-
ResiliBot demo
Inspiration
In the modern AI ecosystem, building an LLM agent is relatively straightforward, but keeping it alive under production conditions is brutal. Most real-world applications rely on a single external LLM provider, exposing the entire architecture to a cascade of runtime vulnerabilities: sudden rate limits (429 errors), API deprecations, transient network drops, and unpredictable gateway downtime.
We were inspired by high-availability systems engineering. Instead of hoping that external upstream APIs stay up, we built a system that actively assumes everything will fail. ResiliBot shifts the paradigm from fragile single-provider dependency to an unbreakable, multi-agent mesh architecture.
What it does
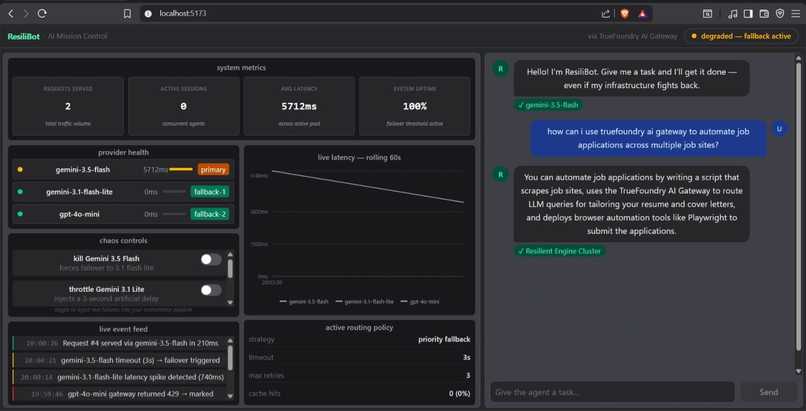
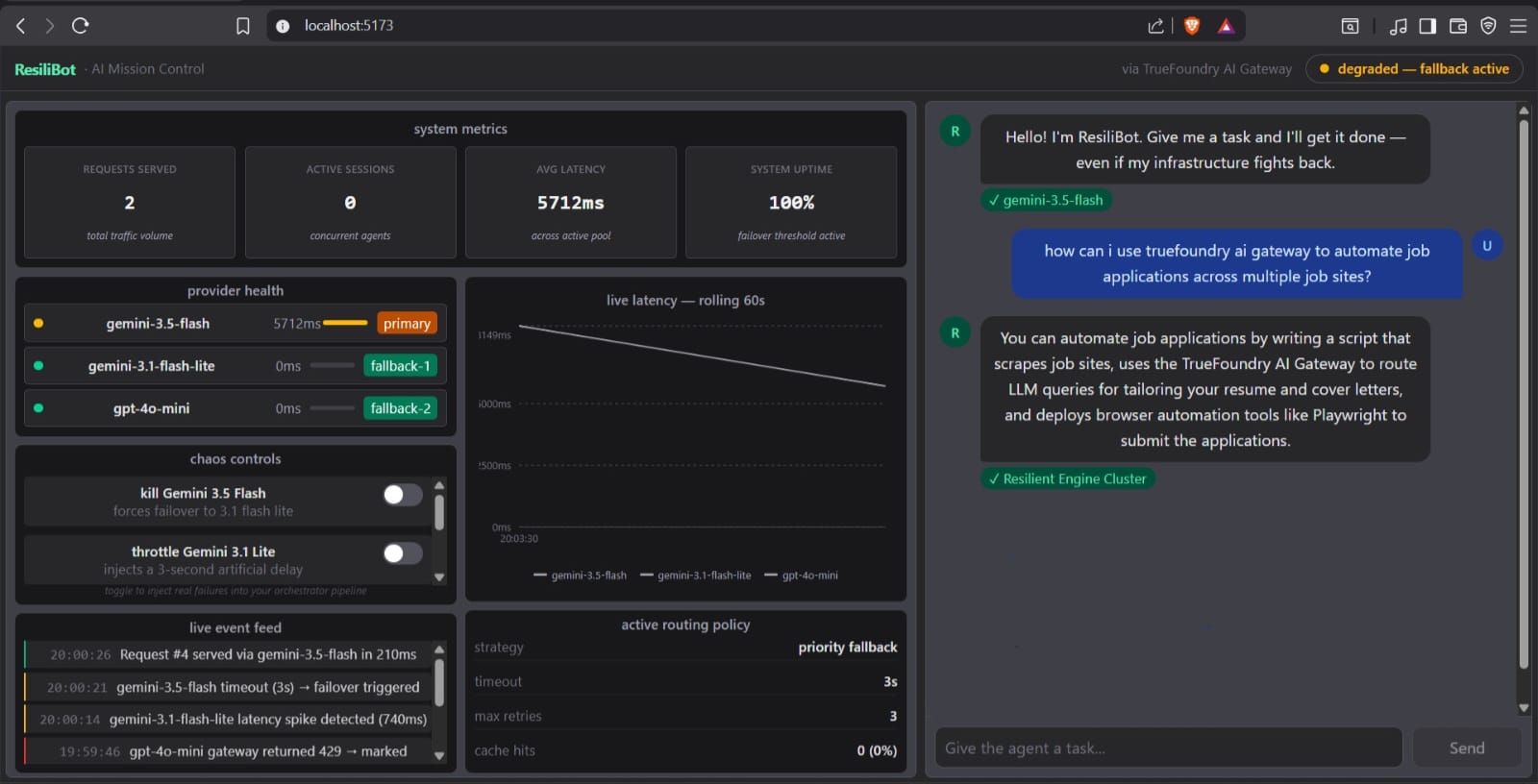
ResiliBot is a fault-tolerant multi-agent LLM orchestration engine designed to maintain seamless end-user operations even when underlying AI infrastructure completely breaks down.
The application splits inputs into two core execution paths: a lightweight, instant fallback path for simple conversational interactions, and a heavy-duty Orchestrator-Specialist multi-agent framework for complex tasks. It features a responsive frontend monitoring dashboard complete with a "Chaos Engine." Users can manually simulate live system emergencies—such as throttling high-tier models, rate-limiting the system, or completely killing the primary provider pool—and watch in real time as the backend programmatically intercepts the error, engages a fallback model, and delivers a successful answer without a single loop exception.
How we built it
The project is split into a modular backend and a reactive frontend dashboard:
- The Backend Architecture: Built with Python and FastAPI, utilizing Uvicorn as a high-throughput asynchronous web gateway. We leveraged Pydantic schemas to strictly validate data shapes and used the OpenAI SDK routed through TrueFoundry's AI gateway mesh.
- The Resilient Routing Engine: We implemented an active circuit-breaker design pattern. The backend monitors incoming requests; if a primary agent tier throws a connection or quota exception, the request is intercepted by a middleware routing layer and gracefully degraded to secondary high-availability fallback paths.
- The User Interface: Built using React, TypeScript, and TailwindCSS. The layout maintains real-time telemetry states, mapping individual model latencies, compiling historic system tracking feeds, and visual tags showing whether a chat answer was successful or a product of a fallback routing trigger.
Challenges we ran into
- Asynchronous Multi-Agent State Synchronization: Managing independent execution traces for separate agents (Orchestrator and Specialist) while simultaneously calculating performance metrics and updating tracking states over asynchronous network boundaries required strict event-loop handling.
- Kernel-Level Socket Deadlocks: During iterative testing and forced server terminations, we ran into persistent local networking issues where zombie Python processes held loopback interfaces hostaged at the OS kernel level. Debugging these environment mismatches taught us a massive lesson in clean socket management and explicit host bindings.
Accomplishments that we're proud of
We successfully achieved zero-downtime multi-agent execution under extreme chaos simulation. Even when our primary model pool is completely offline, the client-facing application never drops a request or returns a generic system failure. The backend cleanly down-routes traffic behind the scenes, ensuring the human operator experiences a consistent, continuous conversational flow.
What we learned
We learned how to apply classical engineering reliability equations to modern, non-deterministic AI pipelines. By treating our independent LLM providers as a system of parallel components, we can mathematically evaluate the system's runtime availability.
If our primary model has an independent reliability rate of R1, and our fallback model has a reliability rate of R2, the overall parallel configuration reliability Rsys is calculated using the formula:
$$R_{\text{sys}} = 1 - (1 - R_1)(1 - R_2)$$
For example, even if an aggressive network throttling event reduces our primary model's success rate to R1 = 0.70, backing it up with an isolated fallback channel operating at R2 = 0.90 elevates our total compound system reliability to:
$$R_{\text{sys}} = 1 - (0.30)(0.10) = 0.97$$
This mathematical certainty underscores why single-endpoint dependencies are an anti-pattern for enterprise agent deployments.
What's next for ResiliBot
- Predictive Latency Routing: Moving beyond reactive threshold fallbacks to proactive routing. By analyzing moving-average latency graphs over time, ResiliBot will predict provider degradation and shift traffic away before an API error is ever thrown.
- Self-Healing Agent Verification: Integrating automated reflection layers where agents can check if a provider's degraded response compromised the quality of the answer, allowing them to re-verify or self-correct via an alternate pipeline model.
Built With
- css3
- fastapi
- html5
- openai
- pydantic
- python
- react
- tailwindcss
- tavily
- truefoundry
- typescript
- vite

Log in or sign up for Devpost to join the conversation.