-
-
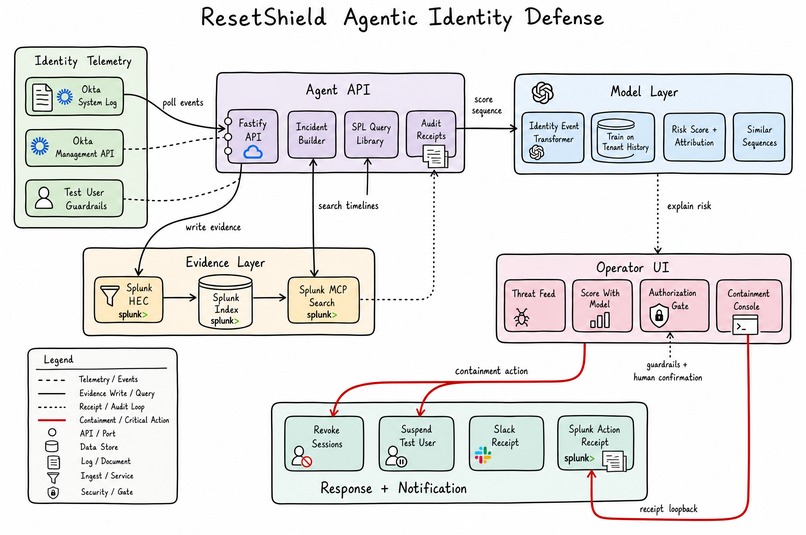
Architecture Diagram
-
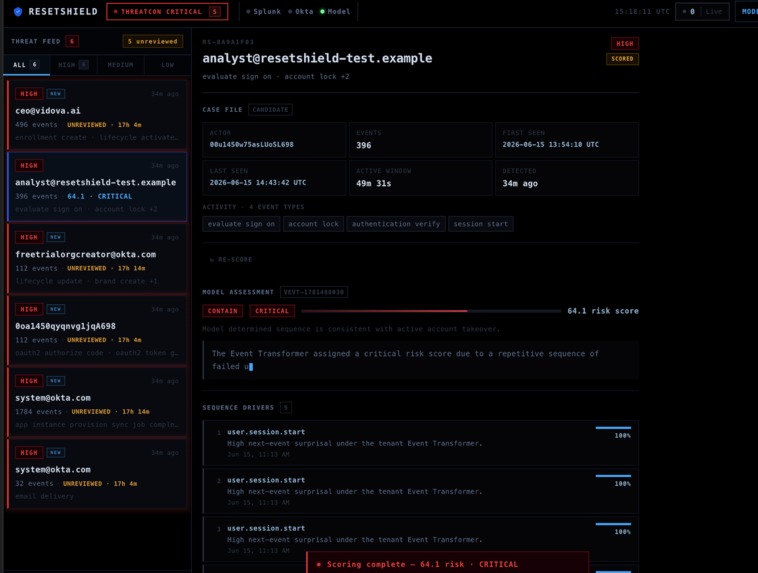
ResetShield Dashboard
-
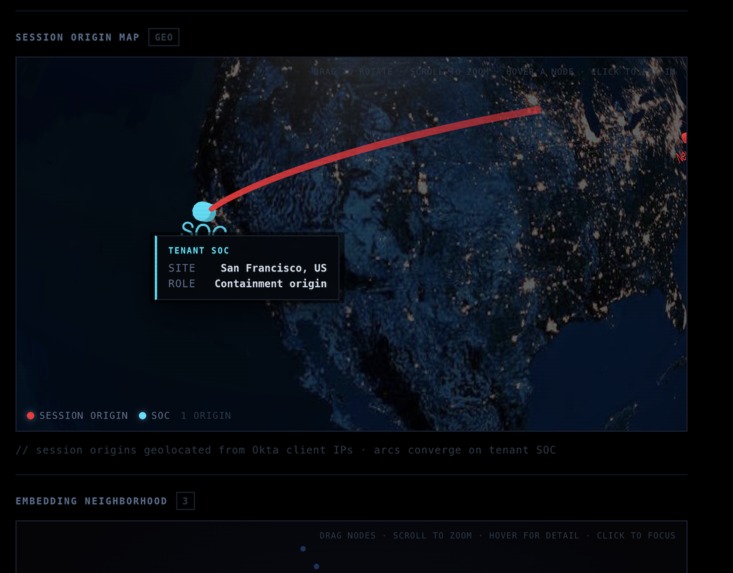
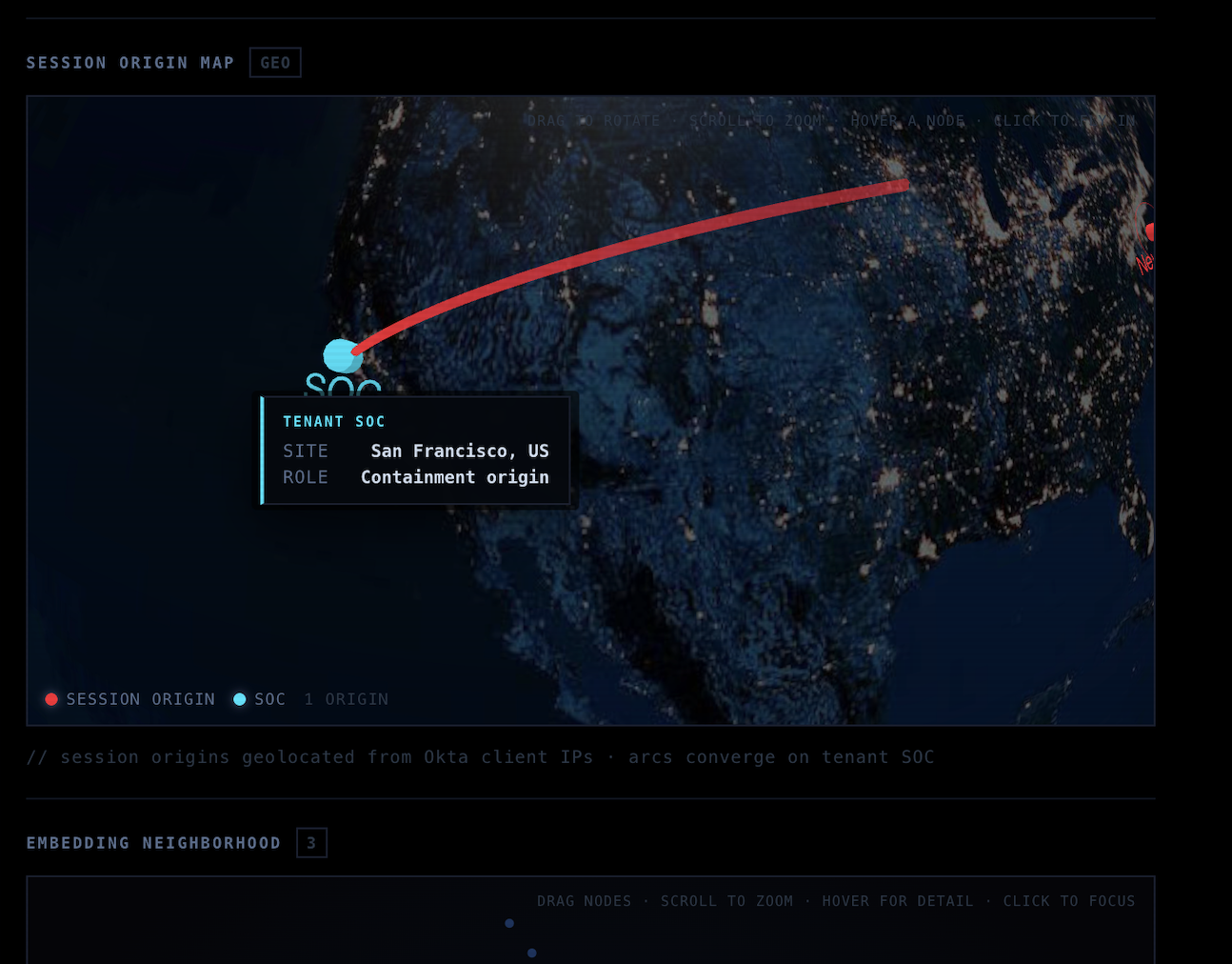
Origin Map
-

Embedding Graph

Inspiration
On September 10, 2023, an attacker affiliated with the ALPHV/BlackCat ransomware group made a 10-minute phone call to MGM Resorts' IT help desk. They used information pulled from LinkedIn to social-engineer a complete Okta MFA reset. No malware. No exploit. One phone call. What followed was nine days of operational outage across MGM's Las Vegas properties — slot machines offline, room keys not working, reservation systems down — and over $100 million in revenue impact.
The Okta System Log captured every step of that attack sequence before the attacker moved laterally: the successful authentication, the help-desk-initiated MFA reset, the new authenticator enrollment, the session from an unrecognized device. All of it was there. What was missing was a model that recognized the sequence as an anomaly before the blast radius grew.
The Identity Defined Security Alliance found that 84% of organizations experienced an identity-related breach in 2024. The pattern is consistent: phish a credential, call the help desk to reset MFA, enroll a new device, move laterally. Every step generates an Okta System Log event. None of the individual events are alarming in isolation. The threat lives in the sequence.
A complete situational picture under today's manual process takes 35–45 minutes to assemble. An MFA reset can precede lateral movement in under 10 minutes. We built ResetShield to close that gap.
What it does
ResetShield is a tenant-trained identity sequence detection and response system built on Splunk and Okta. It replaces the manual investigation runbook with an agentic pipeline that runs continuously and surfaces the attack before containment becomes damage control.
Detection. Okta System Log is polled every 30 seconds. Events are aggregated into incident candidates per user and time window, written to Splunk via HEC, and immediately available for scoring.
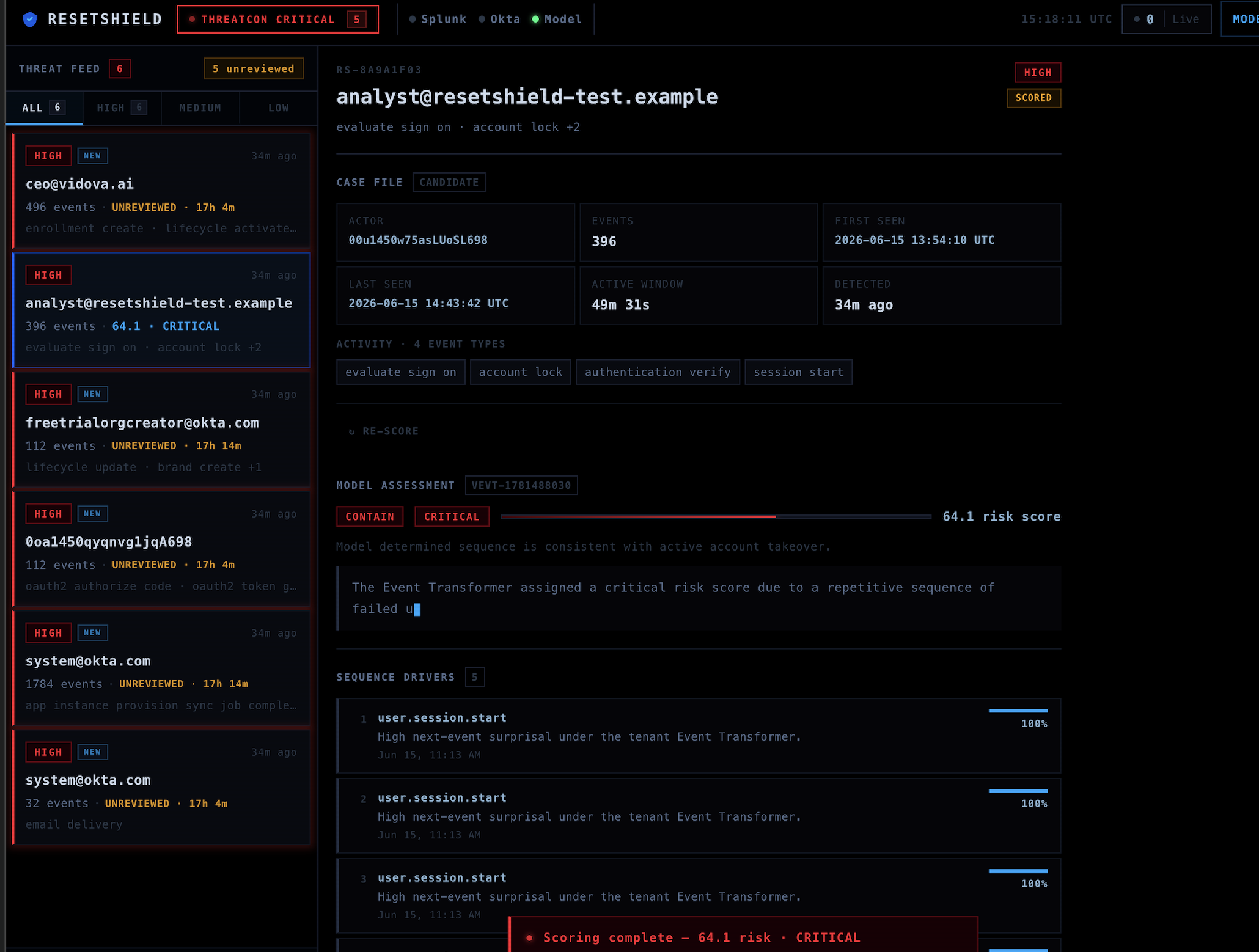
Scoring. The Identity Event Transformer — a purpose-built transformer model trained on the tenant's own Splunk/Okta history — scores the full event sequence against the behavioral baseline it learned. It produces:
- A continuous risk score in
[0, 1]calibrated against the tenant's training loss - A risk band:
low·elevated·high·critical - A recommended action:
none·human_review·contain_test_user - The top five events by per-event surprisal, with contribution percentages and reason text — not a black-box score, but the exact moments where the user's behavior stopped matching what the model learned
- The three closest training sequences by Jaccard distance, giving the analyst a reference for what normal looks like
Inference runs in under 35 ms.
Policy gate. Containment requires three independent checks simultaneously: model assessment ready, Okta guardrails passed (email suffix, profile marker, account state), and the analyst typing CONTAIN_RESETSHIELD_TEST_USER. None can be bypassed. There is no override path, no confidence threshold that triggers automatic action.
Execution. On authorization, ResetShield revokes all active sessions, suspends the account in Okta, and writes structured receipts to Splunk — all within seconds, with a full audit trail.
Feedback loop. After investigation, the analyst labels the incident (benign, suspicious, confirmed_takeover, false_positive). The label is stored against the attributed events — the exact sequence positions the model flagged as anomalous. The next training run incorporates those verdicts, tightening the model's understanding of what constitutes an attack for that specific tenant.
How we built it
ResetShield is a TypeScript monorepo with a Python ML service.
API layer (apps/api, Fastify + Zod): all investigation, training, containment, and model management routes. Strict schema validation at every boundary. Fails closed on any missing environment variable at startup.
ML service (ml-service, FastAPI + PyTorch): the Identity Event Transformer. Each Okta event is encoded into seven feature hashes (event type, outcome, country, user agent, proxy flag, target count, client IP) and fed through a 2-layer transformer encoder with 4 attention heads and a 64-dimensional model. Training uses per-user sliding windows so the model never mixes cross-user context. Risk score is calibrated via sigmoid against the tenant's own training loss — a sequence that scores near the training baseline lands near 0.5; a sequence significantly harder to predict pushes toward 1.0.
Splunk MCP as the only search path. Every SPL query — incident candidates, investigation events, training events, audit log, preflight correlation — goes through the configured Splunk MCP search tool. There is no native SDK search client. Every query is traced to Splunk as resetshield:agent_trace and shown in the UI's collapsible Splunk Queries panel. No query runs silently.
Okta integration (packages/okta): System Log polling, guardrail evaluation, session revocation, account suspension. The guardrail chain checks email suffix, profile marker field and value, and account state before any write operation.
React operator UI (apps/web): SOC terminal aesthetic — dark canvas, animated network threat visualization, live threat feed, assessment panel with attribution breakdown, policy gate status, confirmation input, and full audit trail. Built with React 18 and HTML5 Canvas.
Validation. The model was validated against the LANL Comprehensive Multi-Source Cyber-Security Events dataset — 1.6 billion real enterprise authentication events with ground-truth red team labels. Trained on 2,123 normal events from 591 users, the model scored a red-team-compromised sequence it had never seen as 0.706 / high / human_review based solely on the anomalous burst pattern of lateral movement authentications relative to the learned baseline.
Challenges we ran into
Calibrating risk score across training runs. A raw mean surprisal is meaningless without a reference point. Anchoring to the training loss via sigmoid means the score is always relative to what that tenant considers normal — but getting the calibration stable across epochs required fixing the scale to the final training epoch mean rather than a rolling average.
Fail-closed by design. Every dependency failure had to surface as a hard error, not a silent fallback. No demo mode, no seeded data, no synthetic scores. If the ML service artifact is missing, scoring fails. If the MCP tool name is ambiguous, investigation fails. If Okta guardrails return anything unexpected, containment is blocked. Building a system that tells you exactly what went wrong — instead of silently degrading — required discipline at every layer.
MCP as the only search path. Committing to MCP-only for all Splunk queries meant there was no fallback SDK to lean on during development. Every query had to work through the MCP tool interface, with the tool name and query argument configurable by environment. The upside: every query is observable, traceable, and auditable.
Policy gate design. The three-check policy gate — model readiness, Okta guardrails, human confirmation — had to be genuinely independent. Early designs let a passing model recommendation implicitly satisfy the guardrail check. The final design evaluates each condition as a separate boolean, with the UI surfacing exactly which check is blocking and why.
Accomplishments that we're proud of
LANL red team validation. The model scored a known attacker sequence as high risk — trained only on normal behavior, with red team events held out — based on the burst pattern of lateral movement authentications. That is the exact detection the MGM attack required.
Sub-35ms inference. A 24-event sequence scores in a mean of 31.3 ms (P95: 35 ms). Fast enough to run on every incident candidate as events arrive.
Tenant-trained baseline. The model learns what normal looks like for your organization, not a generic user population. An event sequence that would be anomalous at one tenant might be routine at another. ResetShield's risk score reflects the specific behavioral history in your Splunk index.
Full audit trail. Every SPL query, every model assessment, every policy gate evaluation, every containment receipt is written to Splunk. The investigation is fully reproducible from the resetshield:agent_trace index.
No override path. The policy gate has no admin bypass, no confidence threshold that auto-triggers containment, and no demo mode. The analyst types a confirmation string every time, for every containment. That is a feature.
What we learned
Rules-based SIEM detection fails on identity threats for a structural reason: the signal is in the sequence, not the individual event. A password reset is not an attack. A new authenticator enrollment is not an attack. The attack is the combination — the specific ordering of events a legitimate user almost never produces. A threshold rule would need to enumerate every meaningful combination, separately for every tenant. A sequence model learns the boundary from the tenant's own history.
Per-event surprisal is more useful than a single aggregate score. Returning the top attribution events — the specific moments where the sequence diverged from predictions — turns a risk score into an investigation starting point. The analyst sees not just "this is risky" but "this MFA reset followed by this new device enrollment from this geography is what pushed the score into critical."
Splunk MCP is a genuinely useful agentic interface. Treating MCP as the only search path — rather than one option among several — forced us to build a clean tool contract, made every query observable, and meant the system works the same way in the local lab as in a live deployment.
What's next for ResetShield: Agentic Okta Takeover Detection with Splunk
- Production guardrail tier. The current guardrail chain is scoped to a single configured test user. The next step is a production-safe guardrail tier with role-based authorization, multi-user scope, and an approval workflow before any write to Okta.
- Continuous retraining. Trigger incremental retraining as new analyst feedback accumulates, rather than requiring a manual training run. The feedback loop is already wired; the missing piece is the scheduler.
- Broader identity provider support. The event encoding and sequence model are provider-agnostic. Extending to Entra ID, Ping, or other SAML/OIDC providers means adapting the ingestion and normalization layer while keeping the ML architecture intact.
- Cross-user sequence correlation. The current model scores individual user sequences in isolation. Correlating anomalous sequences across users — detecting coordinated credential attacks — is the next frontier for the detection engine.
- Richer attribution UI. Surfacing per-event surprisal as a timeline visualization, with geo and device context inline, would give analysts a faster path from score to understanding to decision.
Built With
- fastapi
- fastify
- okta-api
- python
- pytorch
- react
- slack
- splunk-hec
- splunk-mcp-server
- typescript

Log in or sign up for Devpost to join the conversation.