-
-
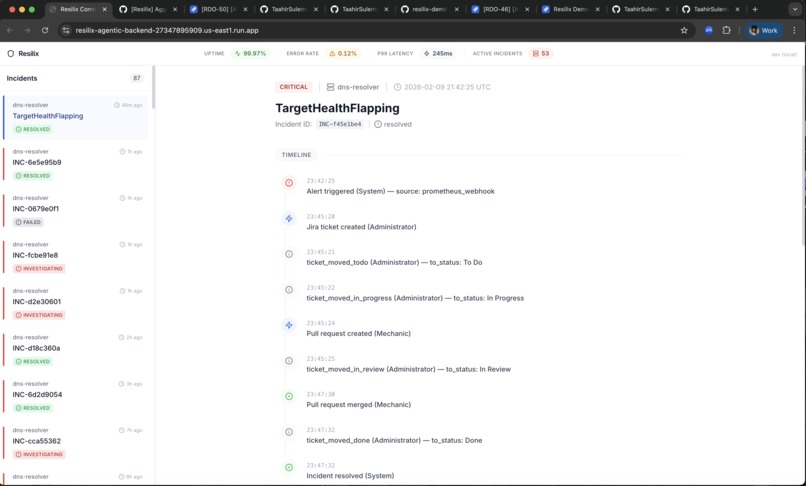
Resilix Timeline
-
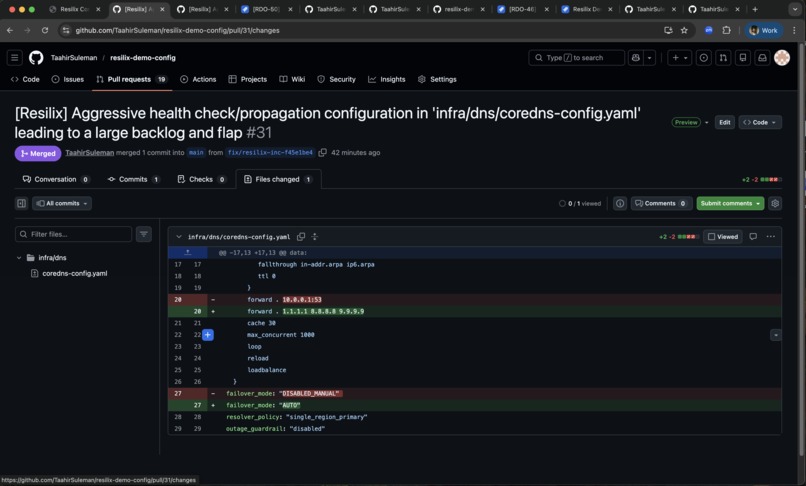
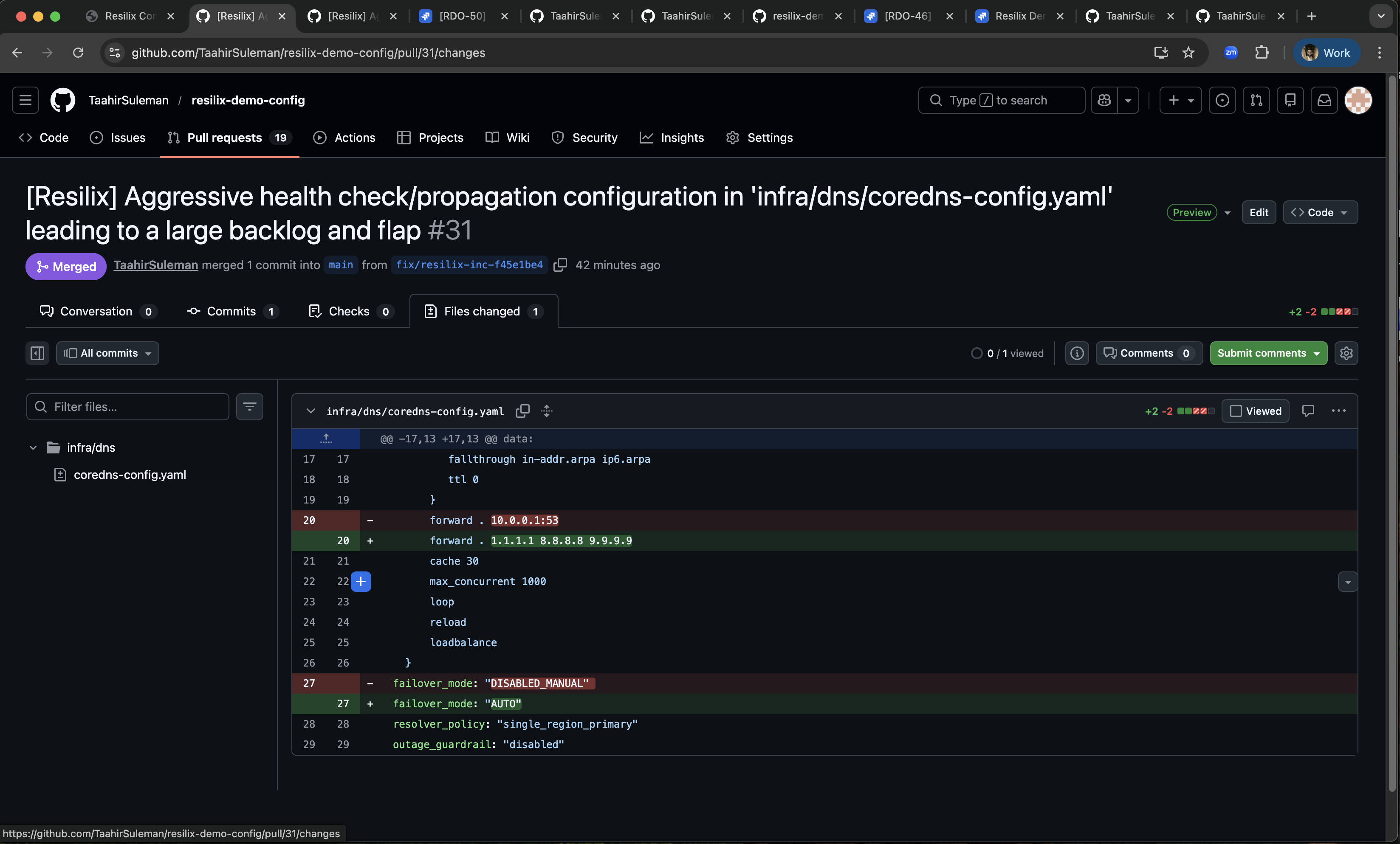
Resilix code fix/PR
-
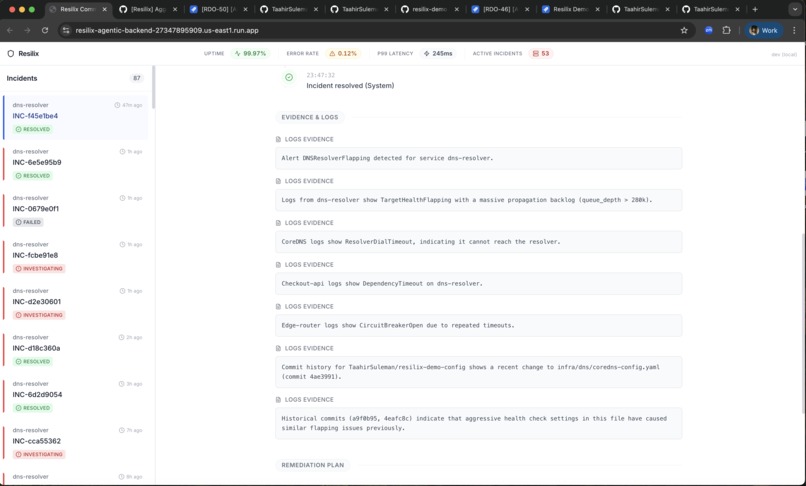
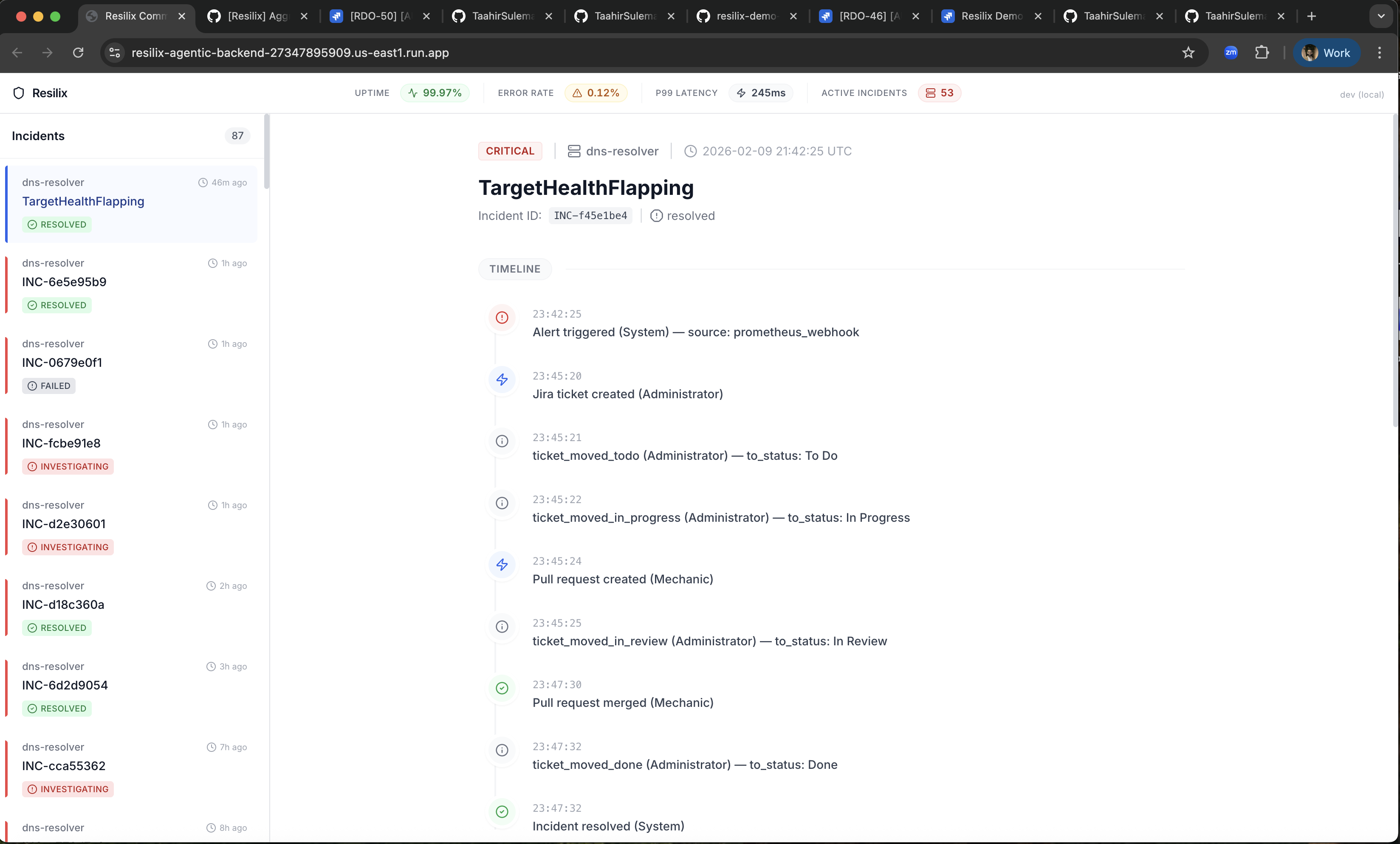
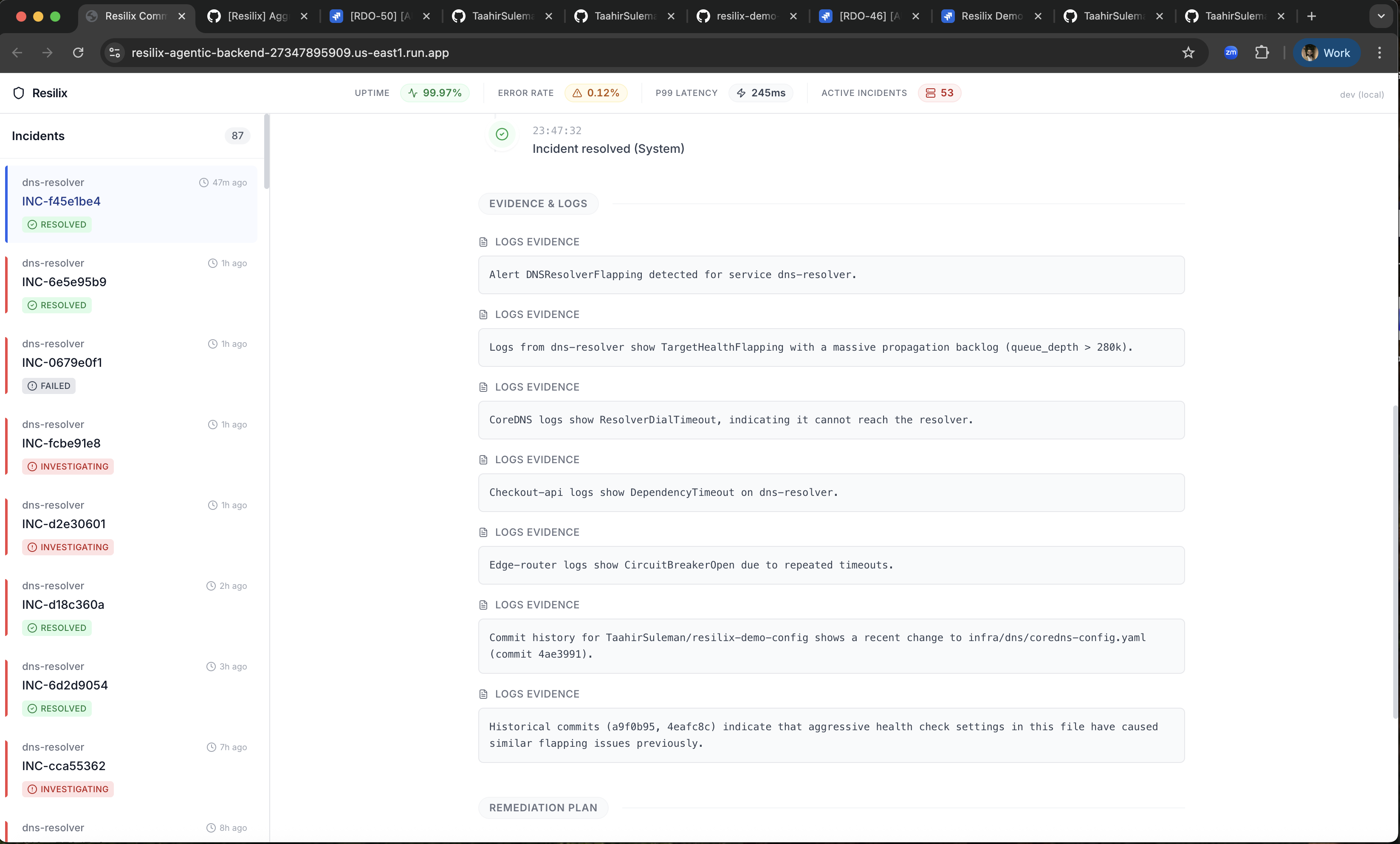
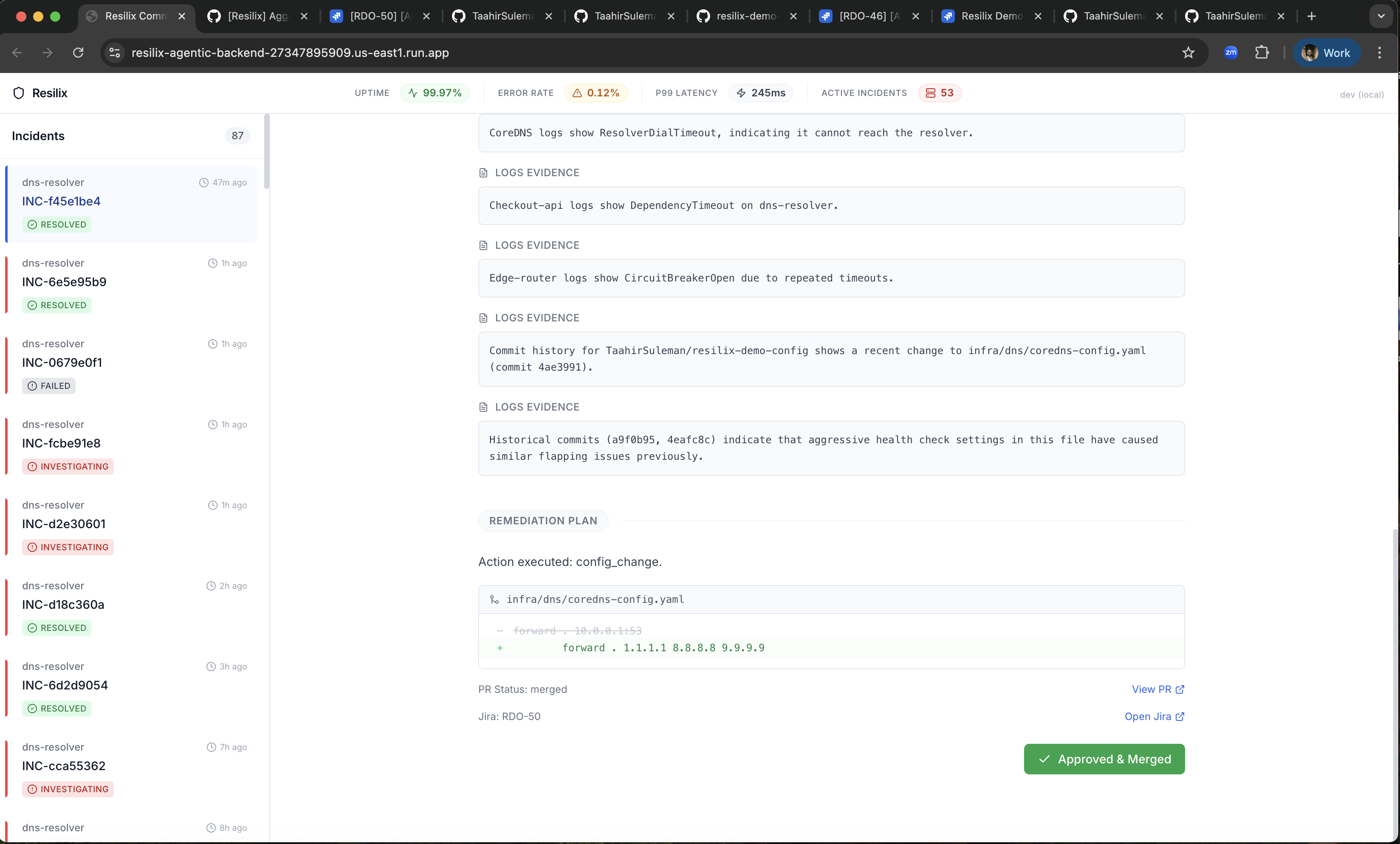
Resilix Logs & Evidence Investigation
-
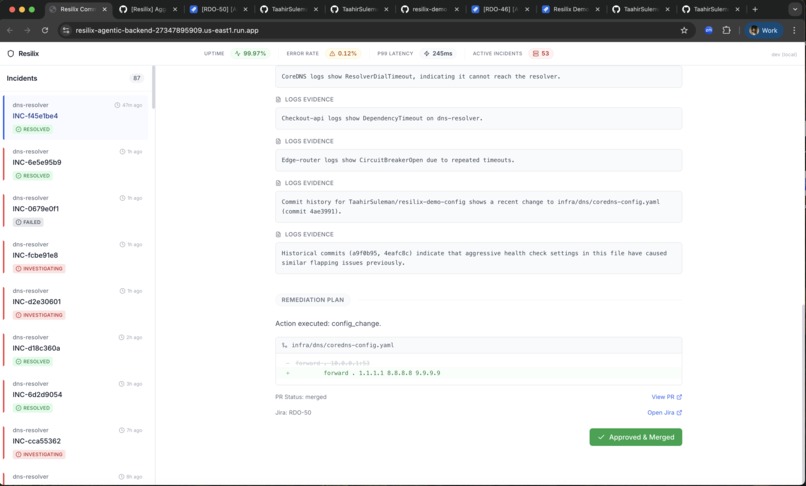
Resilix links and remediation
-
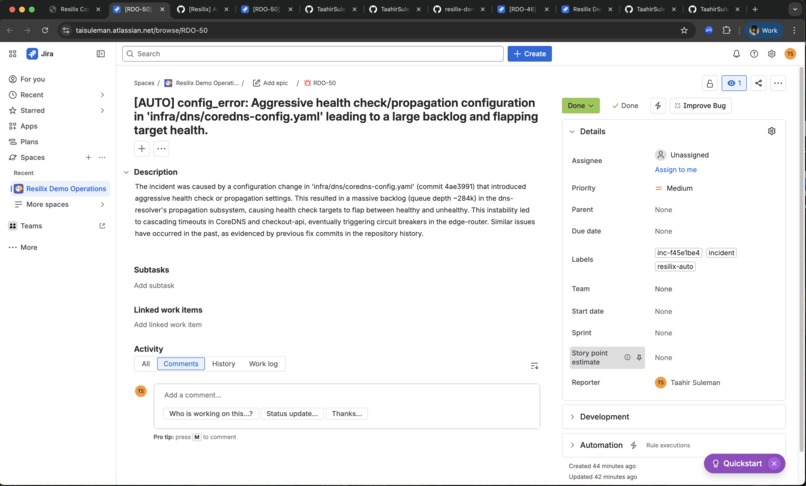
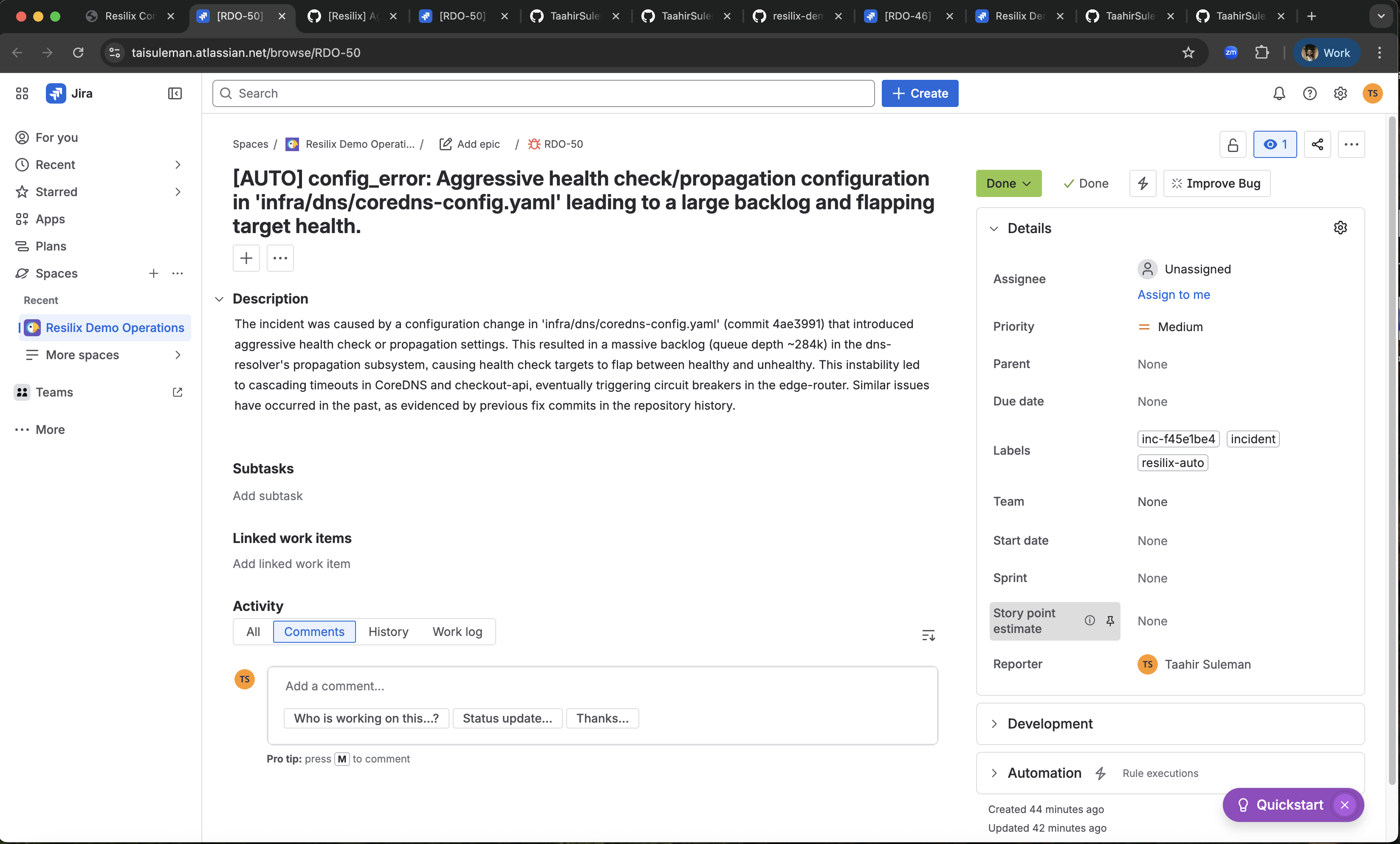
Resilix ticket created
Inspiration
We built Resilix to solve a painful operations problem: small infrastructure defects can trigger disproportionate, cascading outages, and human response loops are often too slow for that failure shape, as speed is critical in these issues to identify the root cause before it cascades. A key example of this is the AWS us-east1 outage which was caused by a simple DNS configuration issue, but a lack of identifying and remediating the issue immediately led to significant outages across several prominent service providers globally.
Similarly, the core demo scenario is a DNS misconfiguration that propagates into downstream timeouts, retry storms, queue growth, and service instability. In a traditional workflow, this requires multiple engineers to triage logs, identify root cause, open tickets, patch configs, run CI, and merge safely. That is exactly the delay window where business impact compounds in these war rooms created to solve these issues.
Two things directly inspired this project:
- Watching how a relatively small DNS/service-discovery defect can cascade into major regional impact (in the spirit of the AWS us-east incident pattern).
- Seeing how well agents perform on repeatable, high-structure tasks when you give them strict guardrails, typed outputs, and clear handoffs.
What it does
Resilix is a multi-agent incident response system that moves from alert to verified remediation with governance controls:
- Sentinel validates and prioritizes incoming alerts.
- Sherlock performs root-cause analysis and produces a structured thought signature.
- Administrator creates and transitions Jira tickets through workflow states.
- Mechanic proposes and executes a real remediation PR in GitHub.
How we built it
The system is implemented with FastAPI, typed Pydantic models, Google ADK agent orchestration, and direct Jira/GitHub API integrations, and is deployed as a single page application with Google Cloud Run. A simulator generates deterministic cascading-failure scenarios so the full lifecycle can be demonstrated repeatedly: alert ingestion, RCA, ticketing, PR creation, approval-gated merge, and incident resolution.
Gemini 3 Integration (~200 words)
Gemini 3 is central to Resilix because the system depends on stateful, multi-agent reasoning, not a single prompt wrapper.
First, we use dynamic thinking levels per agent role to balance latency, cost, and reasoning depth. Fast triage tasks can run at lower thinking settings, while heavier RCA/remediation reasoning can run at deeper settings. This lets each agent operate at the right cognitive budget instead of overpaying with one fixed configuration, balancing speed, latency and cost with accuracy and efficacy.
Second, we use thought signatures as a continuity layer used across multiple agents in the workflow. Investigative context (root cause category, evidence chain, recommended action, target artifacts, confidence) is persisted in shared state and carried through Sentinel, Sherlock, Administrator, and Mechanic handoffs so each stage can operate on consistent context. That turns the pipeline into a coherent state machine rather than disconnected calls, and materially improves remediation precision.
Third, Gemini 3’s tool/function-calling pattern enables grounded action: the agents can reason over logs/code context, then trigger Jira/GitHub operations through controlled interfaces. This closes the loop from analysis to execution while preserving auditability.
In short, Gemini 3 is the reasoning core that coordinates context-aware decisions and drives autonomous incident remediation with guardrails.
Challenges we ran into
- Keeping deployed webhook processing responsive under real integration latency (model + external APIs) while preserving reliability.
- Ensuring end-to-end operational correctness across systems (timeline sequencing, Jira state transitions, PR lifecycle, and approval-gated merge).
Accomplishments that we're proud of
Impact (KPIs)
These are scenario-based estimates grounded in current successful demo artifacts (n=2 fully resolved runs):
- Observed autonomous MTTRs:
222.952sand265.536s Mean autonomous MTTR:
244.244s(4.07 min)MTTR Reduction = 1 - (Autonomous MTTR / Manual Baseline MTTR)Cost Avoided per Incident = (Baseline MTTR - Autonomous MTTR) × 16,700
| Baseline Manual MTTR | Time Saved per Incident | MTTR Reduction | Estimated Cost Avoided per Incident |
|---|---|---|---|
| 30 min | 25.9 min | 86.4% | ~$433,000 |
| 45 min | 40.9 min | 91.0% | ~$683,000 |
| 60 min | 55.9 min | 93.2% | ~$934,000 |
Judging Criteria Fit
- Technical Execution (40%): real multi-agent orchestration, typed contracts, API integrations, approval gates, and replayable simulator workflows.
- Innovation / Wow Factor (30%): autonomous incident-to-remediation loop with governance, not a chatbot or prompt-only wrapper, but instead a multi-agent orchestration that intercepts Prometheus alerts, determines the cause of the issue, creates a jira ticket with an outline, and actions the ticket with a PR, detecting and solving errors end-to-end in under 5 minutes.
- Potential Impact (20%): meaningful MTTR compression and large incident-cost avoidance potential.
- Presentation / Demo (10%): clear lifecycle narrative from failure signal to validated remediation and recovery.
What we learned
- Dynamic thinking levels are a practical control surface for production-grade agent systems: they let you tune speed/cost/quality per role instead of forcing one global compromise.
- Thought signatures are the key to reliable multi-agent continuity: they preserve intent and reasoning context so downstream agents act on the same investigative truth.
- Agents are especially strong at repeatable engineering workflows when bounded by strict contracts, deterministic guardrails, and verifiable external side effects.
What's next for Resilix
Next, we plan to extend this workflow into various applications to detect and remediate several failure classes while keeping the same principles: strict guardrails, auditable stateful agent handoffs, and fast but safe autonomous remediation with human governance at critical merge points.
Built With
- asyncpg
- docker
- fastapi
- gemini
- github-api
- google-adk
- google-cloud
- google-compute-engine
- google-genai
- httpx
- jira-api
- postgresql
- prometheus
- pydantic
- python
- react
- sqlalchemy
- structlog
- tailwind
- typescript
- uvicorn
- vite

Log in or sign up for Devpost to join the conversation.