-
-
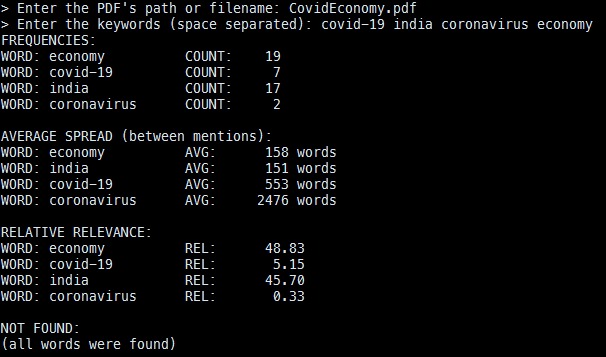
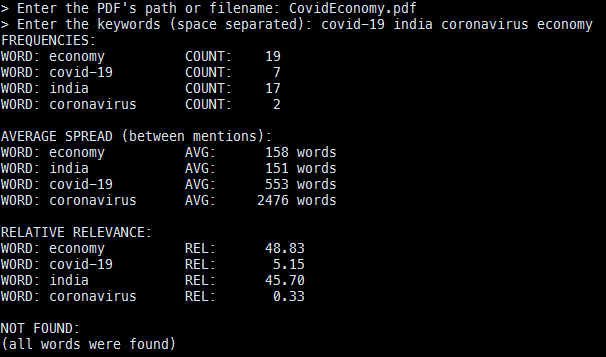
Paper: "Livestock a Boon for Self Reliance to Indian Economy in COVID-19 Pandemic"
-
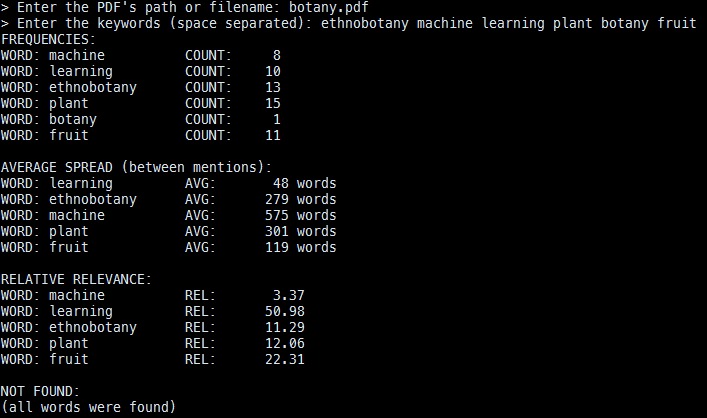
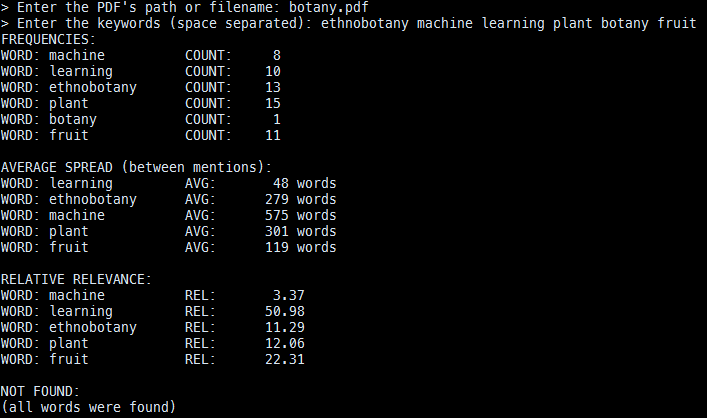
Paper: "Machine Learning in Ethnobotany"
Inspiration
Ben Rubera:
"I work at a research lab where I constantly have to read a lot of papers pertaining to certain topics. Reading through individual papers is time consuming and might not provide the relevant information for my research. I created the script so I can easily get a relevance score of my paper and from that estimate how useful that paper will be."
What it does
Our program is used to give an estimation of how relevant a research paper is based on constraints or keywords provided by the user. The program receives two inputs, a pdf file and a list of keywords. The paper is then scanned for those keywords. The average number of words between between each consecutive pair of keywords is then calculated. The shorter the distance between certain keywords, the closer they appear in that file and are therefore considered to not be a main focus of the research paper. However, the longer the distance between the keywords, the more “spread out” the words are throughout the paper and therefore are more likely to be part of the main thesis of the paper. To calculate the percentage relevance of the paper, the frequency of a keyword is divided by the average distance between two consecutive keywords. This is then divided by the total frequency to get a percentage relevance.
How I built it
We decided to stick with just pure python scripts.
Challenges I ran into
How do you convert a pdf file into something usable by the program?
Once you have the average spread of the words and the frequency for each one, how do you determine how relevant it is to the paper?
Accomplishments that I'm proud of
We're glad that we could complete the program (even if there's room for improvement), and that we built a tool that is useful to us.
What I learned
We tried to make a GUI for the program but unfortunately didn't have time to finish it. Even so, we still learned the basics of making a GUI with python using tkinter.
What's next for Research PaperScanner
The way we evaluate the papers is not perfect. The program can only handle single word terms. So for example, you can search for "machine" and "learning" but not for "machine learning" as one unit. In the future, we could make this possible and also come up with better ways to evaluate the papers.

Log in or sign up for Devpost to join the conversation.