-
-
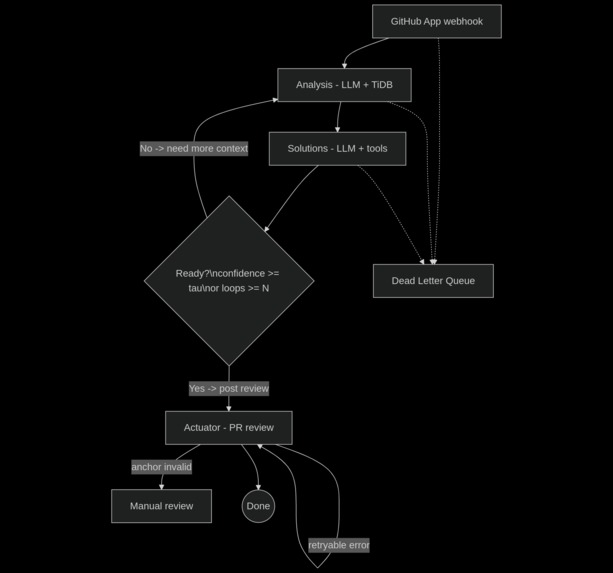
How ResolvCI thinks
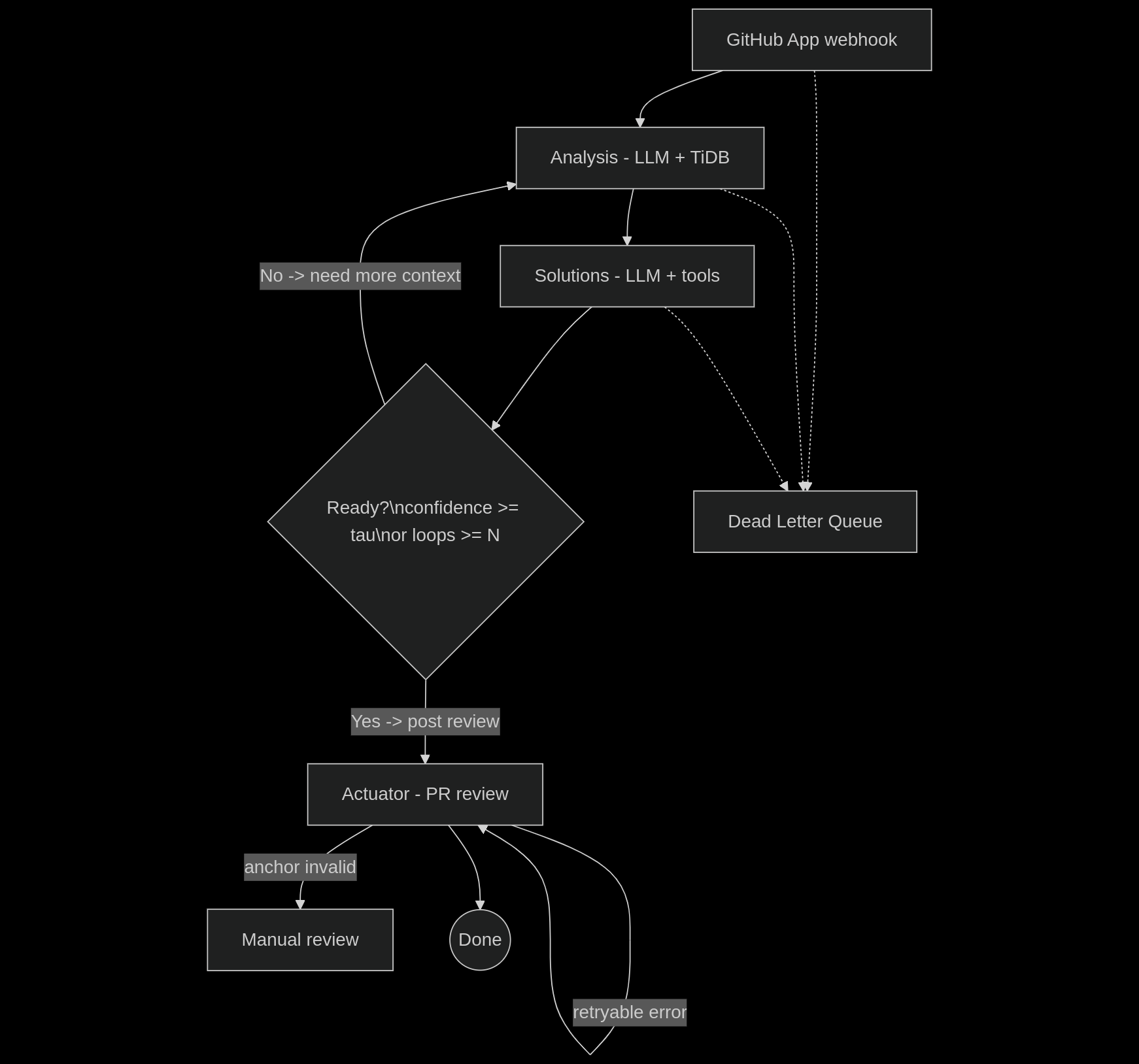
Inspiration
CI failures waste hours: scrolling logs, hunting the right file/line, and writing the same tiny fixes by hand.
I wanted “mean-time-to-green” to be minutes, not half a day — especially for small but blocking mistakes in PRs. I've always thought it would be nice to have the reason for a build failure, the files where the error occurred and fix suggestion before looking at the logs
What it does
ResolvCI integrates with GitHub to ingest failed CI check-run logs into TiDB Serverless, perform hybrid retrieval (exact + semantic), and invoke OpenAI’s GPT-4o-mini to generate inline PR suggestions and concise diagnostic summaries that highlight the affected files. It then uses the GitHub API to post fixes as review comments you can commit directly from the PR. Diagnostic summaries appear as PR comments with permalinks to the failing files.
Diagnoses CI failures from log tails and PR context.
Proposes minimal, safe fixes limited to files actually changed in the PR.
Anchors suggestions to the correct line using match hints (exact text/regex) + PR diff hunks + fuzzy matching.
Outputs review-ready comments with Current and Proposed blocks and (when safe) inline suggestion patches.
Policy-gated automation: only posts auto-apply suggestions when risk is low and model confidence clears a threshold.
How I built it
ResolvCI mirrors the classic control-systems pattern:
Sensor/Ingestion → observes the world (webhook + logs)
Controller/Analysis & Solutions → thinks and decides what should happen
Actuator → performs the side-effect in the world
In our case, “the world” is GitHub.
GitHub App (Ingestion Agent) Event-driven and ambient: subscribes to GitHub check_run webhooks; on failure (completed with conclusion: failure), it launches our LangGraph workflow. Verifies HMAC, de-duplicates deliveries, pulls workflow logs, computes stable error signatures and a normalized tail, and upserts a row of
build_failuresin TiDB.Analysis Agent (grounded retrieval) Uses an LLM to structure the failure (error class, hints, keywords), then runs
hybrid retrieval(exact+ semantic)in TiDB.Solutions Agent (autonomous + tools, read-only) Reasons over logs/history and invokes tools to get missing context:
- Tools:
list_pr_files·fetch_slice·code_search - Validates / dry-runs patches, classifies outputs, and returns a strict JSON contract (summary, changes, policy).
- Tools:
Actuator Agent (Reviewer, exactly-once) Converts results into a single PR Review:
- 💡 Suggested fix: inline
suggestionblocks (only for valid, low-risk patches) - 🔎 Source of error: diagnostic (no code change) with snippet + permalink Uses an outbox table for exactly-once delivery and retries.
- 💡 Suggested fix: inline
Non-linear loops (Insight Loop) Solutions may request more context (fetch slices, search symbols), loop back to Analysis, and continue until τ (confidence) or budget limits are met.
LLM orchestration with LangGraph
Coordinates multi-step agent workflows. The Solutions Agent invoke repo-aware tools:
list_pr_files— List files changed in a pull request with unified diff patches to anchor suggestions.fetch_slice— Fetch a specific line range from a file at a given ref (HEAD SHA). Keep payloads small.code_search— GitHub code search within the repo (symbols, keys, workflows). Usefetch_sliceafterwards for validation.
I choose LangGraph for ResolvCI because it provides robust state management, tool routing, and multi-step workflows—ideal for agentic systems. The LLM dynamically invokes repo-aware tools to inspect context and propose precise fixes: LangGraph coordinates these calls end-to-end, enabling reliable analysis and fix/diagnostics generation
Structured contract via Zod schemas (SolutionsSchema, ChangeSchema, MatchSchema) to keep outputs deterministic.
TiDB Auto-Embedding
TiDB Auto-Embedding powers ResolvCI’s hybrid retrieval over build failures: exact search via normalized error signatures, plus semantic search over log tails and prior fixes using TiDB Cloud’s tidbcloud_free/amazon/titan-embed-text-v2. It indexes failure logs and agent-generated fix_recommendations for fast vector search across past errors and fixes.
Model: GPT-4o-mini (OpenAI) is the LLM backing all agent workflows.
Guardrails & budgets: - Tool call count/time caps, per-tool budgets; - Confidence threshold (TAU) + risk level to decide between inline suggestions vs. comment-only hints.
TypeScript + Node with a GitHub App (Octokit) for repo/PR access.
Challenges I ran into
- Determinism over nondeterminism. Making an agent that relies on non-deterministic LLMs behave deterministically was the biggest hurdle. Code fixes must be predictable; early on, the same failure sometimes yielded different patches.
What I did to stabilize outputs:
- Structured I/O contracts with Zod (strict schemas, defaults) to constrain variation.
- Canonicalization of text (normalize whitespace/line endings, strip fences) so comparisons and anchors are idempotent.
- Anchor rules that don’t depend on model whim
- Policy gating & no-op detection so identical proposals don’t become “fixes.”
- Tool budgets & sequencing plus temperature 0 to reduce stochastic branches.
Accomplishments that I am proud of
- Deterministic, review-friendly output that reviewers can trust: minimal diffs, precise anchors, clear intent.
- Robust anchoring combining hints + diff hunks + fuzzy search, resilient to whitespace and small shifts.
- Safe-by-default policy that prevents overeager auto-patching.
- Tight tool budget loop with reliable tool call accounting and safety-net replies.
What I learned
- Prompting alone isn’t enough — schema + validators + post-processing are essential for reliability.
What's next for ResolvCI
- Deeper code context: semantic search over repo slices with caching to reduce tool calls and latency.
- Patch simulation: dry-run apply & compile/test in a sandbox to raise confidence before posting suggestions.
- Learning loop: incorporate reviewer feedback (accepted/rejected suggestions) to tune risk/intent heuristics.
TiDB Cloud Account
Built With
- langgraph
- nextjs
- tidb
- typescript


Log in or sign up for Devpost to join the conversation.