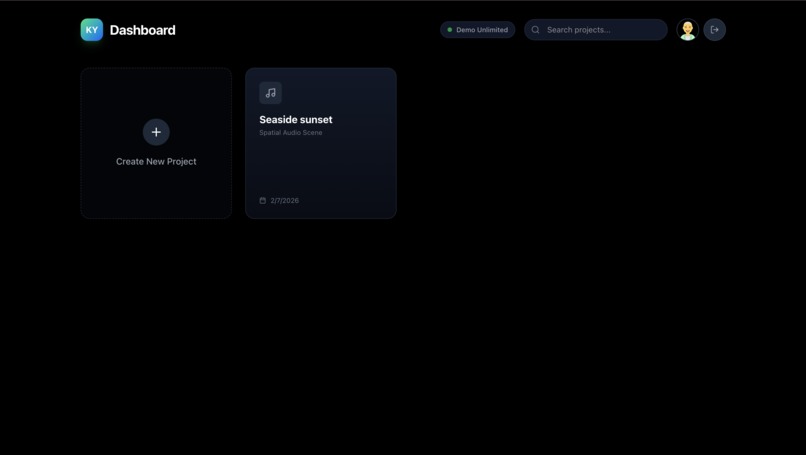
Project Management
-
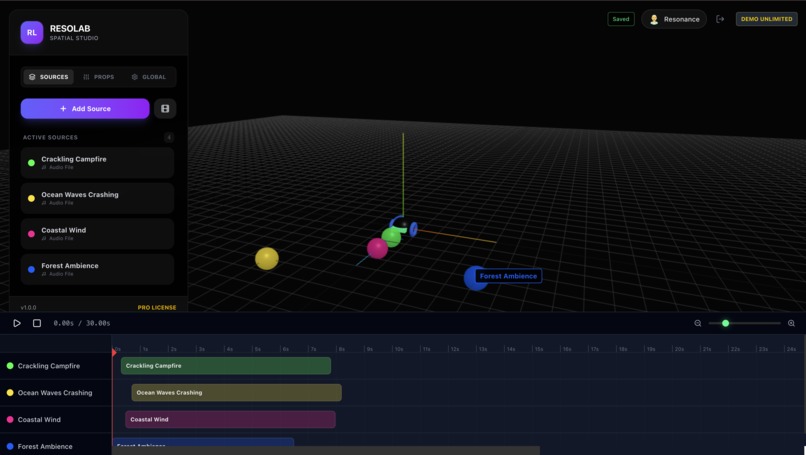
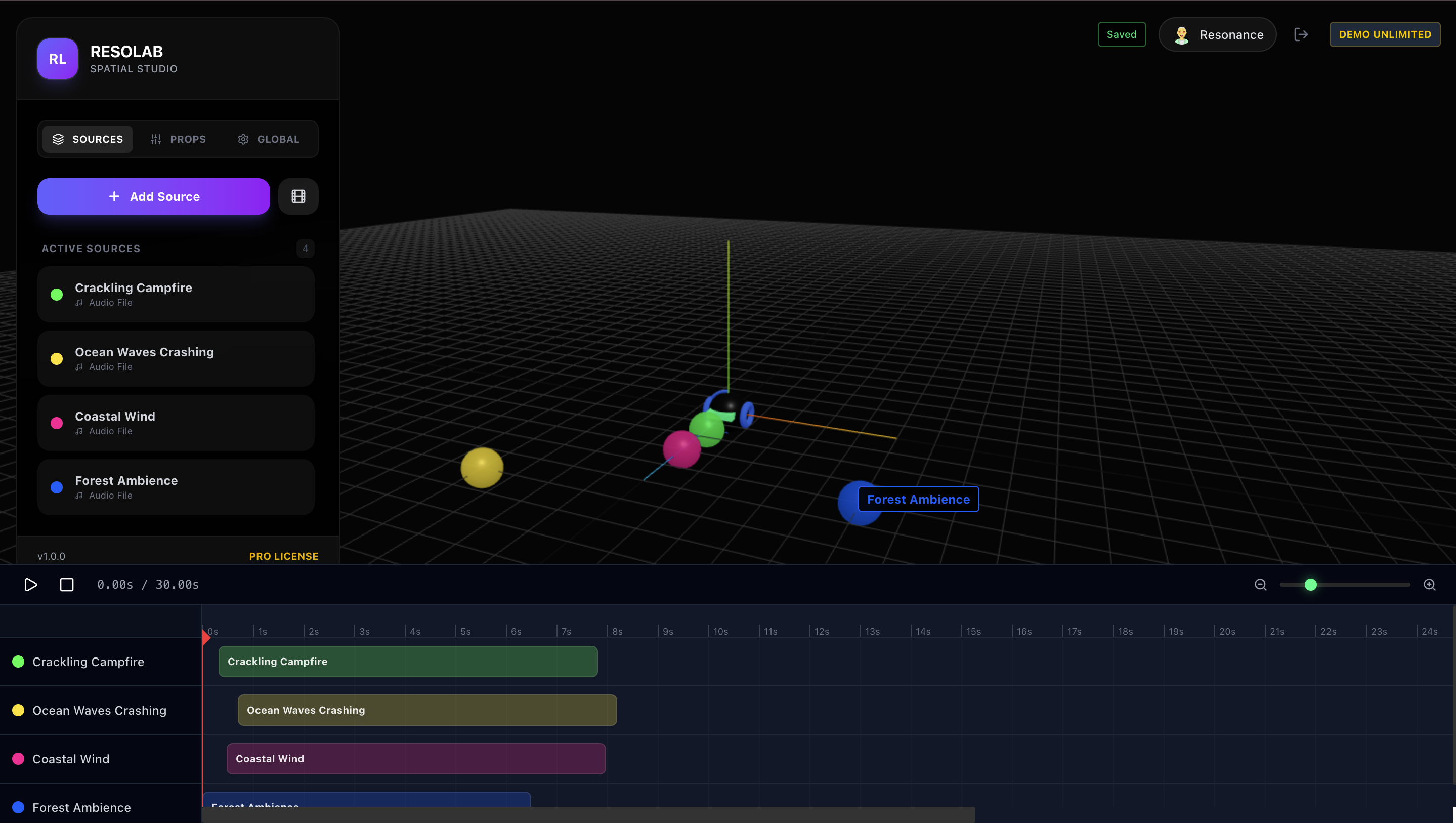
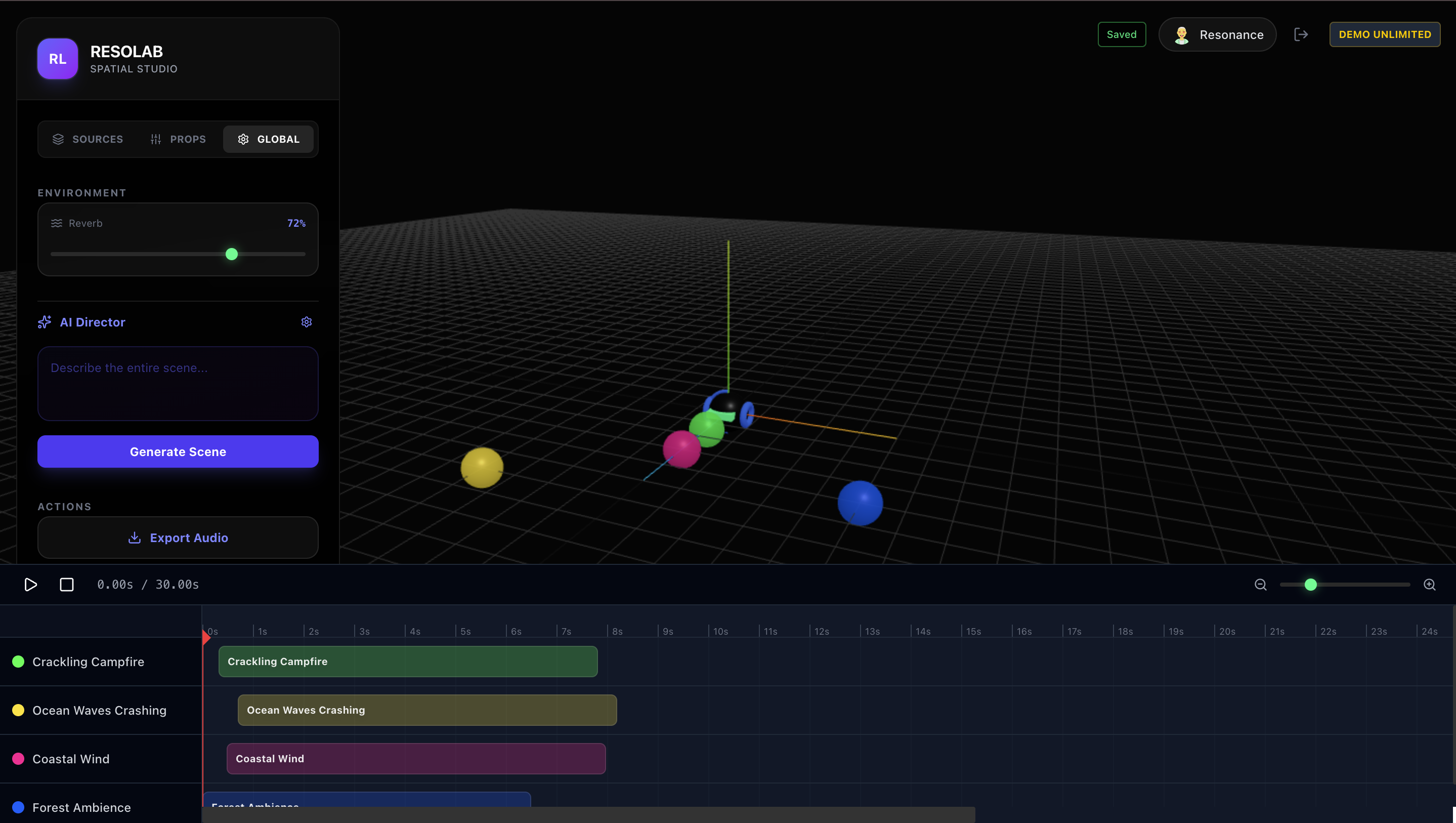
3D scene: On Left side you have list of all object. Towards bottom you have timeline view of each source audio.
-
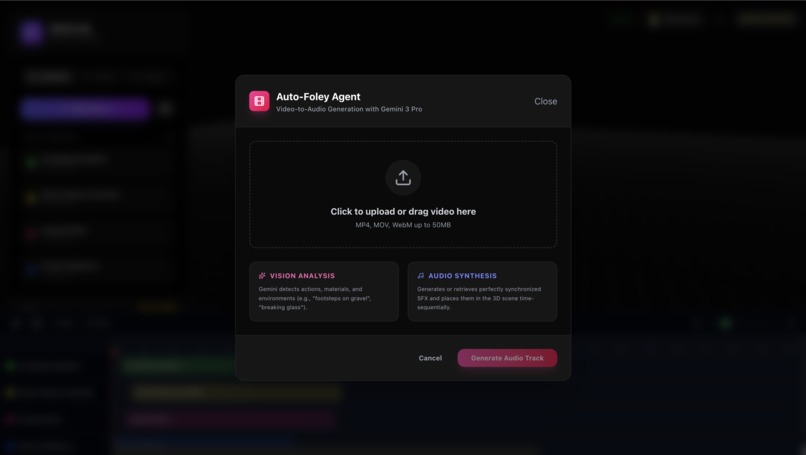
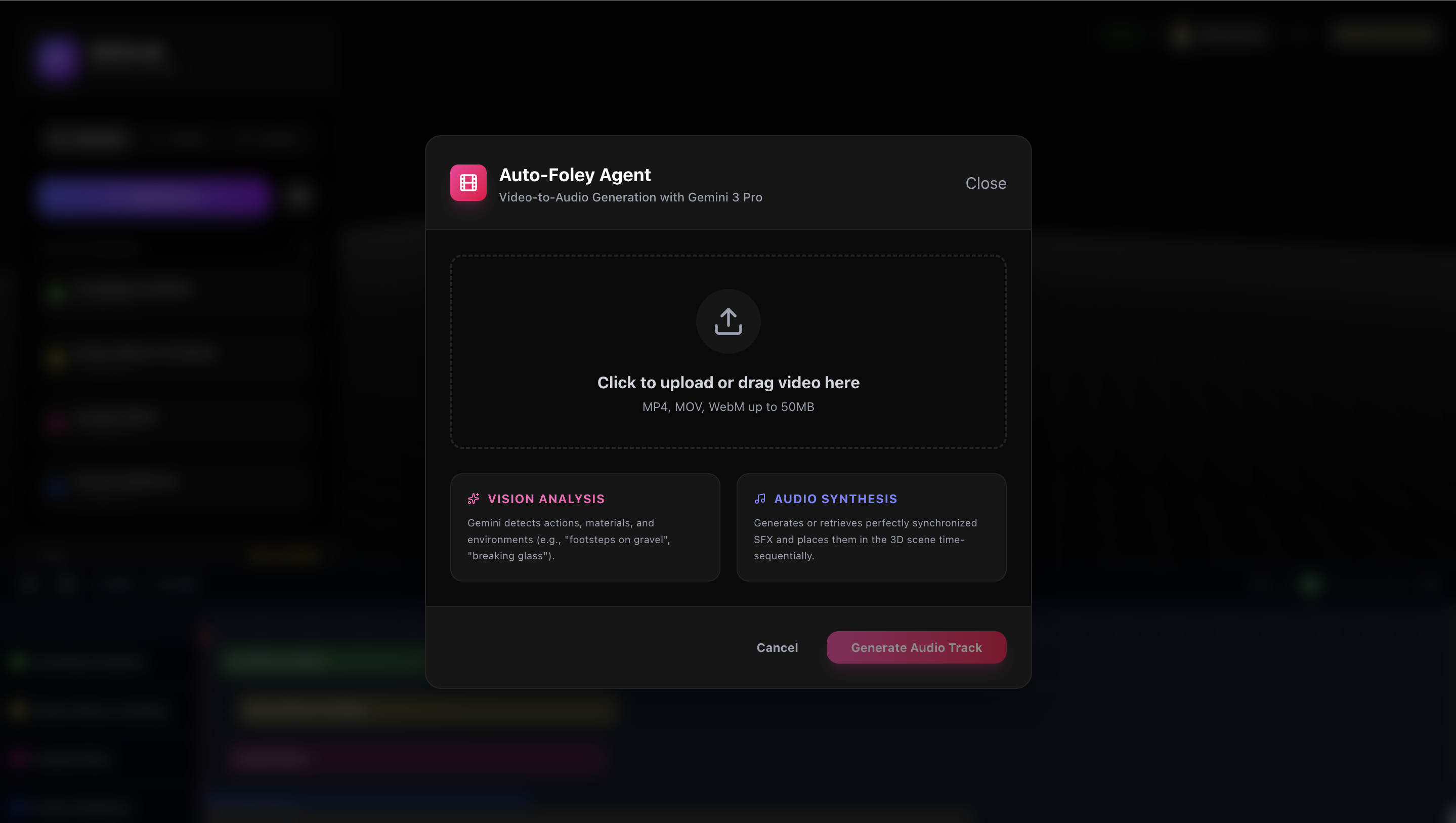
UI to show Auto-foley agent - upload the video.
-
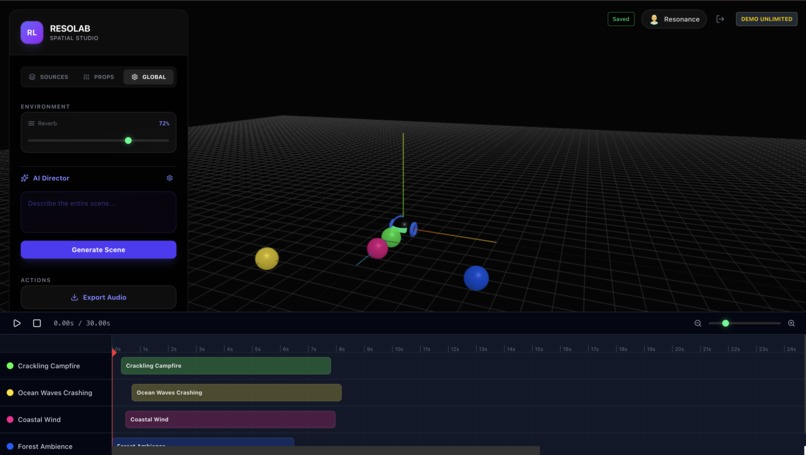
AI Director and Gemini config setter (notice cog symbol besides AI Director)
-
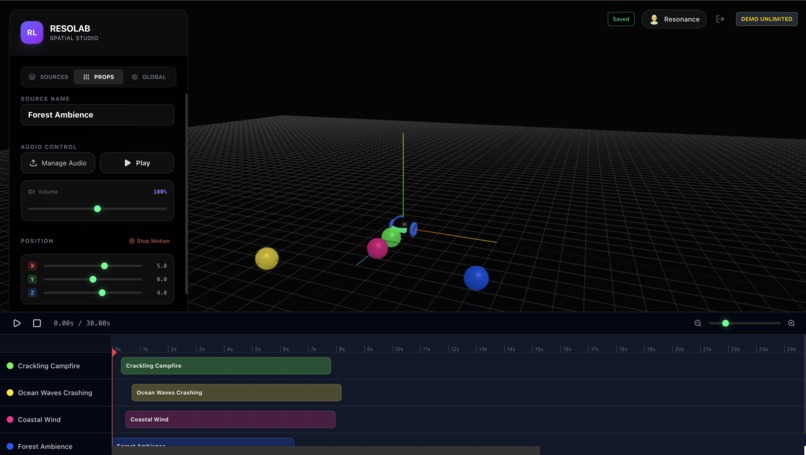
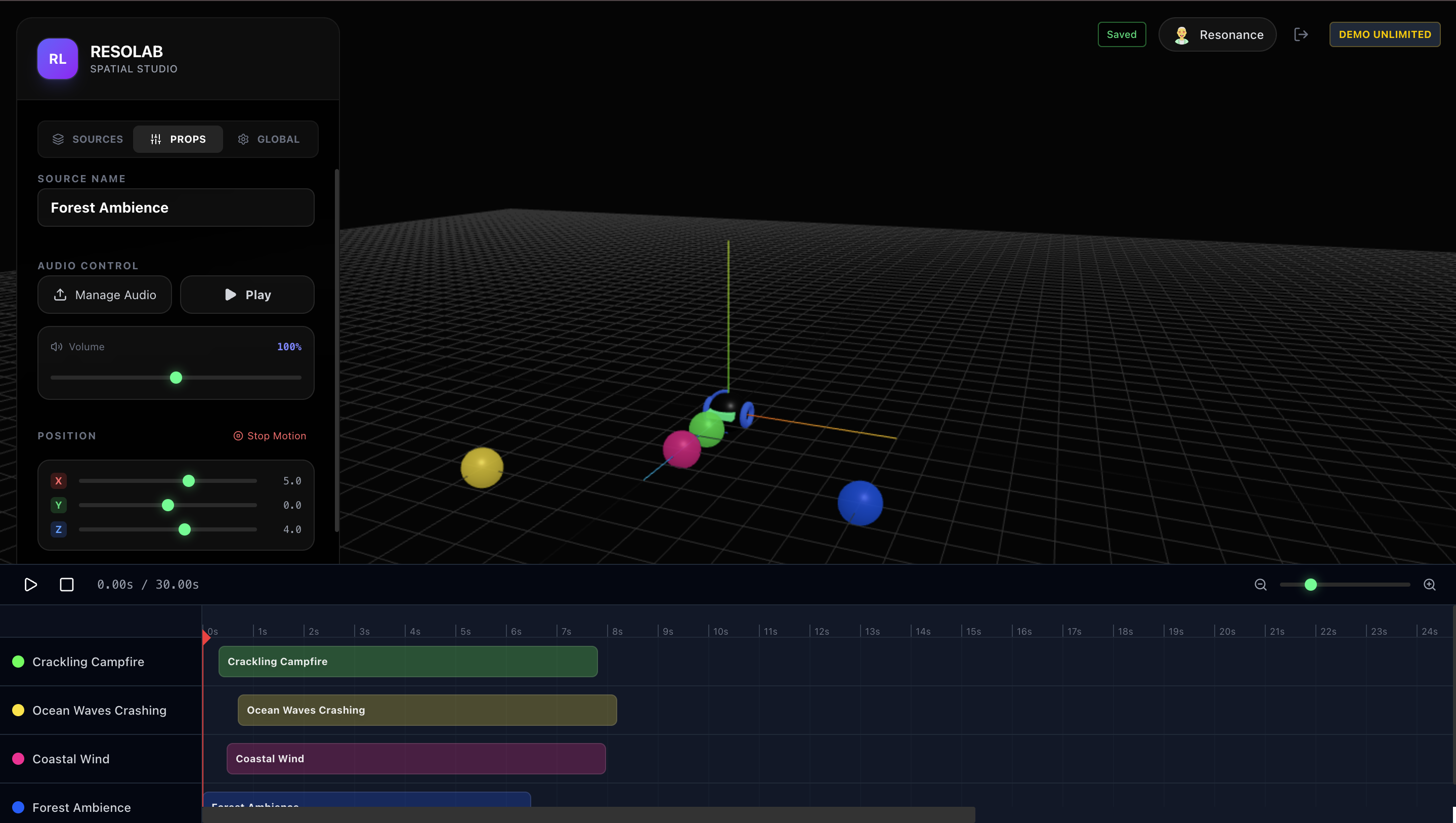
Edit source specific properties like Volume, Position and many more.
-
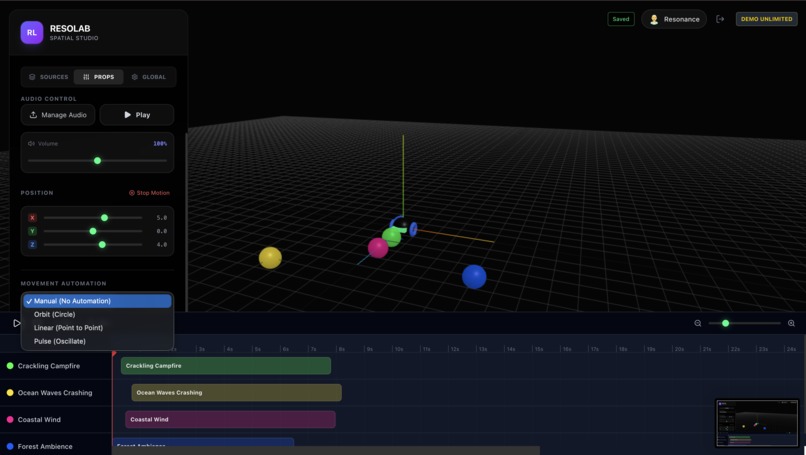
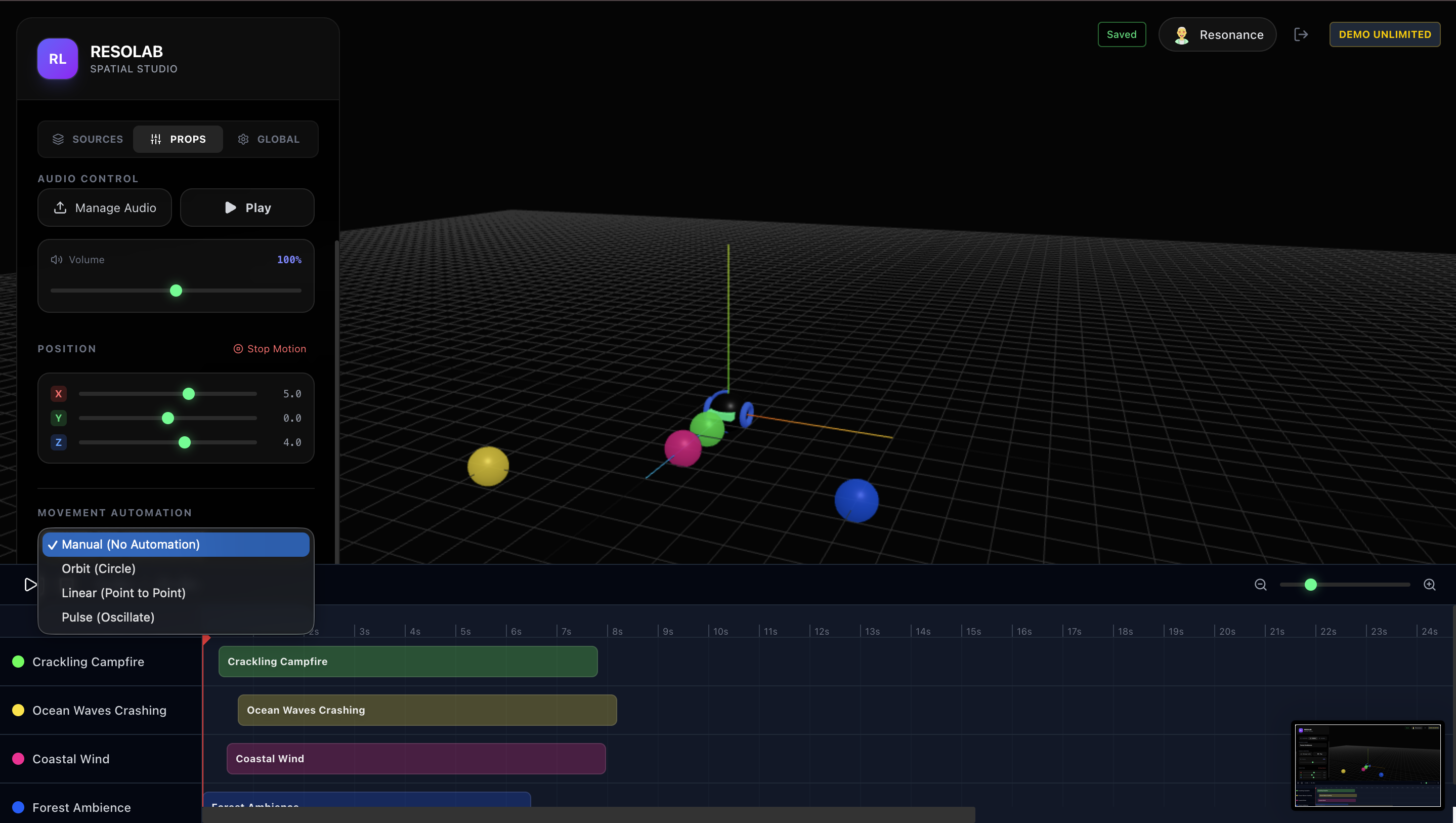
Add trajectories to your sources.
-
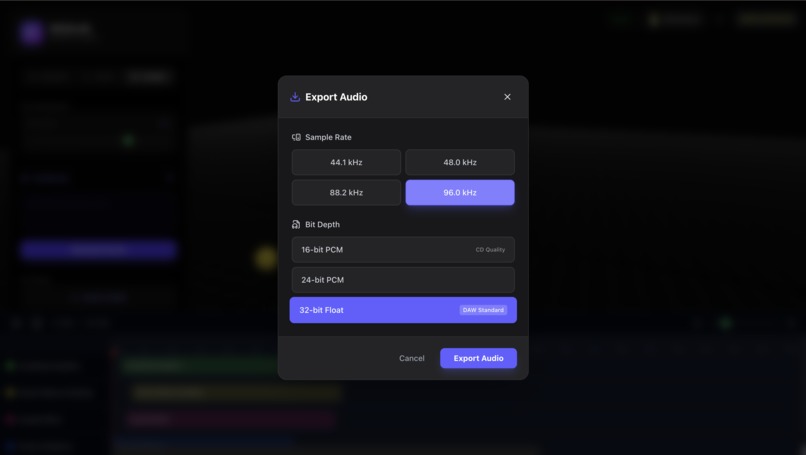
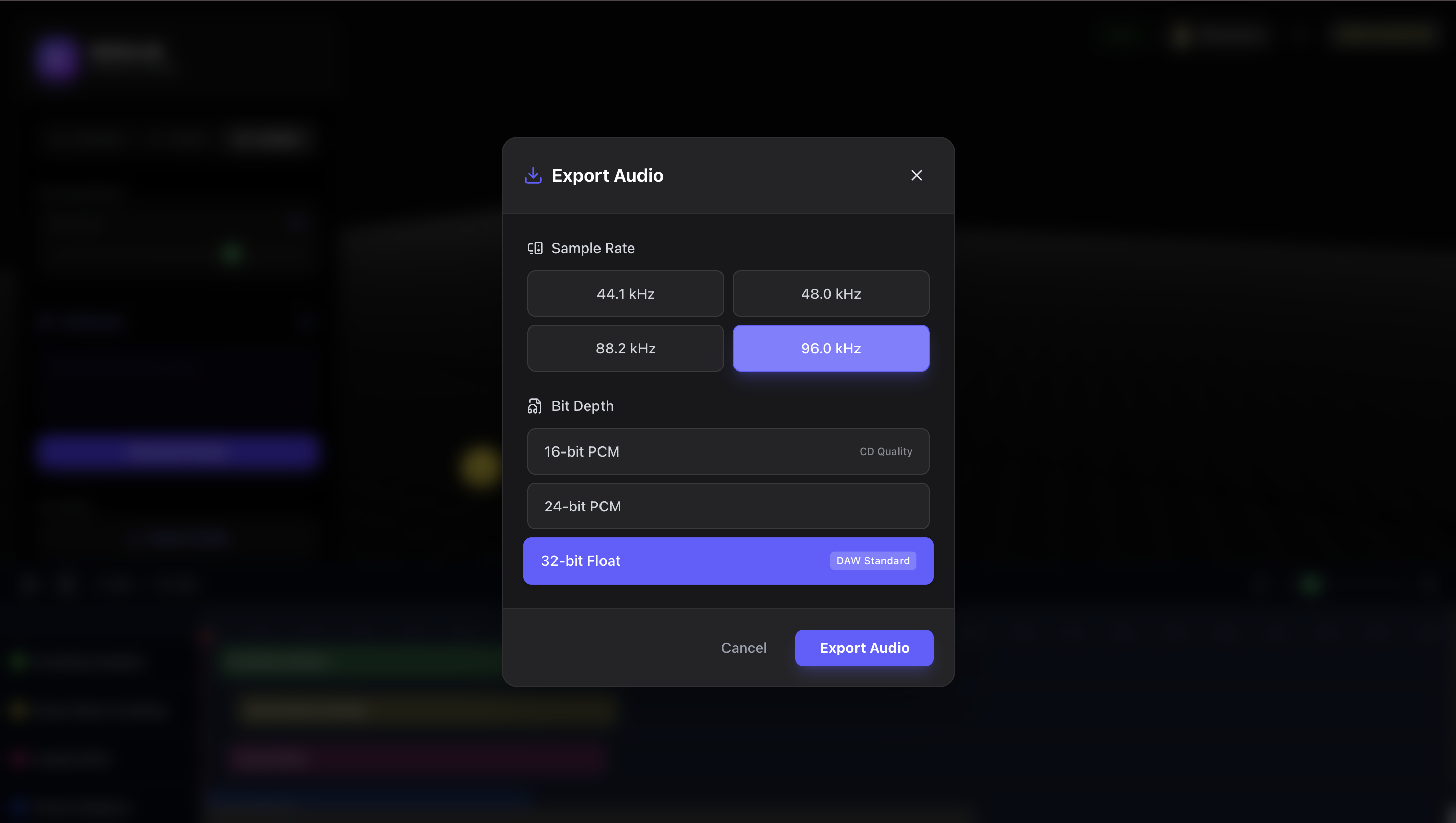
Export high quality audio
Inspiration
The spark for Resolab came from a personal frustration. I tried building a VR game, but the spatial audio tools were prohibitively complex and expensive. I often create content for Instagram using free text-to-video generators, but the results always felt "soulless"—visually impressive but sonically flat. Syncing stock SFX manually was a tedious, hours-long process that drained the creativity out of the workflow. I realized that Google's Gemini 3 possesses an exceptional ability to understand not just what is in a video, but where it is. It can recognize spatial and temporal information—depth, movement, and material physics—better than any previous model. I thought: What if I could just drag a video in, and have an AI "watch" it and populate the 3D soundscape for me? Resolab was born to bridge this gap. It creates immersive, high-quality soundscapes by extracting the "hidden layer" of spatial information from video, reducing hours of manual sync work to seconds of AI processing.
What it does
Resolab is the world's first Browser-Based Digital-Audio-Workstation(DAW) with AI Integration for Multimodal Understanding. It transforms natural language and video into immersive 3D audio environments.
- Auto-Foley (Video-to-Spatial): Users upload a video, and our "Auto-Foley Agent" (Gemini 3) analyzes the visual frames. It identifies events (footsteps, breaking glass, engines), determines their material properties, and—crucially—estimates their 3D coordinates and trajectory relative to the camera POV. It then retrieves or generates the corresponding SFX and places them in the 3D scene, perfectly synchronized.
- Text-to-Scene (AI Director): The AI Director abstracts away the complexity of spatial audio. If a user has a scene but wants to add specific elements, they can simply type "add a bird around my head". Gemini 3 recognizes what "around my head" means spatially, selects the appropriate bird sound, and generates the orbital trajectory automatically—no manual engineering required.
- Creative Freedom: AI created scenes might not soothe your creative pallete, thus Resolab provides you capability to completely customize the scene, by attaching custom sound effects, change trajectories and add more detail to the soundscape.
- Visual DAW: It visualizes sound as 3D objects in a browser-based canvas. Users can grab, move, and animate sound sources intuitively.
- Spatial Export: The engine renders a high-fidelity spatial mix or a multi-channel WAV, ready for VR/AR development or immersive video.
How we built it
Technology Stack
- AI: Google Gemini 3 Flash Preview via Google AI Studio API Keys, Antigravity (Spec-Driven Development with Gemini Agents).
- Frontend: Next.js 16 (App Router), React 19, Tailwind CSS 4.
- 3D / Visuals: Three.js.
- Audio Engine: Native Web Audio API (Oscillators, GainNodes, Panners, Convolvers).
- Backend & Storage: Supabase (PostgreSQL, Auth, Storage).
Architecture
Resolab bridges a reactive UI, a robust 3D scene graph, and a low-latency audio engine.
Sequence Diagram

State diagram

Implementation Highlights
- Semantic Asset Matching: We built a lightweight tag matching engine (
findBestAssetMatch) that maps Gemini's semantic labels (e.g., "gentle breeze") to our internal asset database. It uses a 3-stage fallback system (Exact -> Partial -> Category) to ensure that even vague AI descriptions result in a relevant sound file, minimizing "silent" failures. - Gemini as a Physics Engine: We don't just ask Gemini for text; we ask it for vectors. By few-shot prompting the model with our grid's coordinate system, we turned an LLM into a spatial reasoning engine.
- Persistence Layer: Supabase stores project metadata (preset audio asset library) and large media files (Video), while IndexedDB caches heavy audio buffers locally, ensuring instant playback on project reload.
- Hybrid Upload Strategy: To overcome the 4.5MB Serverless limit, we engineered a "Direct-to-Storage, Stream-to-AI" pipeline. (More details in next section
Challenges we ran into) - The "Zombie" Canvas Fix: We implemented a rigid state-machine lock (
isSceneReady) to prevent race conditions between Repaints and Audio Graph initializations. (More details in next sectionChallenges we ran into)
Challenges we ran into
- The "4.5MB Wall": Our biggest hurdle was handling high-quality user videos. Vercel's serverless functions reject large payloads (FUNCTION_PAYLOAD_TOO_LARGE). We engineered a solution where the client uploads directly to a secure Supabase bucket, and the server agent "polls" this bucket to hand off the URL to Gemini, bypassing the limitation entirely.
- Prompt Engineering Coordinates: Getting an LLM to "hear" in 3D is hard. We had to teach the AI not just what to place, but where. This "Spatial System Prompt" was critical for the AI to understand the user's head position and ears as the origin (0,0,0) and map video depth to our coordinate system, ensuring sounds like "footsteps behind you" were actually placed at
-Z. - Bridging the Semantic Gap: Gemini is creative; our asset library is finite. The AI would often request specific sounds like "vintage 1980s car engine" that we didn't have. We had to build a fuzzy-logic matching engine that could degrade gracefully from specific requests to available categories (e.g., "vintage car" -> "car" -> "Urban Category") to ensure the scene was always populated, even if imperfectly.
- The "Zombie" Canvas: We faced a critical race condition where navigating between projects caused the 3D logic to initialize before the data was ready, leading to "ghost" sources that existed in memory but not on screen. We fixed this by implementing a rigid state-machine lock (
isSceneReady) that gates data injection until the Three.js graph is fully hydrated.
Accomplishments that we're proud of
- Environmental Acoustics (Reverb): We didn't just want "dry" sounds. We implemented a convolution reverb engine using Impulse Responses (IR). When the AI detects a "Cave" or "Hall", it doesn't just change a metadata tag—it swaps the Web Audio
convolverNodebuffer to physically model the acoustic reflections of that space, grounding the generated sounds in reality. - It actually "sees" depth: Watching the Auto-Foley agent accurately place a "footstep" sound further away when a character walks into the distance, and attach a trajectory to it based on the video frame's POV, was a "magic moment."
- First Browser-Based DAW with AI Integration: We built a tool that brings native desktop-grade spatial audio authoring to the web foundary, powered by multimodal AI understanding.
- Real-time Logic: The system feels alive. You type, and seconds later, a scene appears.
What we learned
- Vibe Coding vs. Spec-Driven Development: We learned that "Vibe Coding" is excellent for sprinting to validate ideas quickly, but adopting Spec-Driven Development is the way forward for true AI-native engineering. It is the difference between running a sprint and a marathon—essential for long-term robustness.
- Multimodal is Spatial: LLMs aren't just for text/images. Gemini demonstrated a surprising grasp of 3D space when simply asked to "estimate depth" from a 2D video.
- Audio on the Web is Ready: The Web Audio API combined with React 19 is powerful enough for pro-grade tools, provided you manage the "Imperative vs Declarative" sync carefully.
- World's first digital AI integrated DAW - To the best of my knowledge, Resolab is first of it's kind software that mixes audio with spatial information to create immersive soundscapes.
What's next for Resolab
- Semantic Vector Search: While Resolab's current tag-matching system is effective, I plan to implement Vector Embeddings for our entire audio library. This will allow the AI to find sounds based on "vibe" and acoustic similarity (e.g., matching a "sad piano" request to a specific minor-key sample) rather than just keyword tags.
- Third-Party Sound Libraries: Currently, we rely on a limited open-source sound set. We plan to integrate with massive third-party APIs (like Freesound or Epidemic Sound) to provide users with an infinite palette of high-quality audio assets to tweak and spatialise.
- World-First IAMF Export: Resolab is building the world's first browser-based pipeline for IAMF (Immersive Audio Model and Formats), the revolutionary open standard co-developed by Google and AOMedia. IAMF is the backbone of next-gen spatial audio on YouTube and Android. Resolab democratizes this powerful format, allowing any creator to generate studio-grade, Google-compatible spatial audio mixes directly from their browser, unlocking the full potential of the immersive web for everyone and for all devices including sound bars, car speakers, and mobile.
- XR Engine Bridge: One-click export of scene graphs to Unity and Unreal Engine, allowing game developers to "prompt" a level's audio and drop it directly into their game world.
- Collaborative Logic: Multiplayer sessions where a Director (AI) and a Sound Designer (Human) can co-create deeply interactive audio logic in real-time.
Built With
- antigravity
- google-gemini
- nextjs
- react
- supabase
- tailwind
- three.js
- typescript
- web-audio-api
Log in or sign up for Devpost to join the conversation.