-
-
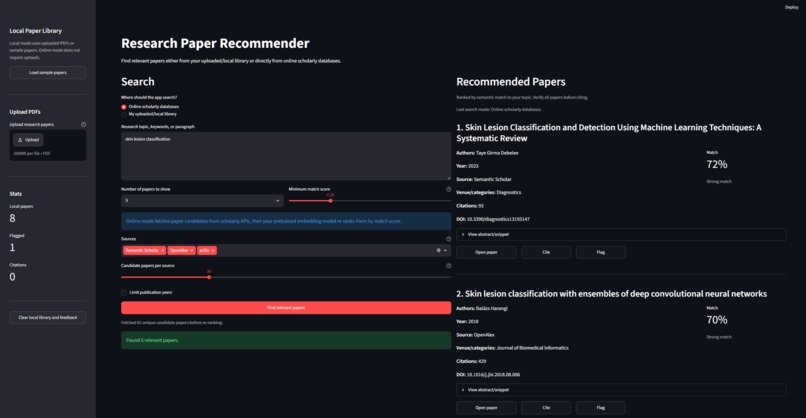
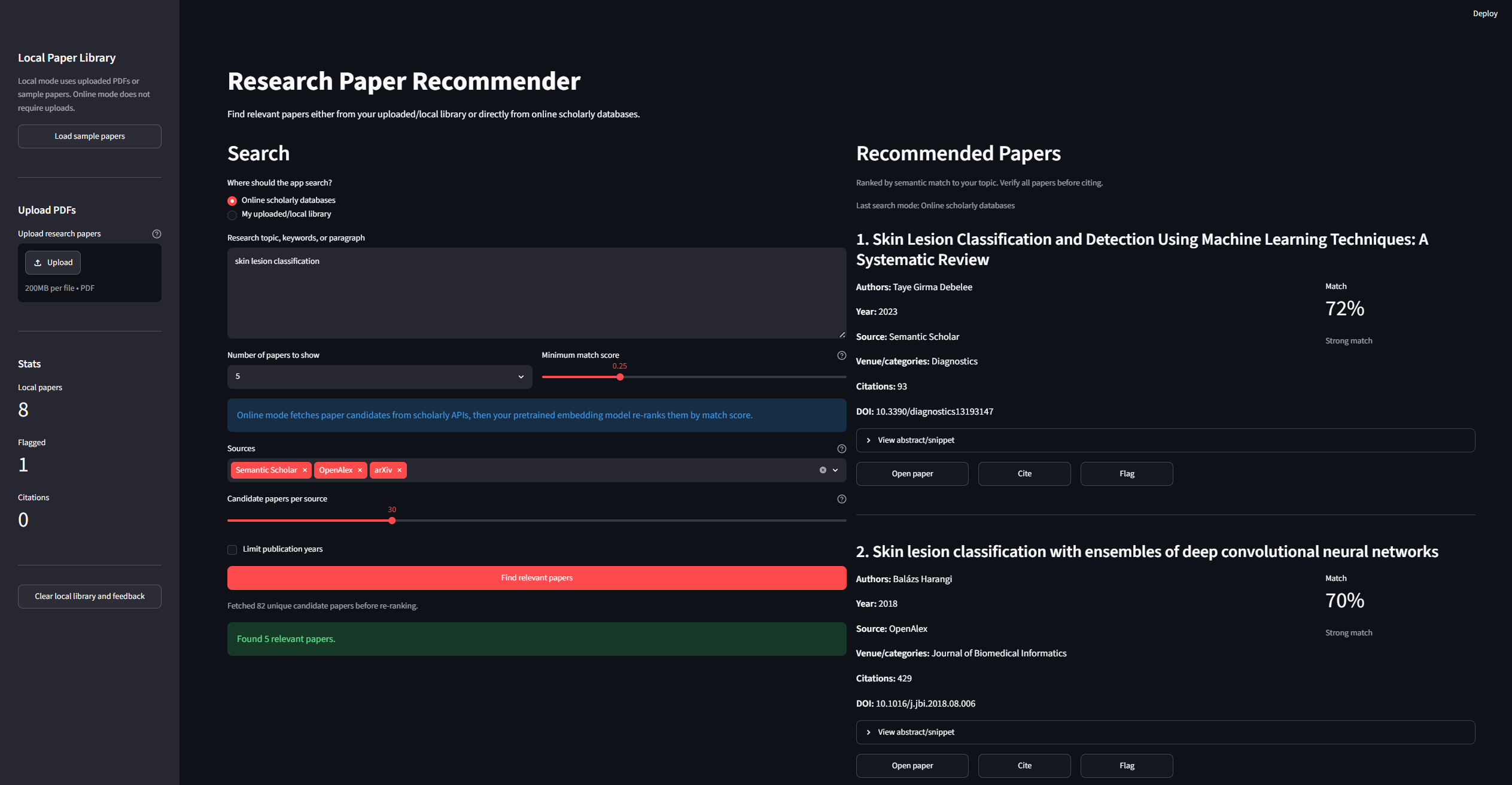
Web Interface of Research Paper Recommender
-
Clicked on 2nd "Open Paper" to get to this page
Inspiration
Researchers often spend hours searching for useful papers before they can start working on their actual research idea. They need to search across different platforms, read many abstracts, compare relevance, and save useful references manually. This process takes a lot of time and can be frustrating, especially for students and early-stage researchers.
Our inspiration came from this problem. We wanted to build a tool that helps researchers quickly discover papers related to their topic, so they can spend more time understanding and building their research instead of spending most of their time searching.
What it does
Research Paper Recommender Online is an AI-powered tool that recommends relevant research papers based on a topic entered by the user.
The user simply types a research topic, and the system searches scholarly sources such as Semantic Scholar, OpenAlex, arXiv, and optionally Google Scholar through SerpApi. It then ranks the papers based on how closely they match the user’s topic.
The app shows useful details such as the paper title, authors, publication year, source, abstract, citation count, DOI or paper link, and a matching score. The project also supports a local library mode where users can upload their own PDF papers and search within them.
How we built it
We built the project using Python and Streamlit. Streamlit was used to create the web interface where users can enter a research topic, upload PDF papers, and view recommended results.
For the recommendation system, we used the pretrained SentenceTransformer model all-MiniLM-L6-v2. This model converts the user’s topic and paper information into semantic embeddings. These embeddings help the system understand the meaning of the topic instead of only matching keywords.
We used FAISS for fast similarity search and ranking. FAISS compares the user query embedding with the paper embeddings and returns the most relevant papers. For online paper discovery, we integrated APIs such as Semantic Scholar, OpenAlex, arXiv, and optional Google Scholar results through SerpApi. For uploaded PDFs, we used pdfplumber and PyPDF2 to extract text from research papers.
Challenges we ran into
One of the main challenges was handling PDF uploads correctly. At first, the app kept processing the same uploaded paper multiple times because Streamlit reruns the script whenever the page updates. We solved this by adding duplicate checking and changing the upload flow so the same paper is not added repeatedly.
Another challenge was combining results from different scholarly sources because each API returns data in a different format. We had to clean and standardize the results so that every paper could be shown with title, authors, year, abstract, source, and link.
We also had to make sure the recommendation score was meaningful. Instead of using simple keyword matching, we used semantic embeddings so that the system can recommend papers even when the exact words are different but the meaning is similar.
Accomplishments that we're proud of
We are proud that we built a working research paper recommendation system that can help researchers save time. The user can enter a topic and quickly receive ranked paper suggestions from multiple scholarly sources.
We are also proud that the project supports both online paper search and local PDF library search. This makes the tool useful for discovering new papers as well as searching through papers that the user already has.
Another accomplishment is that we implemented semantic ranking using a pretrained AI model and FAISS, which makes the recommendations more intelligent than normal keyword-based search.
What we learned
We learned how semantic search works and how embeddings can be used to compare the meaning of text. We also learned how to use pretrained NLP models such as SentenceTransformers for real-world recommendation tasks.
We learned how FAISS helps with fast similarity search and how external scholarly APIs can be connected to a Python application. We also learned more about Streamlit, PDF text extraction, API integration, and handling duplicate data in a local library.
Most importantly, we learned how to turn a real research problem into a practical AI-based solution.
What's next for Research Paper Recommender Online
In the future, we want to improve the project by adding more advanced filters such as publication year, citation count, research field, journal name, and conference name.
We also want to add automatic paper summarization, citation export in BibTeX and APA formats, saved reading lists, and a related-paper graph that shows how papers are connected.
Another future improvement is to use research-specific models such as SPECTER or SPECTER2 for better scientific paper recommendations. We also plan to improve the user interface and deploy the project online so researchers can use it easily from anywhere.



Log in or sign up for Devpost to join the conversation.