-
-

Home page
-
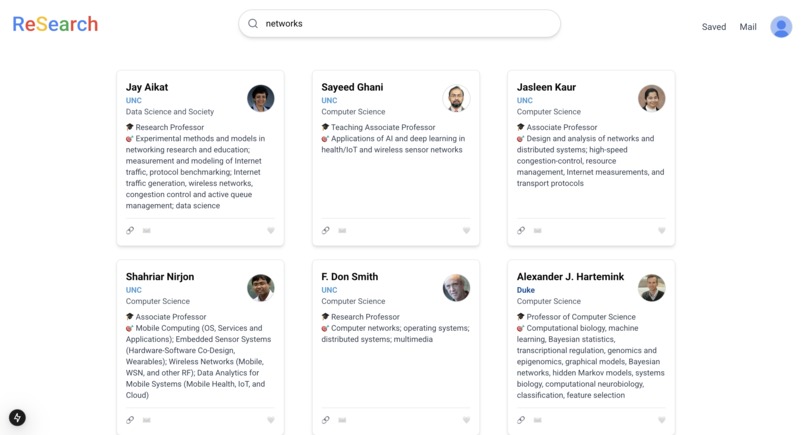
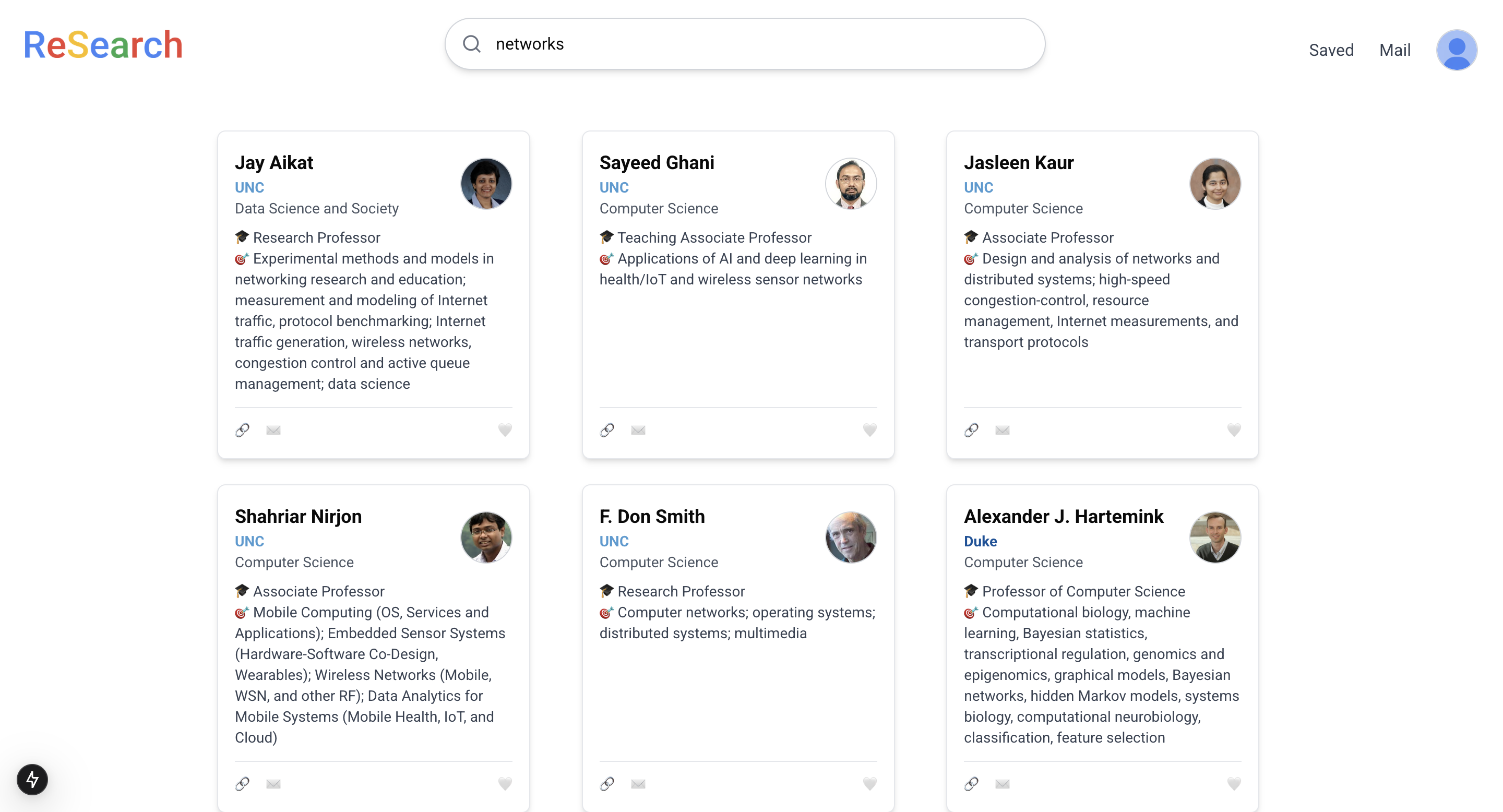
Professor search
-
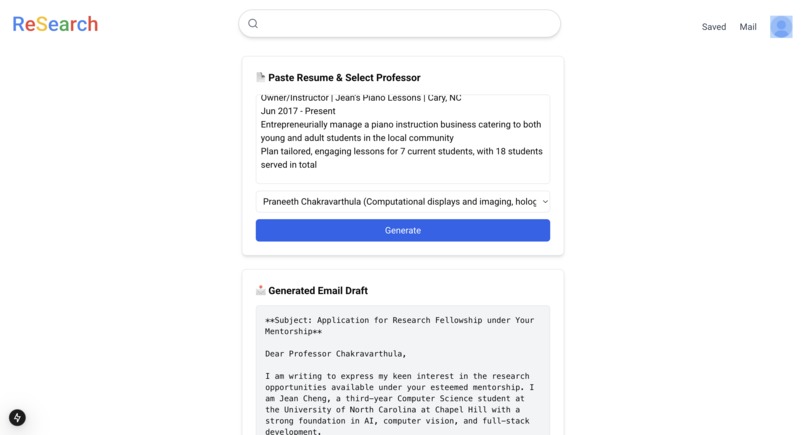
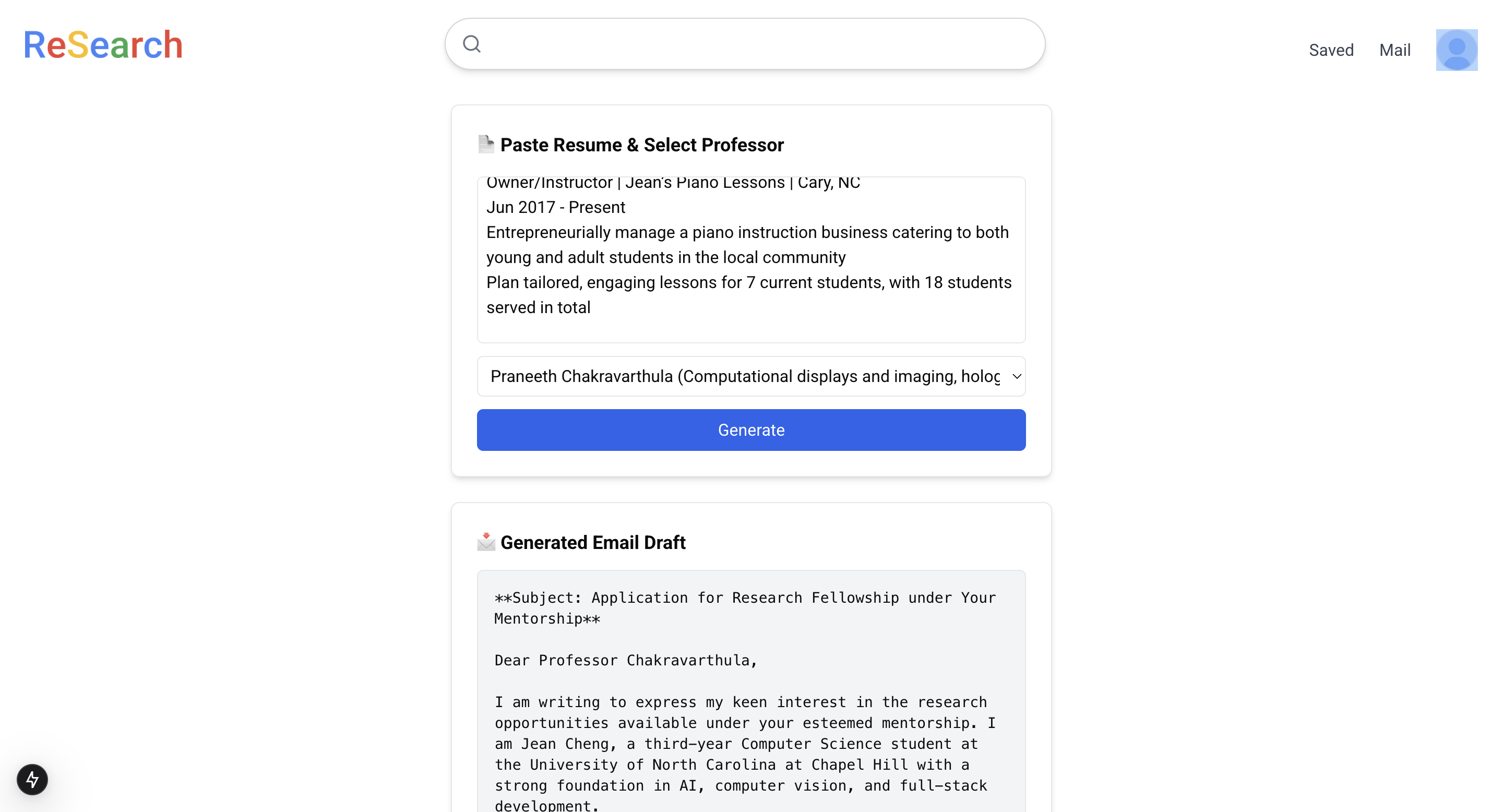
Email draft generation

Inspiration
As computer science students in North Carolina’s Research Triangle, we’ve experienced how challenging it can be to find research opportunities across different universities. With each school hosting separate departmental pages and faculty sites, the process of identifying potential research mentors is often time-consuming. To solve this, we created ReSearch, a centralized platform that helps students easily discover, save, and connect with professors based on their research interests to foster research connections and cross-campus collaboration.
What it does
ReSearch simplifies the process of finding Computer Science professors at UNC, NC State, and Duke by:
- Allowing users to search by name, university, department, title, and research area.
- Providing a unified platform with faculty details like contact info, research interests, and department.
- Letting users save favorite professors for easy access later.
- Offering one-click access to lab websites for further research.
- Adding a feature that allows users to upload a text version of their resume and select from a dropdown of their saved professors. The platform then generates a draft email to that professor based on the user’s resume and the professor’s research areas, making it easier to reach out with personalized content.
- Enabling quick email communication via a direct email icon.
How we built it
- Frontend: Built with React and Next.js to ensure a dynamic, responsive user experience.
- Styling: Tailwind CSS for a modern, user-friendly interface.
- Backend: Implemented with Node.js and Express, providing a fast and scalable API.
- Database & Search: Stored professor details in a MySQL database, efficiently filtering by name, university, and research interest for quick results.
- Web Scraping: Used Python and Beautiful Soup to collect and structure professor data from the faculty webpages of UNC, NC State, and Duke.
- Draft Email Feature: Integrated the Gemini API to analyze the user’s resume and the professor’s research areas, generating an appropriate draft email that the user can further personalize.
Challenges we ran into
We initially faced challenges in developing our web scraping script in Python, as none of us had prior experience with the Beautiful Soup package. Integrating the scraped data into our MySQL database was another challenge, requiring us to modify our approach to data extraction. Additionally, we encountered difficulties in establishing a seamless connection between our database and the backend GET route, which retrieves professor information. We also faced challenges integrating the Gemini API into our application as none of us have had experience doing this. Through trial and error as well as mentor help, we were able to overcome these issues and improve our understanding of web scraping and backend integration.
Accomplishments that we're proud of
We successfully built a full-stack application that centralizes professor data from multiple university websites, allowing students to easily search by professor name, school, or research interest. Throughout the process, we gained valuable experience in web scraping with Python, database management with MySQL, and backend development with Express and Node.js. Additionally, we strengthened our understanding of the React framework and improved our ability to create a user-friendly interface with Next.js and Tailwind CSS. More importantly, we honed our teamwork skills, learning how to effectively collaborate, communicate, and delegate tasks to ensure smooth development and efficient problem-solving.
What we learned
Throughout this project, we gained valuable experience in full-stack development. One of our biggest learning experiences was working with web scraping using Python’s Beautiful Soup. Since none of us had prior experience with this, we had to figure out how to extract and structure professor data from different university websites while handling inconsistencies in formatting. Beyond the technical skills, we learned the importance of effective teamwork and communication. We divided tasks based on our strengths, collaborated to solve challenges, and continuously iterated on our design based on feedback.
What's next for ReSearch
Moving forward, we plan to enhance ReSearch by expanding its database to include research professors in more fields of study beyond just computer science such as Biology, Linguistics, and Statistics, making it an even more valuable resource for students in the Research Triangle and beyond. Lastly, we’re also considering implementing a user authentication system, allowing students to create accounts, save their favorite professors more securely, and track their past searches for easier access.
Built With
- api
- beautiful-soup
- gemini
- mysql
- next.js
- python
- react
- tailwind
- typescript






Log in or sign up for Devpost to join the conversation.