-
-

loading page
-
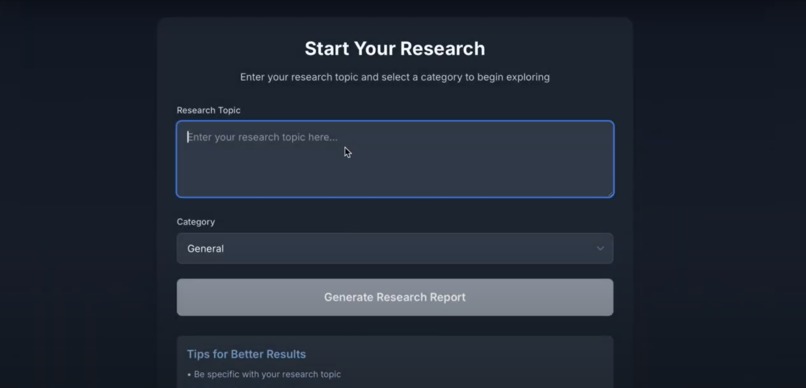
type in
-

Home page
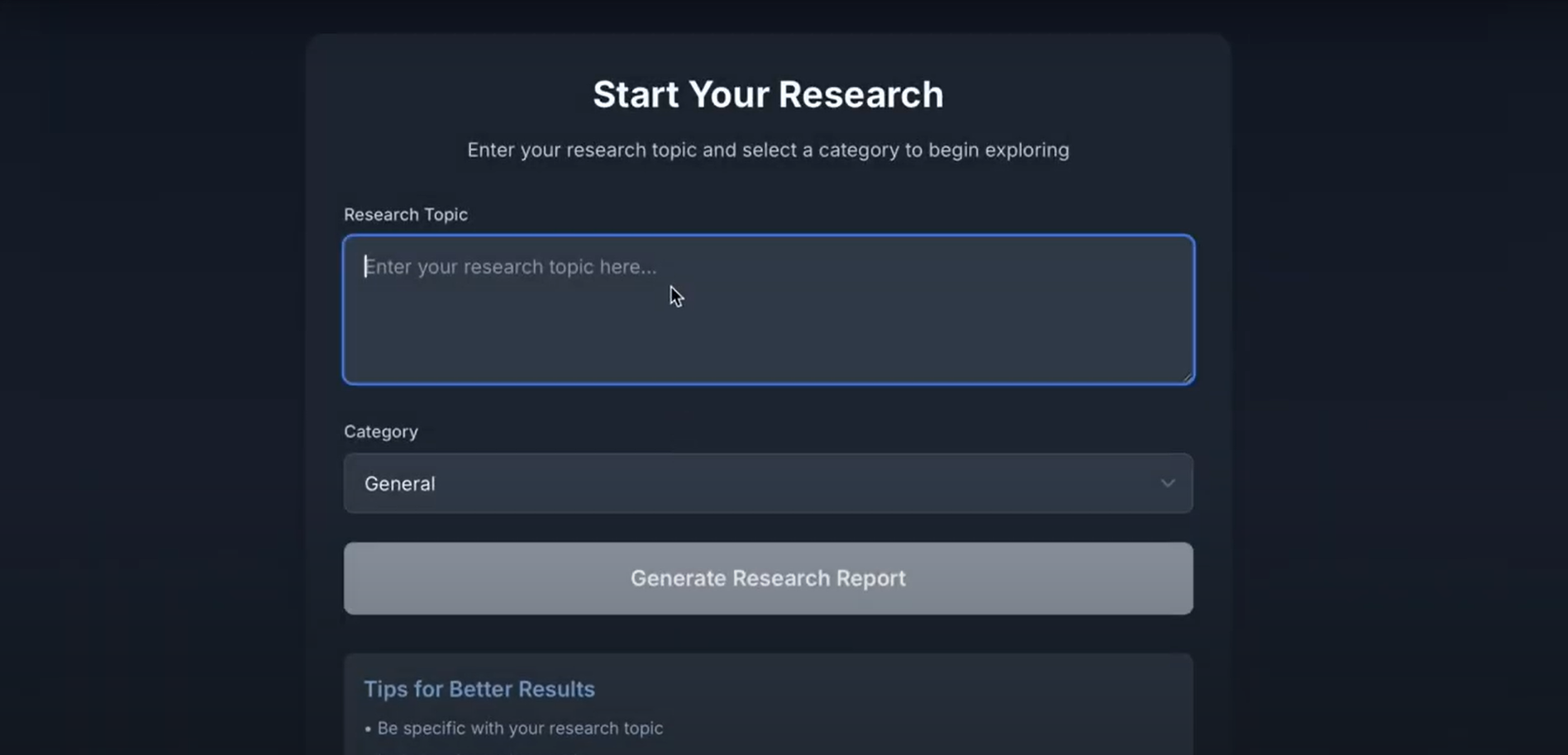

Inspiration
Our inspiration comes from the need to make research more accessible and efficient. In today's fast-paced world, finding accurate and reliable information can be time-consuming. We wanted to create a tool that streamlines the research process by automatically gathering relevant content, saving users time while ensuring they receive up-to-date, comprehensive result.
What it does
Research Rover is a web scraping tool that allows users to input a research topic and receive a well-organized research paper on that topic. By leveraging open-source and languages like Python, JavaScript, TypeScript, and CSS, the platform automatically collects relevant content from the web, processes it, and compiles the information into a comprehensive document. It simplifies the research process by quickly providing users with curated, topic-specific papers based on the latest available online resources.
How we built it
We built Research Rover by combining several powerful technologies to create a seamless and efficient experience for our users.
Web Scraping with Python: The backbone of our project is Python, which we used for its powerful web scraping libraries. These tools allow us to gather relevant data from various websites, extracting meaningful content based on the user's research query.
Front-End with JavaScript & TypeScript: To ensure an interactive and responsive user interface, we used JavaScript and TypeScript. JavaScript handles dynamic content loading and real-time updates, while TypeScript improves the scalability and maintainability of the code by adding type safety and structure to our front-end.
Styling with CSS: The design of our platform is simple, intuitive, and clean, built with CSS to ensure a smooth and pleasant user experience. We focused on making the interface easy to navigate, keeping the user in mind at every step.
Data Processing and Output: Once the data is scraped, we process and organize it into a structured format. The information is then compiled into a well-formatted research paper, providing users with clear, relevant insights on their chosen topic.
Challenges we ran into
Data Accuracy and Relevance: One of the biggest challenges was ensuring the accuracy and relevance of the scraped data. Not all web content is reliable or well-structured, and we had to develop effective filtering methods to ensure that only high-quality, relevant content made it into the final research paper.
Formatting the Output: Converting the raw scraped data into a polished, well-structured research paper was a challenging task. We needed to ensure that the output was not only informative but also easy to read and visually appealing, which required a significant amount of data processing and formatting.
Maintaining Performance and Scalability: As the platform grew, we had to ensure that our system could handle large volumes of data and multiple simultaneous requests without crashing or slowing down. This required optimizing both our backend code and database management to ensure smooth performance.
Accomplishments that we're proud of
Automated Research Paper Generation: The core feature of automatically generating a well-structured research paper is something we're particularly proud of. It compiles and organizes the gathered data into a readable format, saving users time and effort compared to traditional research methods.
Handling Complex Data Sources: We successfully tackled the challenge of scraping dynamic and complex websites, ensuring that we could extract and process data from a wide range of content types.
Open-Source Contribution: We’re proud to contribute to the open-source community by leveraging open-source tools and technologies. This project not only solves a real problem but also promotes the use of shared resources for continuous improvement and innovation.
Scalability and Performance: We've optimized the backend to handle multiple requests efficiently, ensuring that our platform scales as more users engage with it. The system performs reliably, even with a high volume of data scraping and processing tasks.
What we learned
The Power of Open-Source: Working with open-source libraries and frameworks made us appreciate the community-driven nature of software development. We learned how to collaborate with existing tools and contribute back to the open-source ecosystem, which enriched the project and accelerated development.
User-Centered Design: We learned that building a tool that is intuitive and user-friendly requires continuous feedback and iteration. By focusing on the needs of our users, we created a platform that simplifies the research process while making it easy for non-technical users to interact with complex technology.
Dealing with Unstructured Data: Scraping data from a variety of sources often means dealing with unstructured or inconsistent formats. We learned how to clean and organize raw data into a useful format that can be transformed into something meaningful and well-structured, like a research paper.
Frontend & Backend Integration: Integrating the backend scraping process with the frontend user interface taught us a lot about full-stack development. We learned how to ensure smooth communication between the Python-based backend and the JavaScript/TypeScript frontend, maintaining a seamless and responsive user experience
What's next for Research Rover
Multilingual Support: To make Research Rover more accessible to users worldwide, we're working on adding multilingual support. This will allow the tool to process and scrape content from websites in different languages, making it useful to a global audience.
User-Generated Content and Feedback: We plan to introduce features where users can add their own content or feedback into the research papers. This could help create a more interactive and collaborative experience where the community contributes to refining and expanding the research.
Topic Personalization: We aim to add a feature that allows users to personalize their research papers further. For example, based on user preferences or previous searches, the system could tailor recommendations or include more specific sources, helping users dive deeper into their topic of interest.



Log in or sign up for Devpost to join the conversation.