-
-
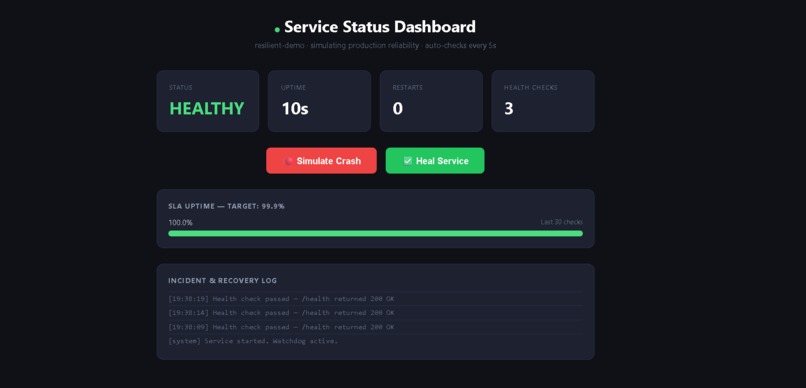
Resilient service running live on GitHub Pages
-
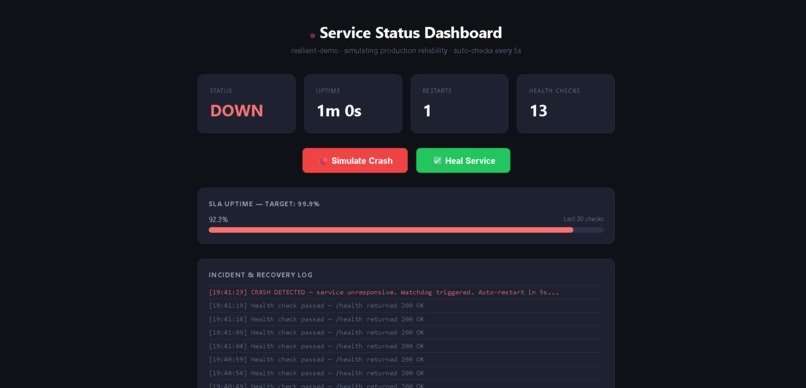
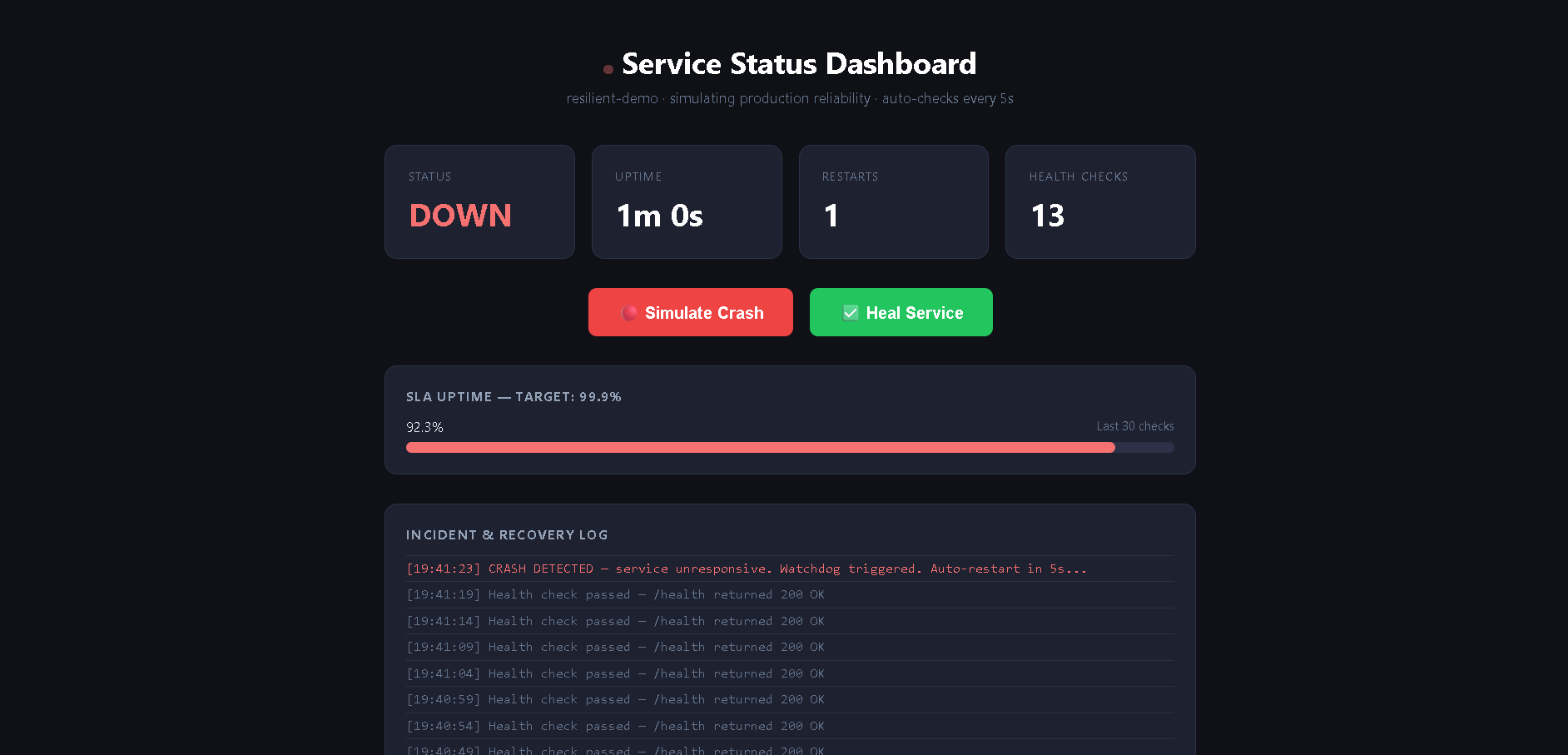
Service crash detected — watchdog triggered, SLA drops to 92.3%, incident logged in real time with timestamp
-
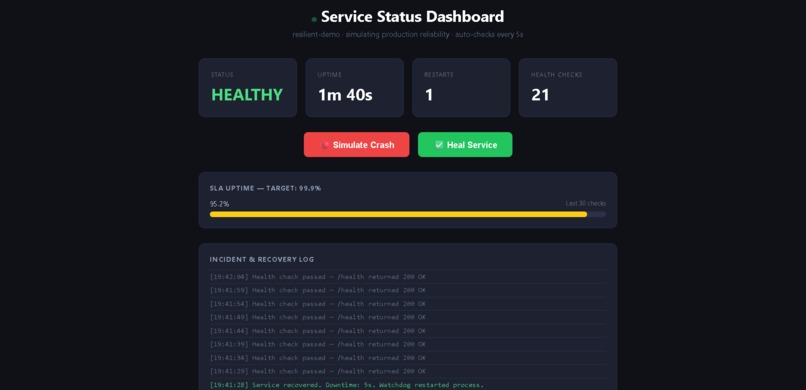
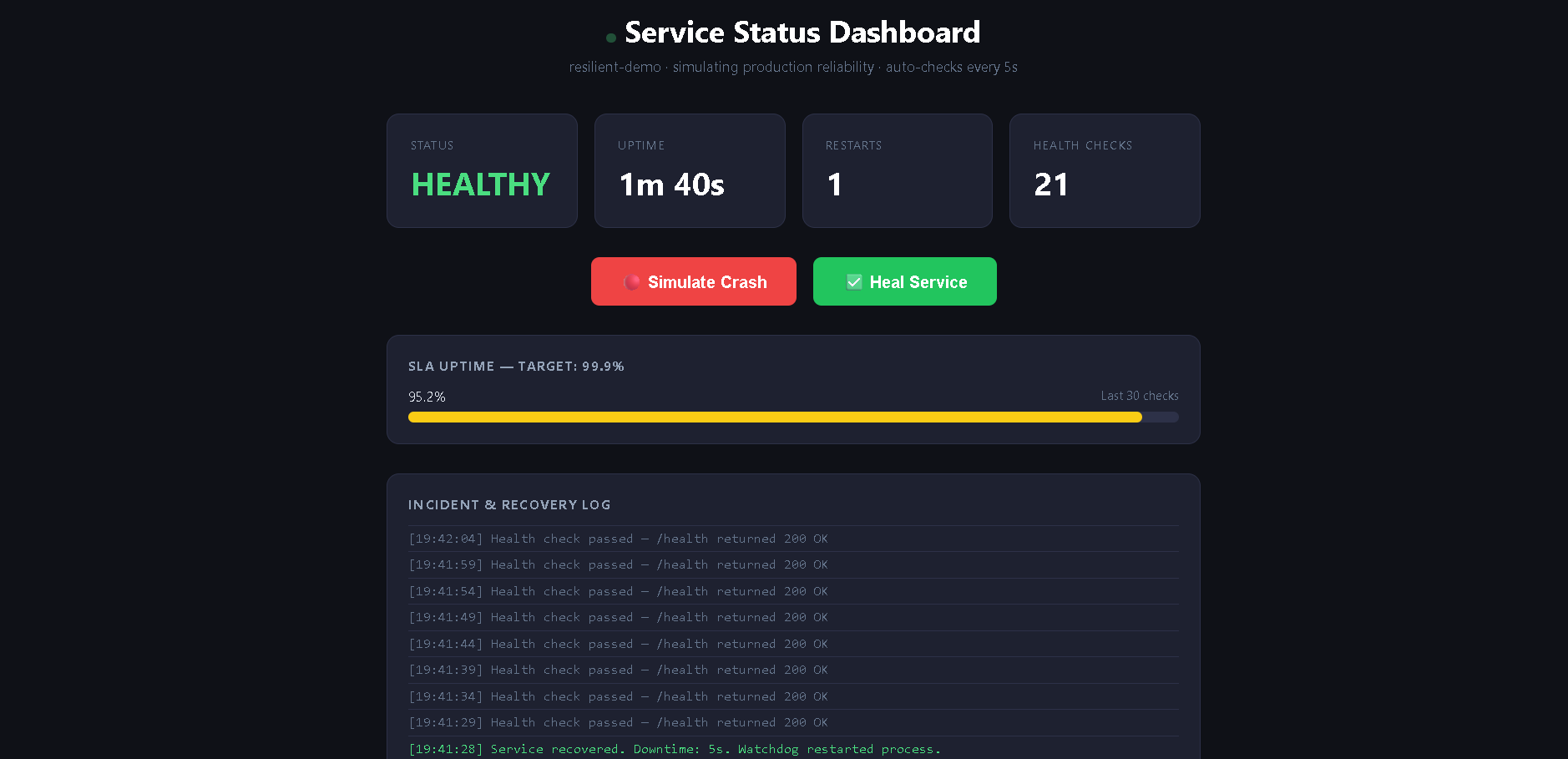
Auto-recovery complete — service back to HEALTHY in 5s, watchdog restarted process, SLA recovering to 95.2%
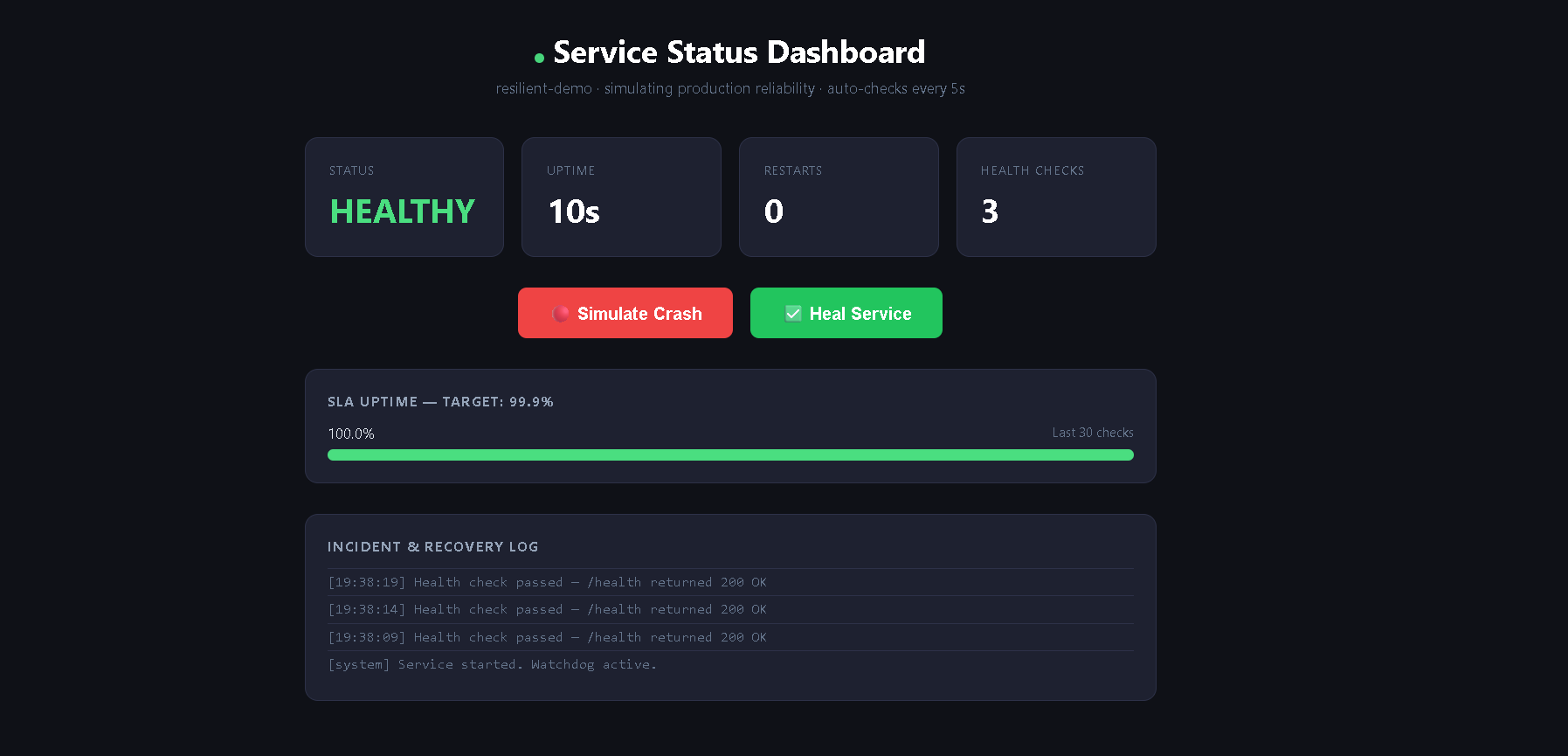
The 3 AM Problem
Nobody warns you about this in college — services don't just crash loudly. They go quiet. No error, no alert, just silence. I built this because I wanted to actually see what a system looks like when it's designed to stay alive.
What I Built
A live service monitoring dashboard that simulates real production scenarios — health checks, crash detection, auto-recovery, and SLA tracking. Hit "Simulate Crash" and watch the watchdog kick in, the incident get logged, and the uptime percentage drop in real time. No fluff, no third-party tools — just the raw mechanics of reliability, visible in a browser.
The Insight
Every tutorial ends the moment Hello World appears. Production engineering
starts exactly there. I kept asking: what happens after it runs? What happens
when it doesn't?
How I Built It
Vanilla JS, plain HTML, zero dependencies. I deliberately avoided frameworks — I wanted to understand the primitives first. The whole thing is one file that anyone can read in 10 minutes. The dashboard polls itself every 5 seconds, tracks a rolling 30-check SLA window, and auto-restarts after a simulated crash.
Challenges
The hardest part wasn't the code — it was figuring out what "reliability" actually means at a small scale. Turns out a watchdog, a health endpoint, and an incident log are enough to demo something genuinely real. Also fought with deployment for longer than I'd like to admit.
What I Learned
Reliability isn't a feature. It's a posture. You either design for failure from the start, or you get paged at 3 AM explaining why you didn't.

Log in or sign up for Devpost to join the conversation.