-
-
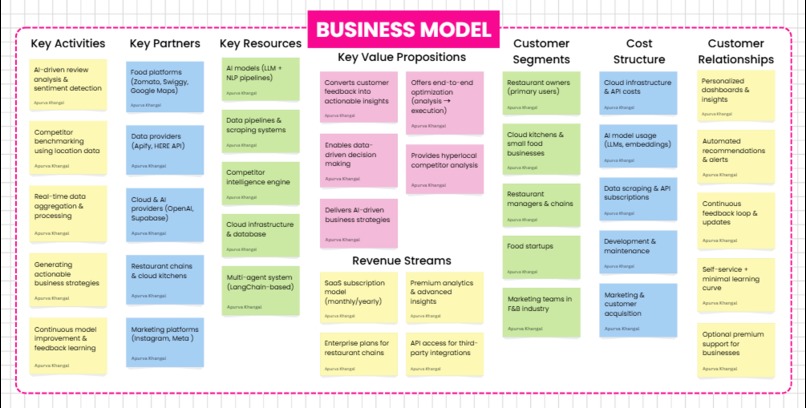
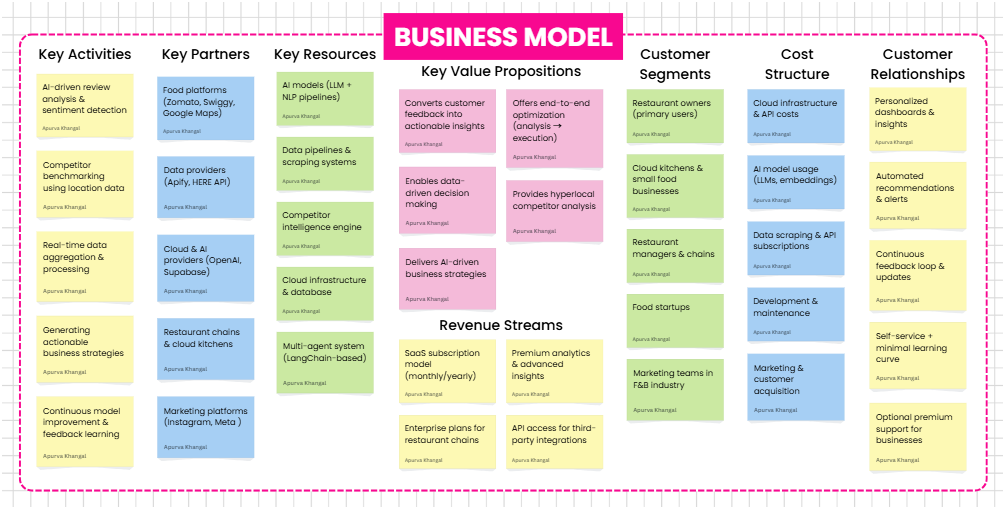
Business Model
-
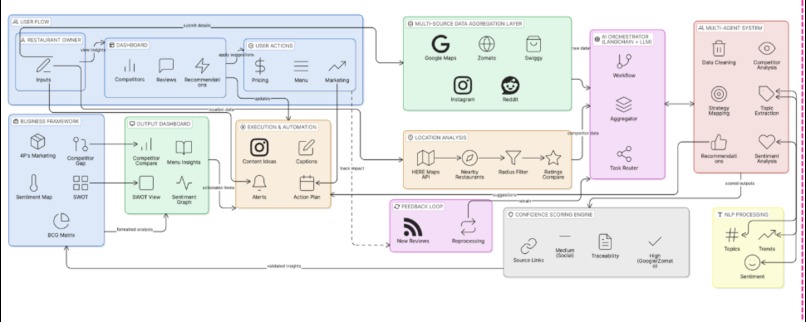
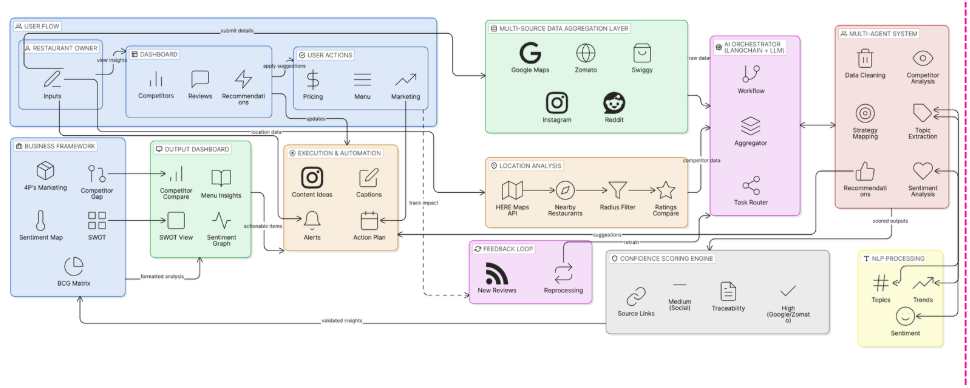
System Architecture
-
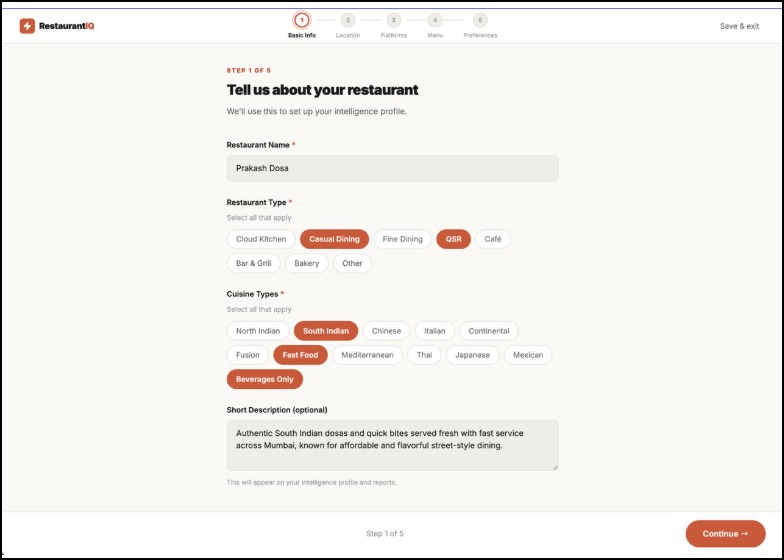
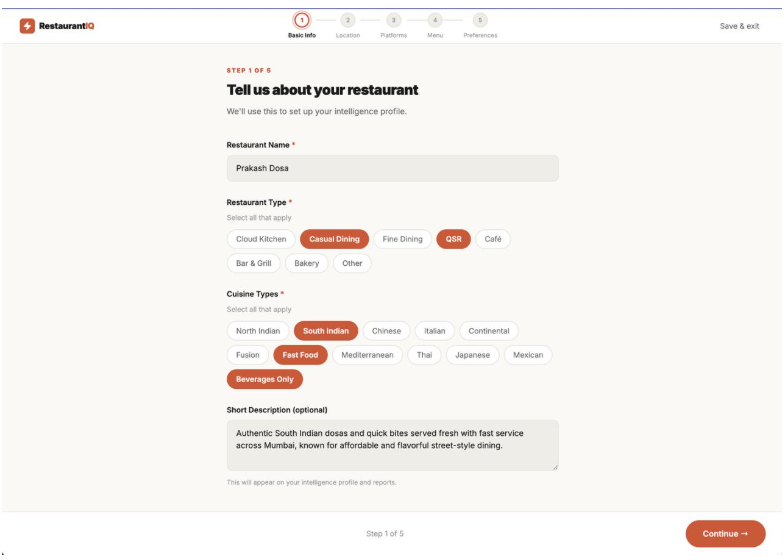
Customizing Profile to Suit Your Needs
-
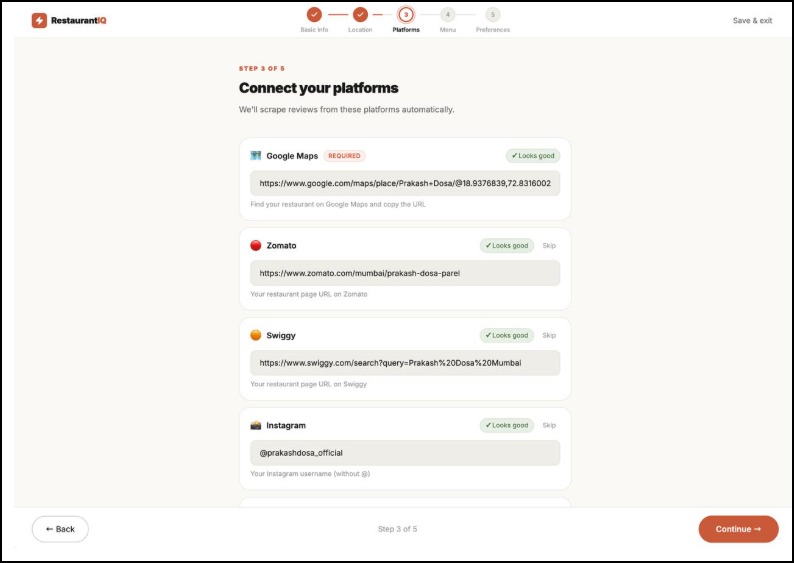
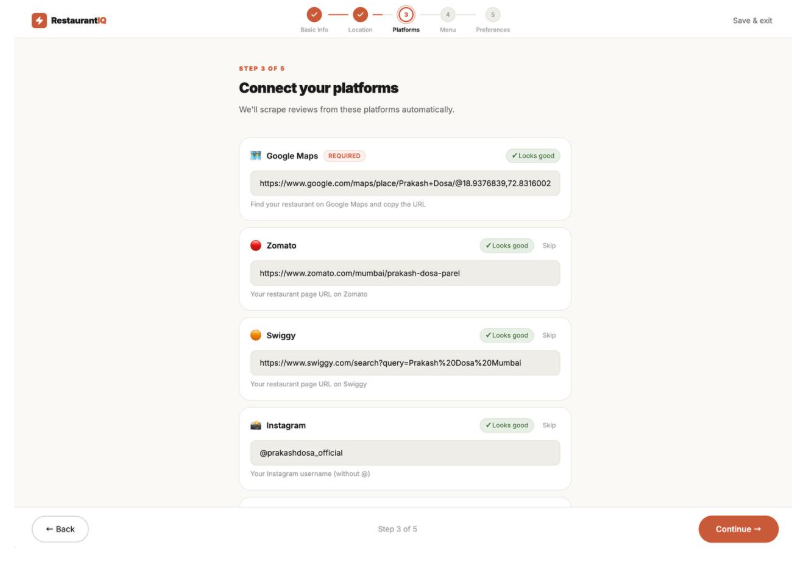
Connecting The Platforms for automation
-
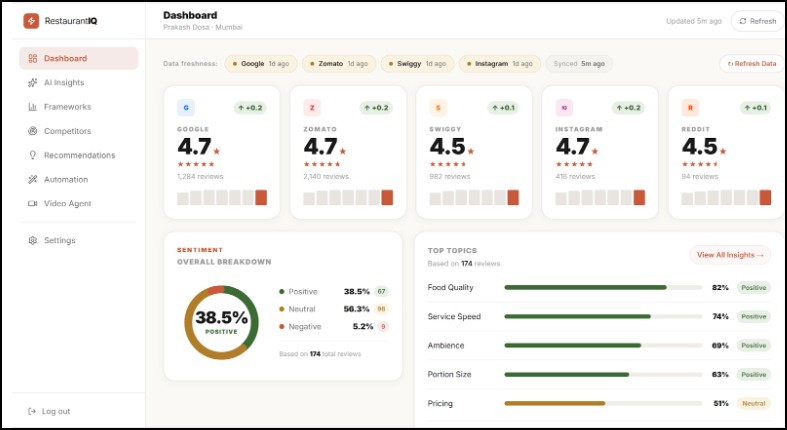
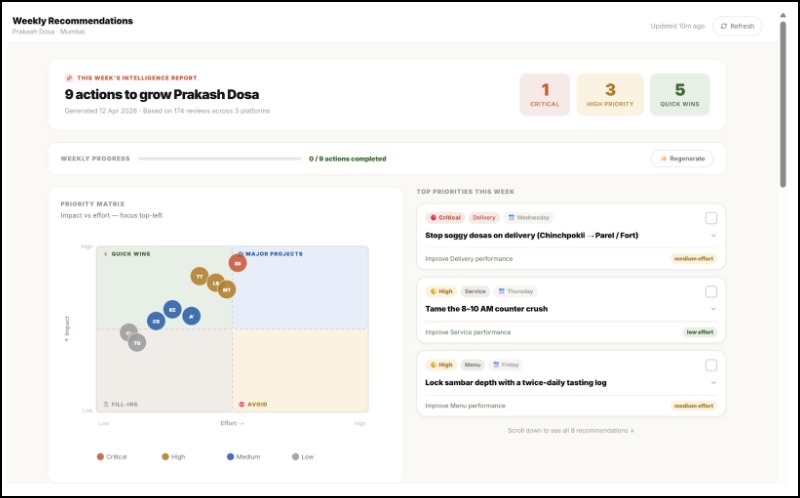
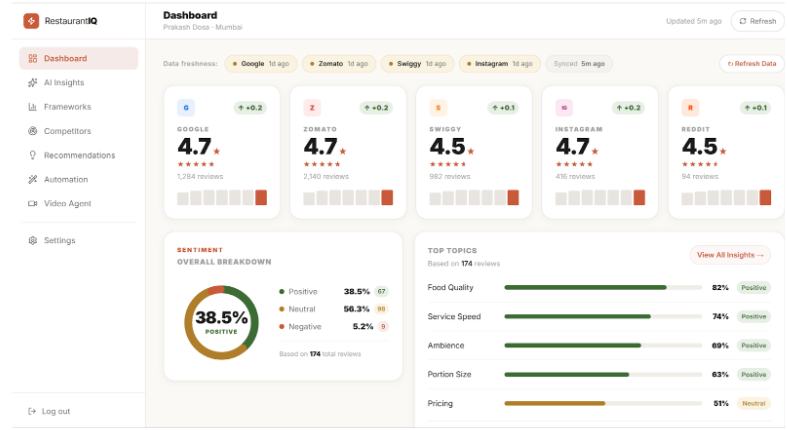
Customized Dashboard for Marketing Analysis
-
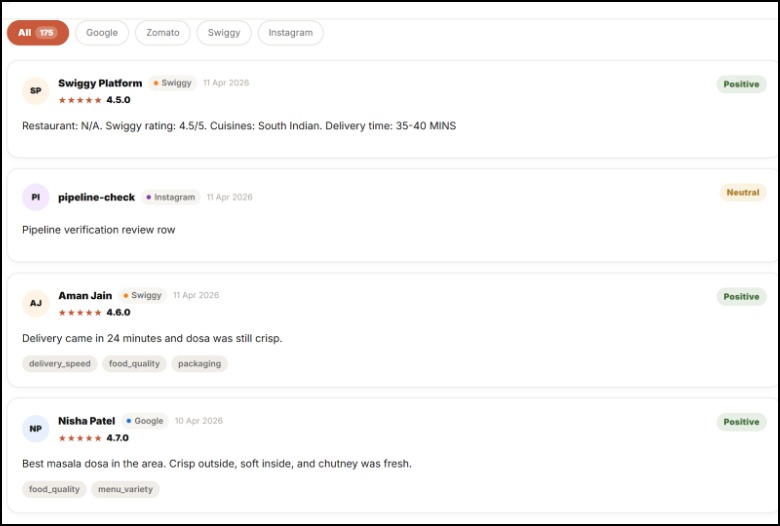
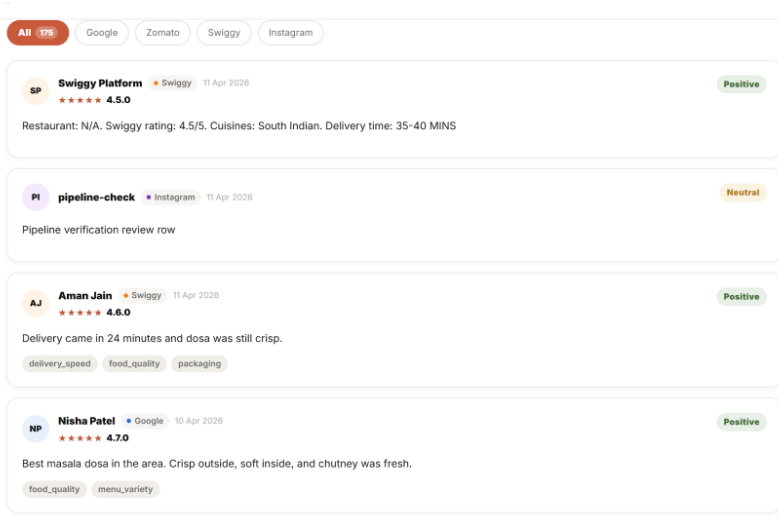
Customer Reviews for your restaurant
-
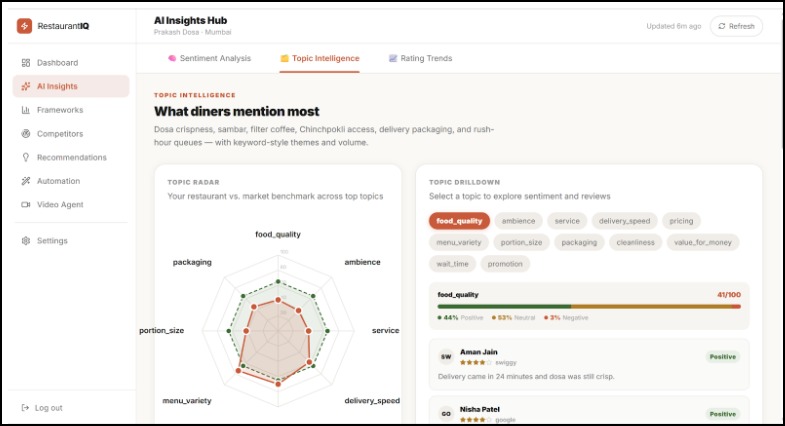
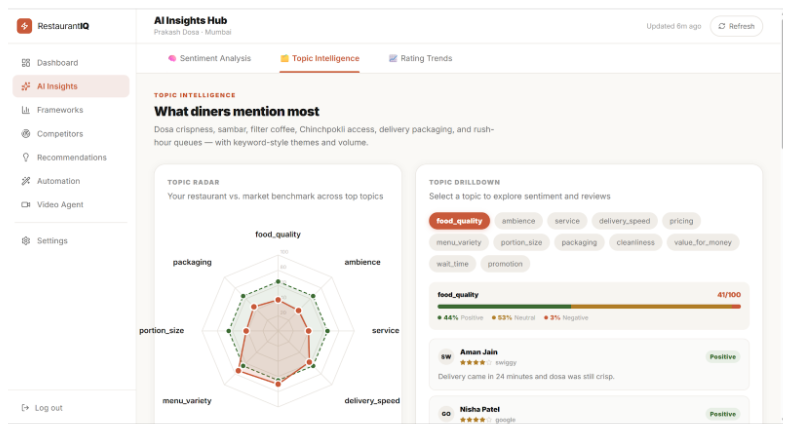
AI Analysis
-
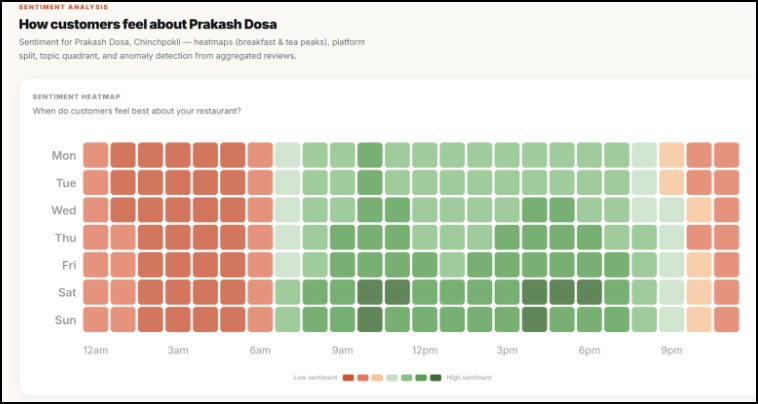
Customer Feedback
-
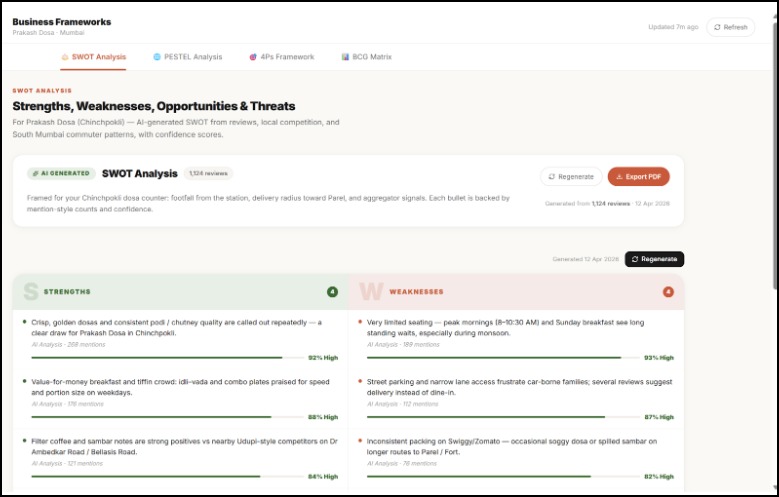
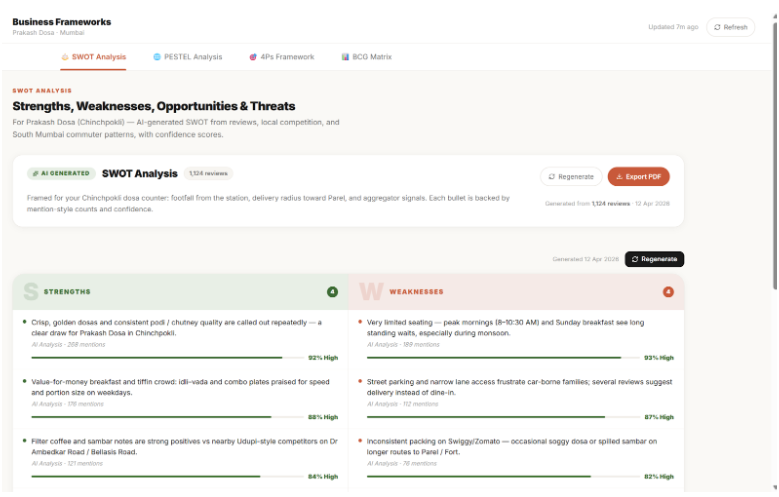
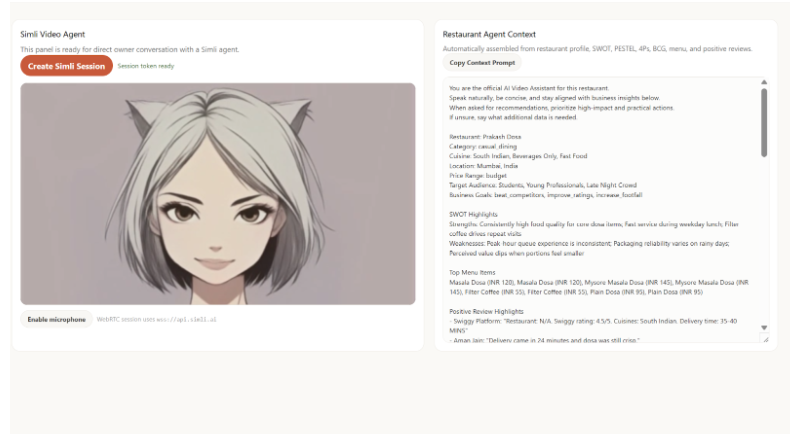
SWOT Analysis
-
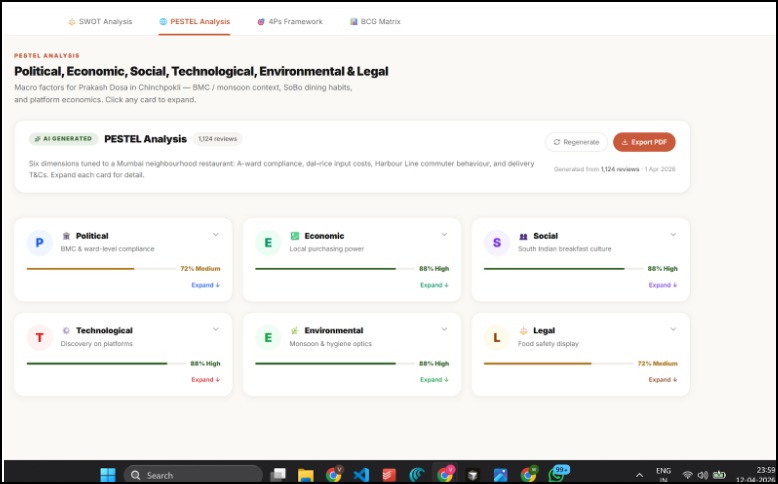
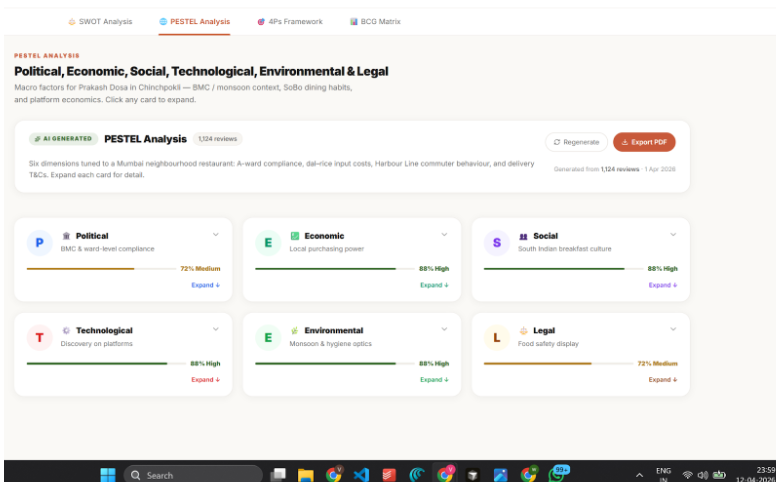
PESTEL Analyis
-
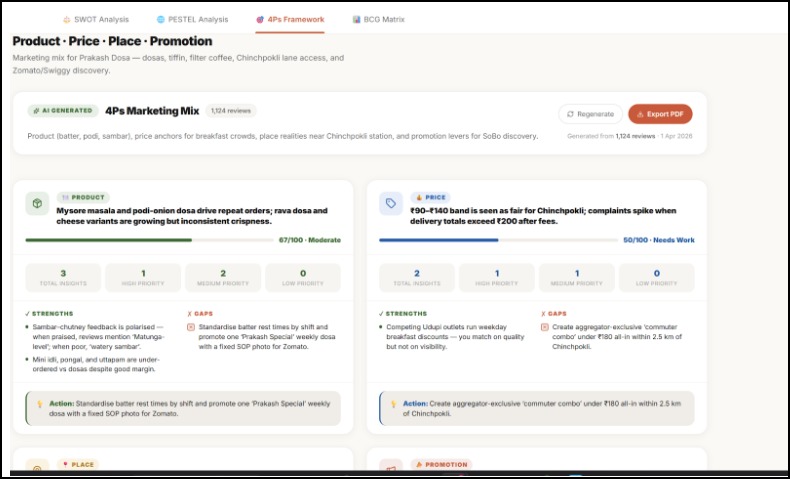
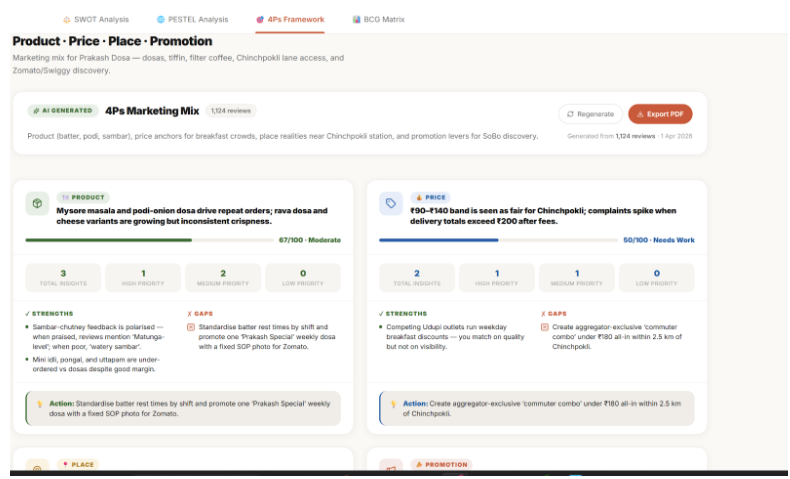
4P Framework
-
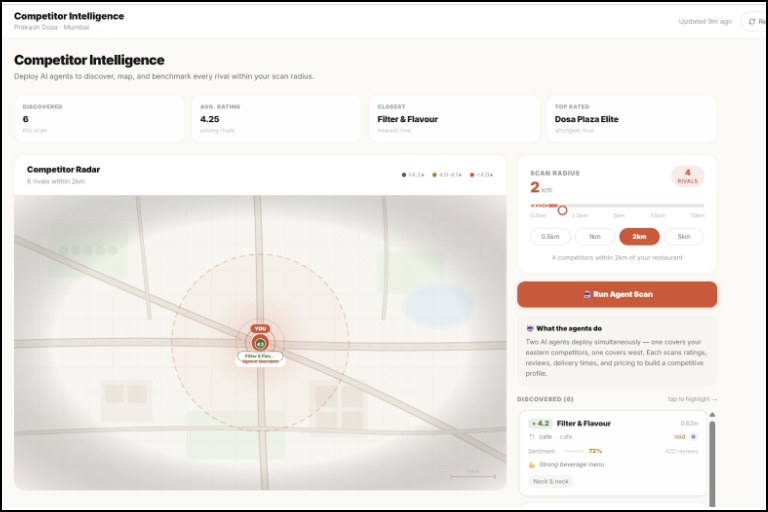
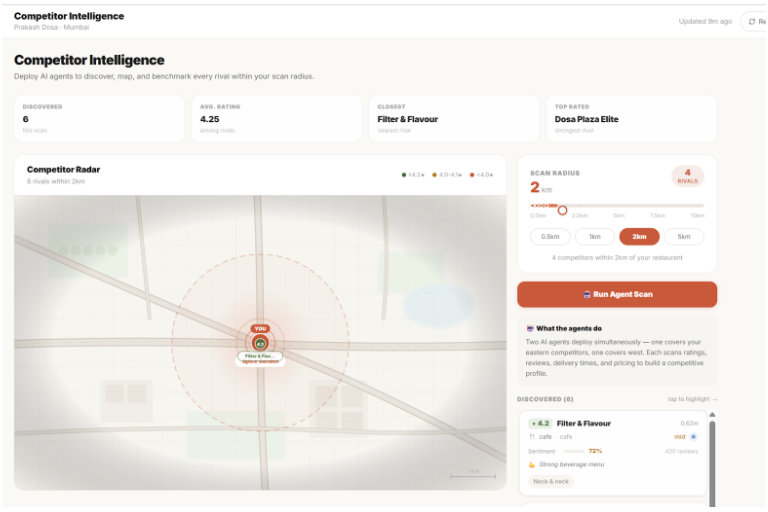
Market Plus Competitor Analysis
-
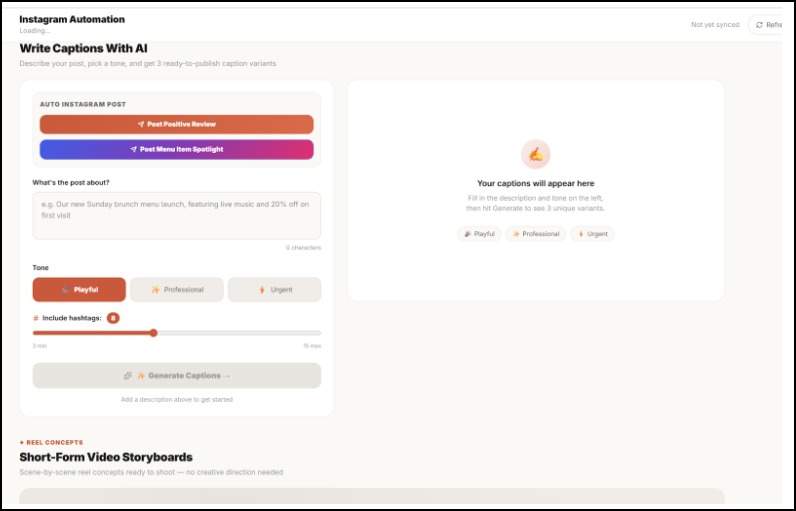
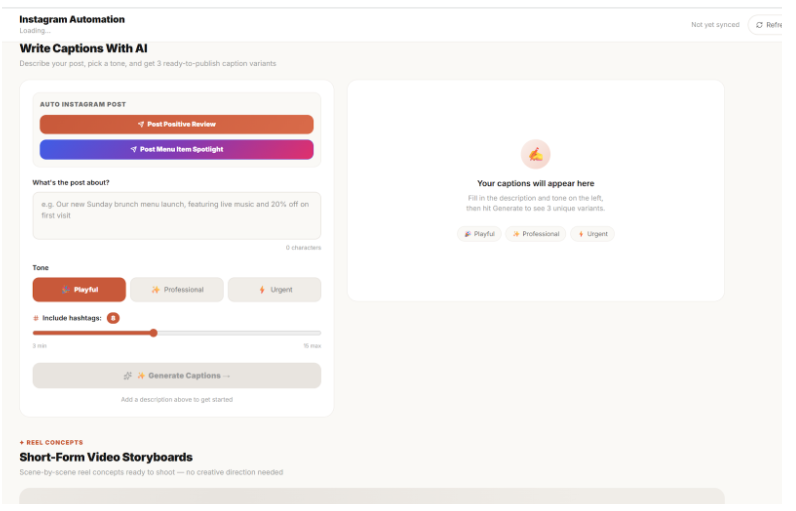
Automating Digital Marketing on Social Media
-
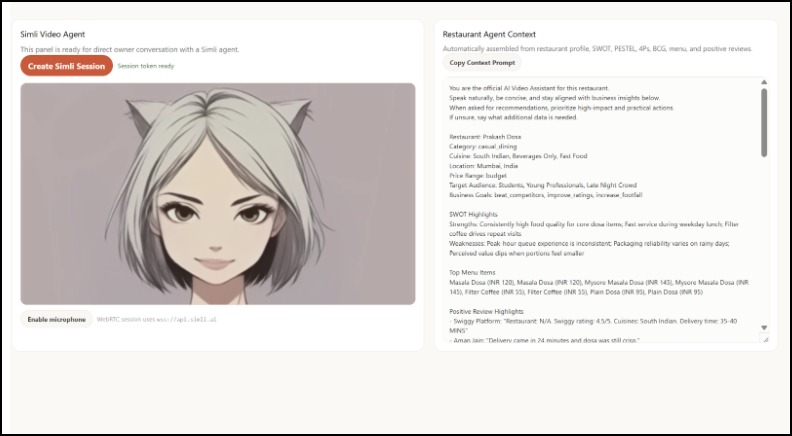
Simile Agent Ready to Help You
-
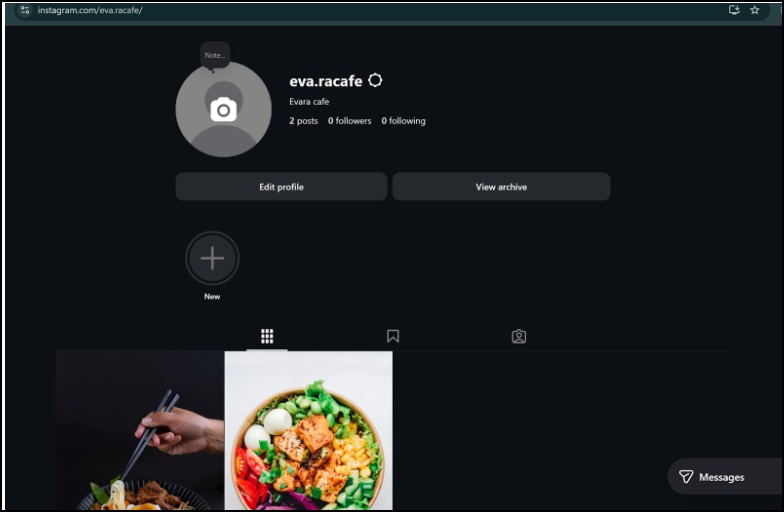
Automated Instagram Posts
-
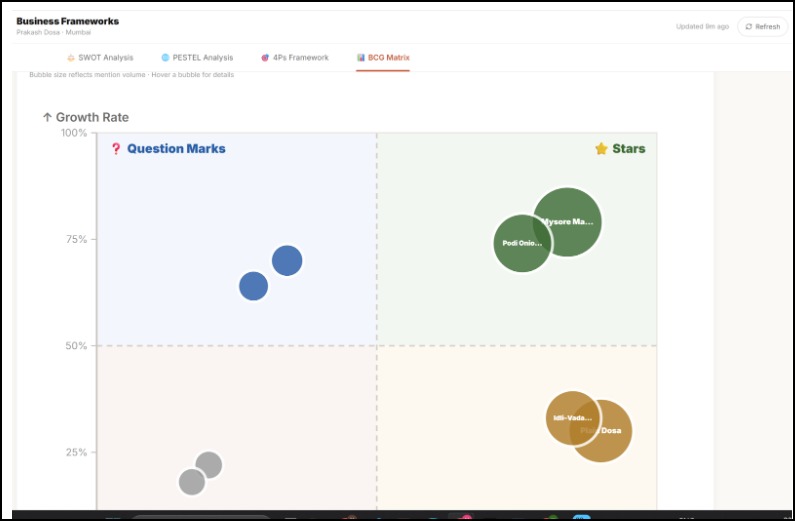
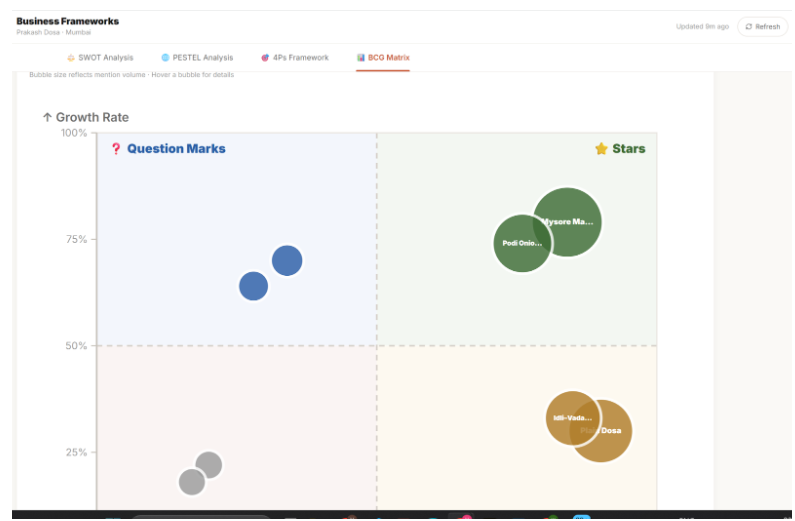
BCO Matrix
-
Customized Dashboard for You
Evara AI — Turn Restaurant Reviews Into Decisions
Inspiration
Walk into any restaurant and ask the owner what their biggest challenge is. Nine times out of ten, the answer isn't the food — it's the noise.
Reviews on Google. Comments on Instagram. Ratings on Zomato or Yelp. All of it scattered across platforms, all of it impossible to act on. An owner with 300 reviews this month still can't tell you:
- Which specific problem is costing them the most stars?
- Which competitor nearby is outperforming them, and why?
- What should they actually change next week?
They end up guessing. And in food and beverage, guessing late is expensive.
We built Evara AI because this is fundamentally an algorithmic problem — not a design problem. Aggregating signals across platforms, scoring sentiment by topic, benchmarking against real local competitors, and ranking recommendations by confidence: that's what turns noise into decisions.
What it does
You give Evara AI a restaurant name and its links. In return, you get a full intelligence report — competitor context, ranked fixes, and ready-to-post content — all derived from real customer data. Here's exactly what happens:
Pulls from 5 platforms at once — Google Maps, Zomato, Swiggy, Instagram, and Reddit are all scraped and merged into one clean data pipeline. No copy-pasting. No switching tabs.
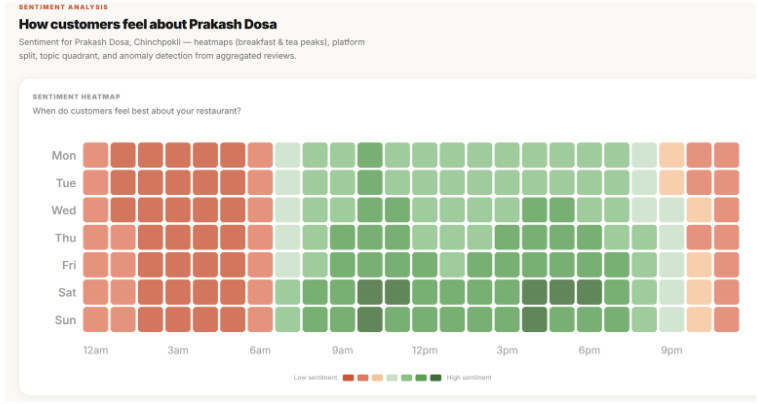
Breaks sentiment down by topic, not just stars — instead of one overall score, every review gets scored across 5 dimensions: food, service, delivery, price, and ambience. You learn what is losing you stars, not just that you're losing them.
Benchmarks you against nearby competitors — not industry averages. The actual restaurants competing for your customers, compared side by side.
Generates strategy grounded in evidence — SWOT analysis, PESTEL, BCG Matrix, and 4Ps — but every single point cites the reviews behind it. "Weak delivery speed (mentioned in 41 reviews, 3.1 avg rating on delivery) → Weakness." Not template filler.
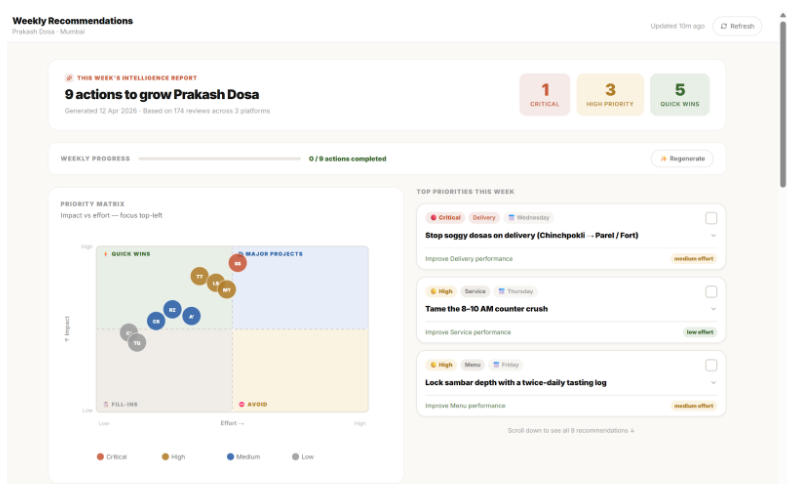
Ranks every recommendation with a confidence score — the system calculates confidence from 3 inputs: sample size, data recency, and model certainty. A recommendation with 8 reviews behind it is flagged differently than one backed by 200. You always know how much to trust it.
Turns insights into content — captions, hashtags, and a weekly posting plan, built from the topics your customers already care about. Not brainstormed. Derived.
How we built it
The system has 4 layers that work together as one pipeline.
Layer 1 — Data Collection
Apify actors scrape all 5 platforms. A custom normalization engine converts every platform's unique format into one unified Review schema, with deduplication and spam filtering before anything touches the AI.
Layer 2 — AI & Intelligence
Everything runs through Google Gemini (gemini-2.5-flash for reasoning, text-embedding-004 for semantic search). Four core modules:
sentimentEngine— scores each review across 5 topics individuallyframeworkEngine— builds SWOT/PESTEL/BCG/4Ps from citations, not imagination. Every point must return amention_countandconfidence_levelor it doesn't shiprecommendationEngine— ranks actions by category (menu, pricing, service, delivery) using a weighted confidence formulaconfidenceScoring— a standalone module that applies recency decay and sample-size penalties so the system never overstates certainty
Layer 3 — Backend
Fastify (Node.js / TypeScript) handles the API. Redis + BullMQ runs all heavy scraping and AI jobs asynchronously — the UI never waits on a long job. PostgreSQL via Supabase for storage, with pgvector for semantic search. WebSockets push live progress to the frontend during analysis. Budget caps (MAX_SCRAPE_BUDGET_USD, AI_MONTHLY_BUDGET_USD) are enforced at the architecture level, not as an afterthought.
Layer 4 — Frontend React + Vite + TypeScript + Tailwind. Mapbox GL JS renders the competitor map spatially — you see who's nearby and how they compare. Recharts handles sentiment timelines. Framer Motion keeps transitions smooth.
Challenges we ran into
1. Every platform speaks a different language Google gives sub-ratings. Instagram gives none. Reddit gives unstructured text threads. Getting all of that into one clean schema.
2. The AI kept making things up We fixed this by forcing structured JSON output with citation counts and confidence metadata on every point.
3. Confidence is easy to fake, hard to calibrate
Returning high_confidence on everything is trivial. Building a score that genuinely penalizes sparse data and old reviews — with a tuned recency decay curve and minimum sample thresholds.
4. Multi-stage async pipelines break in creative ways The flow runs across multiple BullMQ queues with hard dependencies: scrape → normalize → analyze → strategize → cache. When one stage fails mid-pipeline, the recovery logic has to be exactly right or you end up with partial, corrupted results.
Accomplishments that we're proud of
1. A confidence scoring system that admits when it doesn't know We haven't seen another hackathon project in this space that explicitly models uncertainty in its recommendations. Every output is ranked and scored.
2. Business frameworks that cite their sources Our SWOT analysis isn't generated text — it's structured reasoning over your actual reviews, with mention counts and example quotes on every point. Judges and operators can verify every claim in under 30 seconds.
3. A real end-to-end pipeline Input: a restaurant name. Output: ranked recommendations, competitor comparison, and ready-to-post content. Nothing in the demo is mocked. The full system runs live.
4. Production-quality architecture in a hackathon window Async job queues, schema validation, budget caps, and structured logging don't usually show up in 48-hour builds. We built it this way because a real product requires it.
What we learned
1. Admitting uncertainty is a competitive advantage. We spent time debating whether to show confidence scores prominently or bury them. Showing them won. Users trust a system that says "we only have 12 reviews to go on here" far more than one that always sounds certain.
2. The prompt structure matters more than the model. Requiring structured JSON with citation counts and confidence metadata — instead of asking for prose — transformed the quality of framework outputs. The model didn't change. The contract around it did.
3. Normalization is where the real engineering lives. The AI layer was interesting. The normalization layer was where we spent the most time. Messy, inconsistent, platform-specific raw data doesn't become useful intelligence on its own.
4. Async architecture unlocks completely different UX. Decoupling compute from the request cycle let us build a live progress experience — watching the pipeline run in real time — that would have been technically impossible in a synchronous setup.
What's next for Evara AI
Automated alert playbooks — sentiment spike or rating drop triggers a full response workflow automatically: owner notification, review reply draft, and a content suggestion. No manual monitoring needed.
Action tracking — weekly snapshots that close the loop: did the fix you made last week actually move your numbers? Most tools never answer that question.
Multi-location support — for chains and restaurant groups, a brand-level rollup that surfaces which locations are outliers and exactly why.
Wider platform coverage — Tripadvisor, Yelp, YouTube comments, and direct customer survey ingestion.
Built With
- apify
- bullmq
- business-intelligence
- data-engineering
- fastify
- gemini
- generative-ai
- marketing-automation
- natural-language-processing
- saas
- simile

Log in or sign up for Devpost to join the conversation.