-
-
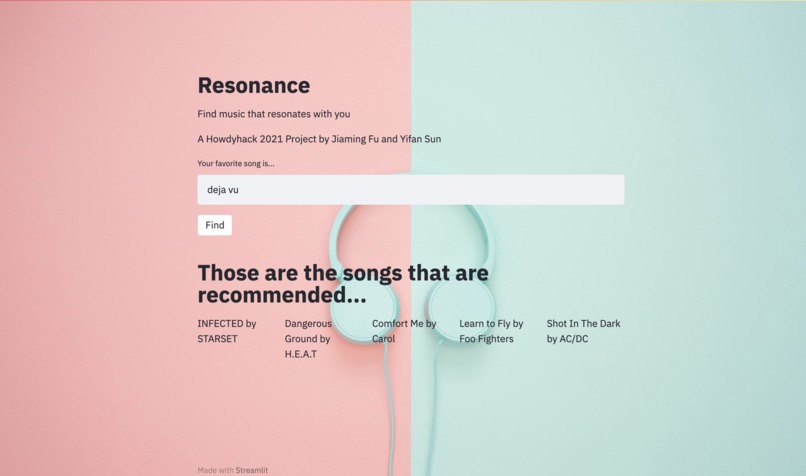
Web Application snippet
-
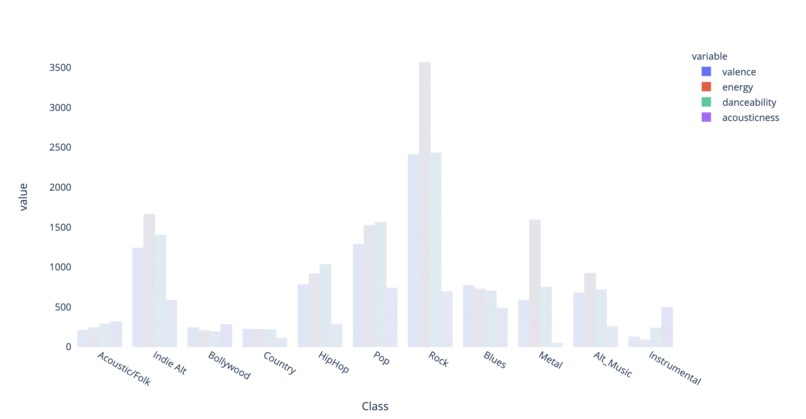
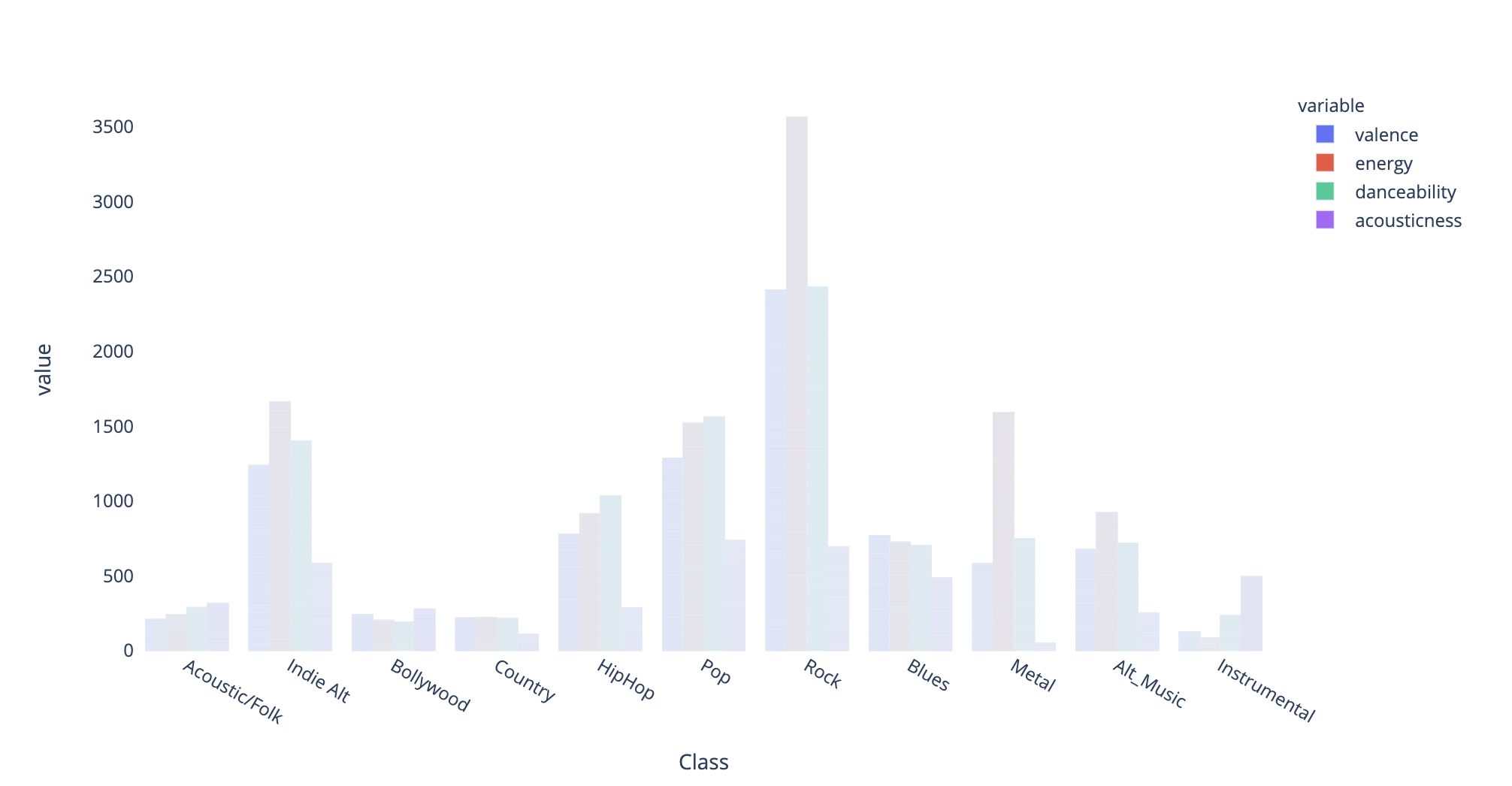
Characteristics for each genre
-
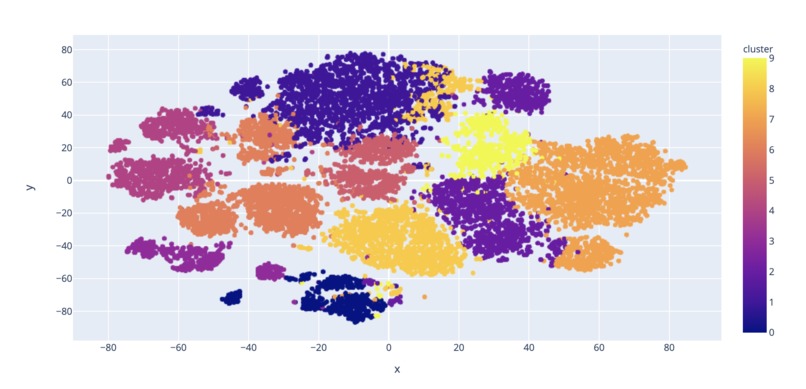
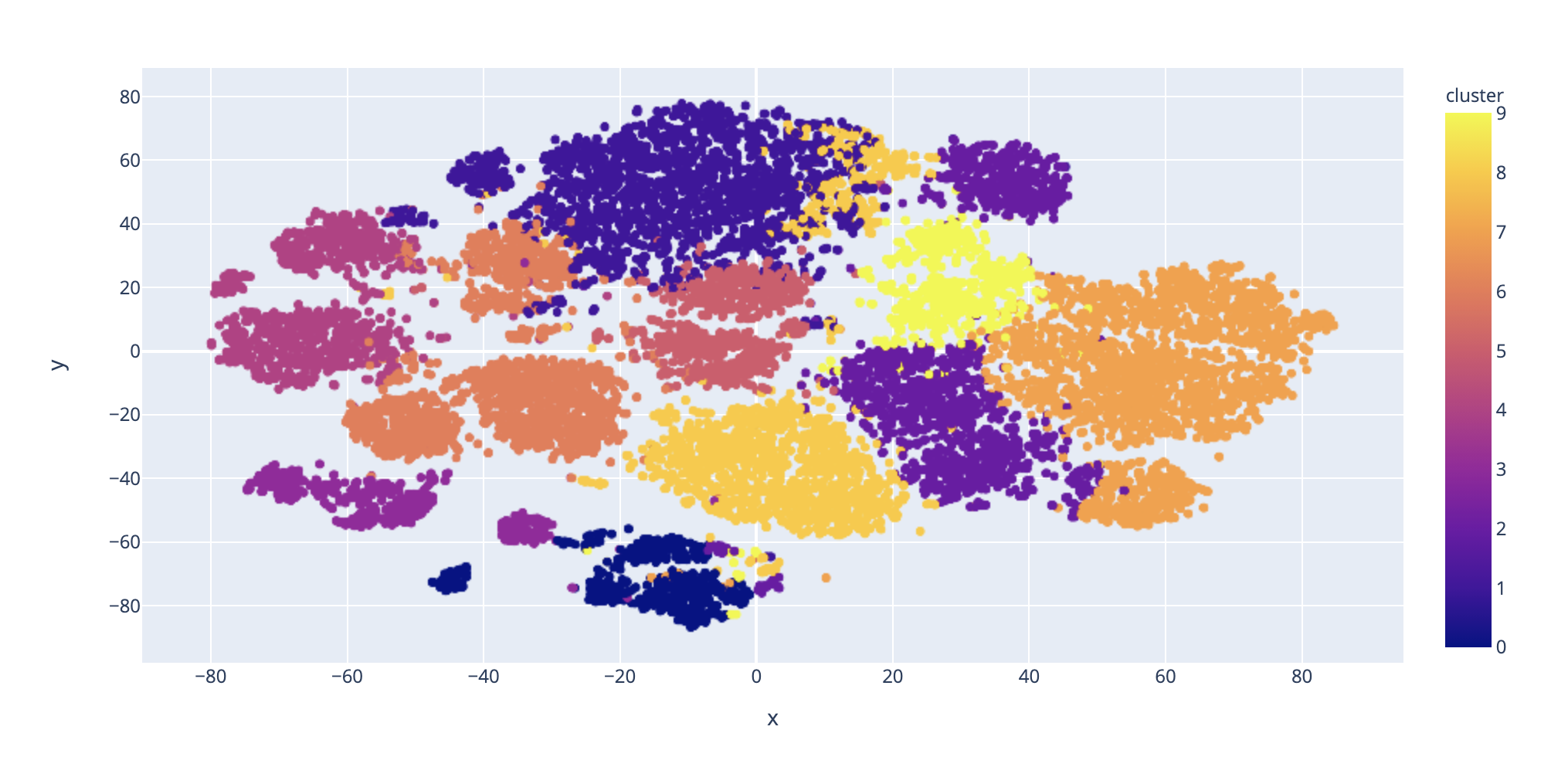
Clustering model with PCR
Inspiration
Do you have a song you love so much that you put it on repeat for days? Do you have a melody stuck in your head no matter what you do? Currently, many powerful music recommendation algorithms run in popular software like Spotify and Youtube music. From our research and experience, these algorithms emphasize the weight of popularity, genre, and the artist. While these provide good recommendations across the board, we wanted something different. Something more focused on the qualities of the music itself. This inspired us to build our music recommendation app: Resonance.
What it does
Resonance is a cluster-based Machine learning web app that recommends music based on musical features such as tempo, energy, danceability, and loudness. The app asks the user to input a song name and search for that song in our database. If our database does not contain the specific song, it will notify the user and ask for new input. In the case that the song is found, our algorithm locates the cluster that the song belongs to and fits the recommendation model to it to identify the five closest neighbors within the same cluster. It returns these five songs as recommendations to the user.
How we built it
After the pre-processing of data including standardizing track names and removing duplicates and songs with incomplete information, we first visualized the feature correlations by setting popularity as the dependent variable and produced a bar graph to make sure all the feature variables are meaningful to the song. Then we calculated the mean values of valence, energy, danceability, and acousticness for each genre label and produced a grouped bar graph to prove that each genre has its own characteristics because they all differ by a lot. After that, we trained a clustering model based on all the features of the songs and used Principal Component Analysis to plot the result in two dimensions. This gave us a clear pattern for close clusters that confirmed the hypothesis that songs with the same genre have similar characteristics. By using the clustering model, we further created a recommendation model that took the input of one song from the frontend, recommended five songs that are the most similar to it within the same cluster, and printed it on the frontend.
Challenges we ran into
The first challenge we encountered was to find a suitable dataset for our clustering and recommendation models. Finding such a dataset was challenging since clustering and recommendation models both need a substantial amount of data to make meaningful implications. In the beginning, we wanted to utilize the Spotify API, Spotipy, to provide us with quality data of musical features. However, there were no playlists of sufficient size on Spotify that we could make use of. Luckily, we ended up finding a pre-built dataset on Kaggle that contains more than 15k songs.
However, the dataset was very fragmented: it had many missing values for the musical features, and the track names were formatted differently among themselves (e.g. feat artist names in parentheses or dashes, track names in a different language that show up as corrupted characters). For the missing features, we filled in zeros for the rows that were computed to have a correlation. Moreover, we standardized the format for track names and deleted the rows with the corrupted characters. At the start, we tried to make use of the corrupted data, but it turned out that they are simply unreadable and need to be removed.
For the most technical part of the project, we were not very experienced with machine learning, especially the recommendation model and the theoretical part of it. We spent a long time learning these concepts by watching tutoring videos and reading the documentation of the Python sklearn library. After a frustrating amount of trial and error, we finally found the most suitable clustering algorithm and recommender system that produced the best performance.
Lastly, the biggest challenge we ran into was to connect the backend to our frontend. Since my teammate and I had no previous experience with frontend, we tried to learn many different frontend frameworks including Flask, React, HTML, CSS. These efforts yielded no usable results. Fortunately, we came across the Python Streamlit library to write the frontend. Using Streamlit, connecting user input and outputting with our backend model was much easier (since both are written in Python).
Accomplishments that we're proud of
We built very complex machine learning models with little prior knowledge about their theories and implementations. We also built a decent frontend web application without any prior knowledge about frontend. And most importantly, we were able to put together a project that addresses a need and helps people find new music that they might love.
What we learned
We learned how to quickly utilize a tool or language that we’ve never seen before and put them altogether into the project. We also learned how to implement a clustering and a recommendation model, as well as the basics of frontend development. Most importantly, we learned not to fear new technologies unfamiliar to us beforehand. When tackling projects, we all have a tendency to stick to familiar technology that we have used in class/other projects. However, the cost of staying in your comfort zone is that the programming language you use might not be best suited for the task. While attending the career fair last week, we noticed that every company uses some different technology and it is very hard to have everything on your toolbelt. Instead, we should be versatile and always willing to learn new technologies to respond to the needs of the situation.
What's next for Resonance
Currently, the biggest limitation to Resonance is that it relies solely on its own database. While the database does contain 15k+ songs and includes recently released (2021) songs, it will quickly be outdated as more new music gets released. Also, we currently only have English songs, which is only a small amount of the global music market. One potential solution is to utilize Spotify’s huge and dynamic online database. When the user inputs a song name, we can search for it on Spotify and extract its features using Spotify web APIs instead of searching for it in our local data. This gives us virtually unlimited songs to ensure that the user has the best experience with Resonance.
Furthermore, we could also store the user input songs with his or her login credentials that link to a database, tag all the songs the user enters with preference numbers according to the number of times the song is listened to, and based on the user input history, we will recommend songs that are in the same clusters as the ones with the highest preference.
Built With
- clustering
- machine-learning
- matplotlib
- numpy
- pandas
- plotly
- python
- sklearn
- streamlit




Log in or sign up for Devpost to join the conversation.