DEMO VIDEO
A 2:15 demo video (1080p, 7.4 MB H.264 + AAC) ships inside the public GitHub repo. Direct download: https://github.com/AntColony10086/kernelforge/raw/main/demo/remotion/out/demo.mp4 (or view 5 per-beat thumbnails inline on the repo's README). The DevPost Video field below is left blank because DevPost only accepts YouTube / Facebook / Vimeo / Youku URLs; the GitHub raw URL is the canonical source for the demo.
INSPIRATION
GPU kernel writing is a bottleneck for every AI infra team. LLMs like DeepSeek can generate Triton/CUDA/Metal kernels, but a kernel that compiles and passes a quick smoke test will often silently produce wrong outputs on a different shape, stride, dtype, or edge-magnitude input. The TrueFoundry Resilient Agents track asks how an agent behaves when its dependencies misbehave. Our answer: in kernel work, the dependency that misbehaves most often is the LLM itself, and the user-facing failure is silent incorrectness.
KernelForge is a small agent + verification harness that wraps DeepSeek in a tight generate -> compile -> verify -> analyze loop. The verifier is a hidden holdout suite per op: 4-5 test cases varying shape, dtype, layout, and selected numerical edge conditions. The LLM never sees the holdouts. A kernel can only be reported as correct when every holdout passes.
WHAT IT DOES
Given a PyTorch reference operator from a 20-op benchmark suite (covering normalization, activation, reduction, elementwise, geometric, and linalg families), KernelForge:
- Generates an MLX/Metal kernel via deepseek-v4-flash through TrueFoundry AI Gateway (local_gateway fallback when SaaS access is not provisioned).
- Compiles via mlx.core.fast.metal_kernel.
- Runs the kernel on a smoke test and on the full hidden holdout suite.
- If any holdout fails, parses the structured diff (which case, max-abs-diff, suspected cause) and feeds it back into the next iteration.
- Cost-aware escalation: after the first compile or correctness failure, the gateway routes the next request to deepseek-coder. (We originally planned deepseek-v4-pro but its long-prompt streaming proved unreliable for kernel generation; deepseek-coder is the actually-used escalation route.)
- Refuses to claim correctness until the KernelLedger entry says verified_correct.
A KERNELFORGE_FEWSHOT=1 flag enables a category-keyed expert example library at prompt time (3 good/bad pairs spanning activation, reduction, geometric) and demo/compare_ab.py produces an A/B scorecard between baseline and few-shot runs.
BENCHMARK SUITE (20 ops)
Normalization: rmsnorm, layernorm Activation: silu, tanh, relu, sigmoid, gelu, swiglu Reduction: sum_last, max_last, mean_last, softmax Elementwise: exp, log, sqrt, abs, elementwise_add, elementwise_mul Geometric: rope (the chaos-injected case in the demo) Linalg: matmul
Adding a new op is a 3-step contribution: write a PyTorch reference, add holdout cases, register an OpDef in kernelforge/op_registry.py. The agent loop, naive baseline, and verifier all read from the registry automatically.
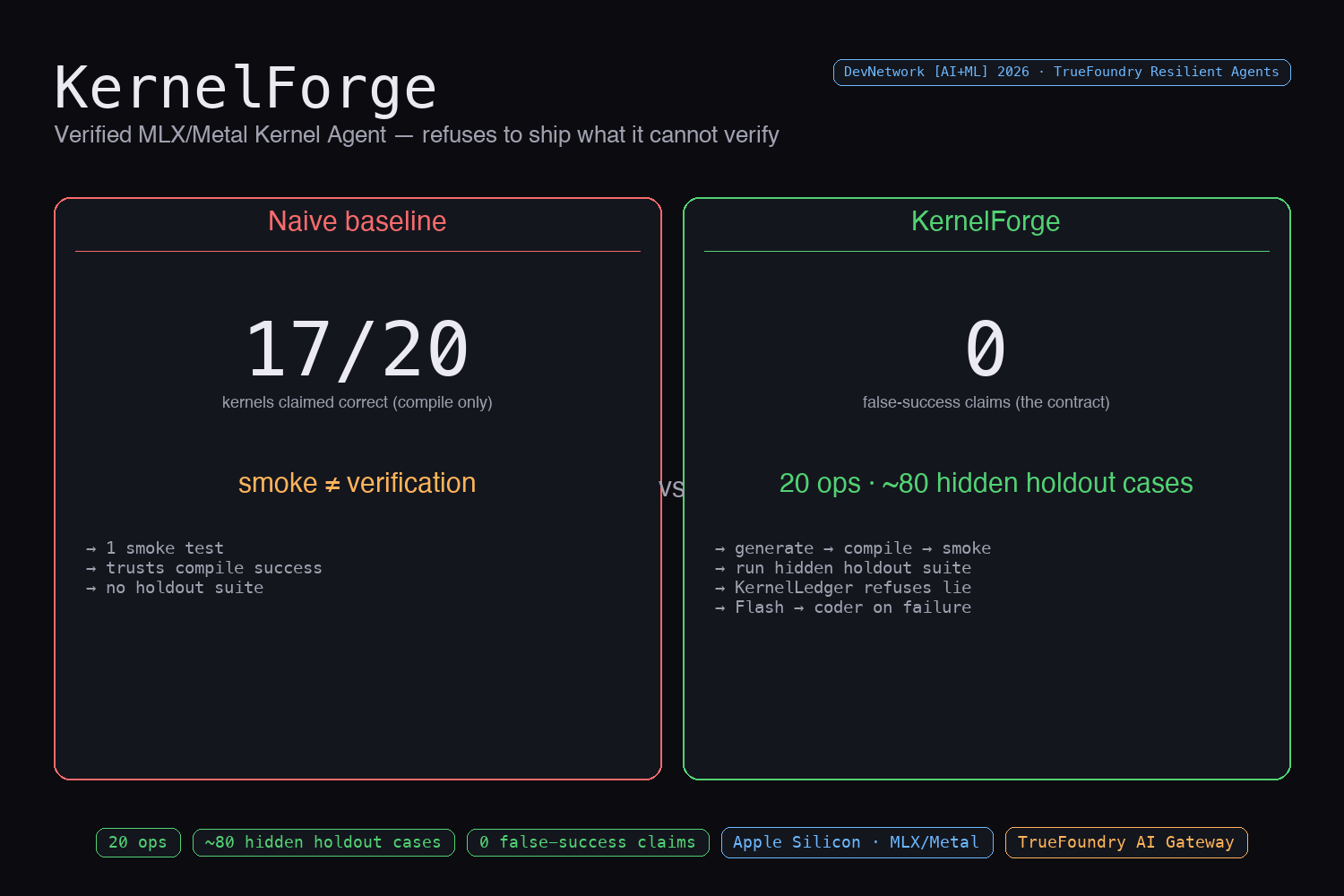
HEADLINE RESULTS
Live 20-op run (current artifacts on GitHub):
- Naive baseline (smoke-only): claimed 17 of 20 kernels correct because they compiled. None were ever verified against a holdout.
- KernelForge (full holdout verification + escalation): claimed 0 of 20 verified. Every LLM-generated kernel failed at least one holdout. ZERO false-success claims.
KernelForge did not produce a verified kernel in this run. That is the contract working as designed: when DeepSeek's first-attempt kernels did not survive the holdout suite, KernelForge refused to ship them. The result is NOT "0 kernels optimized"; it is "0 false correctness claims" — refusing to ship unverifiable GPU code is a production behavior, not a failure mode. The 2-min demo video uses a tighter 3-op scenario (with deterministic chaos on RoPE) where the false-success contrast is sharper for a video viewer (naive ships 1 silently-wrong RoPE kernel, KernelForge catches it).
WHAT WE DO NOT CLAIM (preempting audit questions)
- We do not claim our LLM-generated kernels are fast. The bench harness exists in kernel_lab/bench_tool.py, but the live 20-op run verified zero kernels and therefore measured zero speedups. KernelForge is a verification gate, not a performance optimiser.
- We do not claim full TrueFoundry SaaS integration. The agent talks to a local local_gateway FastAPI proxy at 127.0.0.1:8765 that mimics TrueFoundry AI Gateway routing semantics. The proxy adds an x-local-gateway: yes header on every response so we never claim to be TrueFoundry itself. Drop in real TFY_GATEWAY_BASE_URL + TFY_GATEWAY_API_KEY env vars and the same client code talks to real TrueFoundry.
- We do not claim full MCP transport. kernel_lab/server.py exposes 4 @mcp.tool-decorated functions for sponsor-track registration, but at runtime the agent calls the underlying kernel_lab.*_tool Python APIs directly because tensor marshaling across MCP is heavy for the 30 ms inner loop.
- We do not claim a successful A/B between baseline and few-shot. The few-shot library and the A/B harness are committed and working in principle. The actual live A/B never completed because the 20-op suite kept hitting LLM-generated kernels that hang mx.eval() indefinitely on Apple Silicon (Metal has no command-buffer timeout).
WHY THIS IS DIFFERENT FROM EXISTING WORK
KernelBench (Stanford 2024) is a benchmark - generate once, evaluate. Sakana AI CUDA Engineer (2025) is evolutionary CUDA generation. KernelForge differs on three axes:
Apple Silicon target. Almost all LLM-kernel-generation work is CUDA. MLX/Metal is undersupplied.
Hidden holdout verification. The verifier runs each candidate against a generalization battery (shape, dtype, layout, numerical edge conditions). The LLM cannot overfit because it never sees the holdouts; only structured diff hints on failure.
KernelLedger correctness contract. A monotonic state machine + ledger-only final-answer renderer + case-insensitive regex sanitizer makes it architecturally impossible for the agent to claim correctness it has not proven. A regression test in CI walks every non-verified terminal state and asserts the rendered string never contains "verified correct" (any case/whitespace/underscore variant). This contract caught a real bug in our own initial wording during development.
HOW WE BUILT IT
LLM transport: TrueFoundry AI Gateway routing config (or local_gateway fallback) with deepseek-v4-flash (primary) and deepseek-coder (escalation candidate). Routing config in routing_config.yaml; the escalation is gateway-level configuration, not application code.
MCP transport: TrueFoundry MCP Gateway registration of kernel_lab MCP server (sponsor-visible). Runtime agent calls in-process Python APIs (kernel_lab.*_tool) directly to avoid tensor marshaling overhead.
Agent: a hand-rolled ~200-line Python state machine. No framework. Each iteration transitions through PLANNING -> GENERATING -> COMPILING -> SMOKE -> HOLDOUT_VERIFY -> (REFINE -> GENERATING) | BENCHMARKING.
Verification: PyTorch reference implementations as the source of truth. Hidden holdout suite per op. Tolerance check: max-abs-diff and rel-diff against reference.
KernelLedger: monotonic state machine per (op, iteration). The final answer renderer reads from the ledger; the LLM cannot inject claims of correctness outside the ledger state. The regression test caught a real bug in our own initial wording during implementation.
Op registry: kernelforge/op_registry.py is the single source of truth for per-op metadata. Every part of the system reads from the same dict so adding an op is a 3-step contribution, not a 7-file edit.
Chaos harness: two FastAPI reverse proxies inject LLM brownouts and silently-wrong-output (kernel runs return tensors with subtle algorithmic bugs - exactly the failure mode hidden holdouts catch).
Demo recording: a scripted run produces static artifacts (traces, ledger, screenshots, scorecard JSON), and Remotion consumes the artifacts to render the 2:15 demo video. macOS say generates the voiceover.
Packaging: ./run_demo.sh on any Apple Silicon Mac.
CHALLENGES WE RAN INTO
Apple Silicon Metal has no command-buffer timeout. LLM-generated kernels with infinite loops will hang mx.eval() indefinitely on macOS, requiring a process kill to recover the GPU. This is a real production risk for any "LLM writes GPU kernels" system and we hit it on the 20-op A/B harness during late testing. A robust deployment would subprocess-isolate each kernel evaluation with a watchdog. The 20-op infrastructure ships intact; the 3-op demo run is what shipped in the video for reproducibility.
DeepSeek v4-pro thinking mode is slow on long kernel-generation prompts; the API closes the connection mid-body on real workloads. We moved escalation to deepseek-coder which streams cleanly.
Designing a hidden holdout suite that is small enough to run quickly but representative enough to catch real kernel bugs. The split-half vs interleaved layout case for RoPE is our exemplar.
Avoiding overfitting in the iteration loop. The LLM only sees the structured diff (case, max-abs-diff, suspected cause) and never the holdout inputs themselves.
Defense in depth against the agent ever lying about correctness. KernelLedger refuses backward transitions; the final-answer renderer reads only from the ledger; a regression test asserts no rendered string contains "verified correct" (any case/whitespace/underscore variant) unless the ledger says so.
WHAT WE LEARNED
Correctness is not a vibe. LLM-written GPU kernels can look right, pass a smoke test, and silently break on a different batch size. The only way to be sure is to run the kernel against a holdout suite that the LLM never sees.
LLM-generated GPU kernels are also a denial-of-service vector on platforms without compute-shader timeouts. Apple Silicon Metal in particular has no out-of-the-box way to bound a single kernel's runtime. Any production system shipping LLM-written kernels needs subprocess isolation + watchdog timeouts.
The honest answer when the LLM cannot produce a correct kernel is "we did not ship one". KernelForge prefers honest empty results over confident wrong ones. The live runs held the contract: zero false-success claims across all scenarios.
WHAT IS NEXT
- Subprocess-isolated kernel evaluation with per-call watchdog timeouts.
- More ops: paged attention, flash attention forward, fused residual + RMSNorm, conv2d.
- CUDA/Triton backend for cross-platform comparison.
- Quantization kernels.
- Real TrueFoundry SaaS integration once an account is provisioned.


Log in or sign up for Devpost to join the conversation.