Inspiration
The vast amount of academic research available today is both a treasure trove of knowledge and a challenge to navigate. We wanted to create a tool that empowers researchers by streamlining the discovery process, automating data handling, and providing relevant insights at the right time. The goal was to make academic exploration as efficient and insightful as possible, allowing researchers to focus on their work without getting bogged down in tedious data searches.
What it does
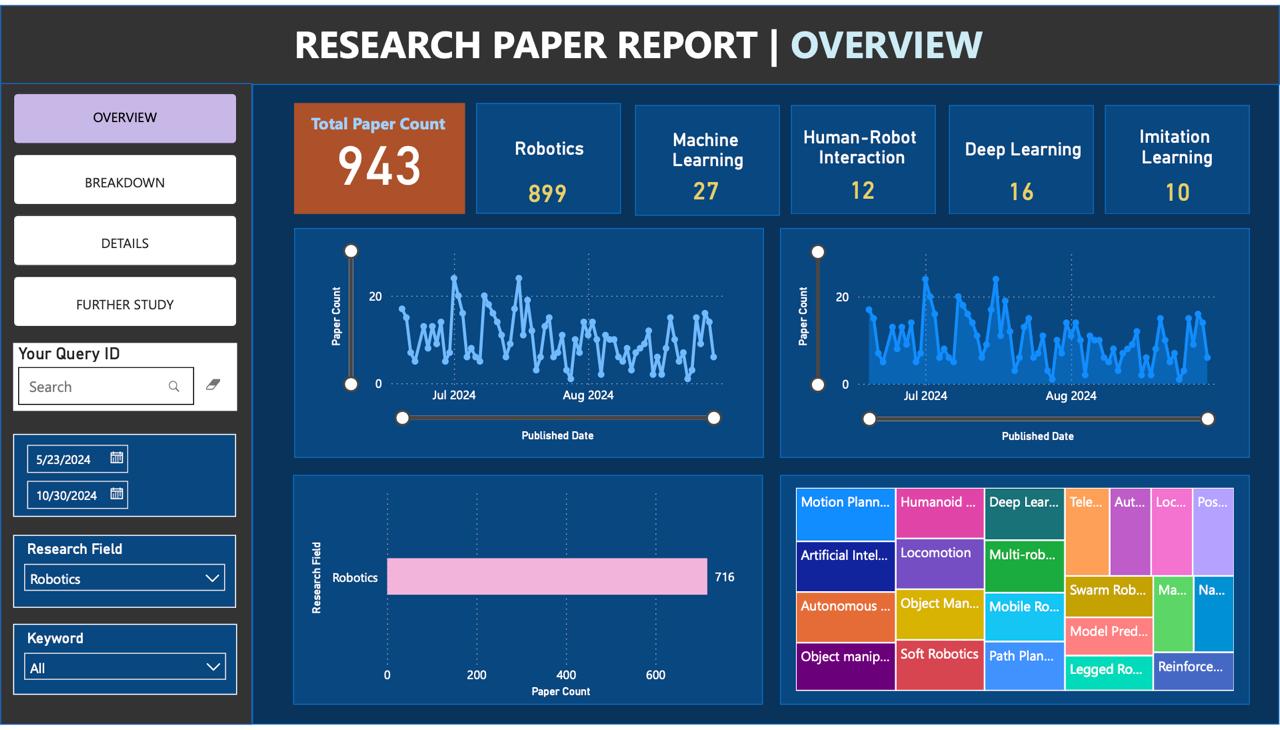
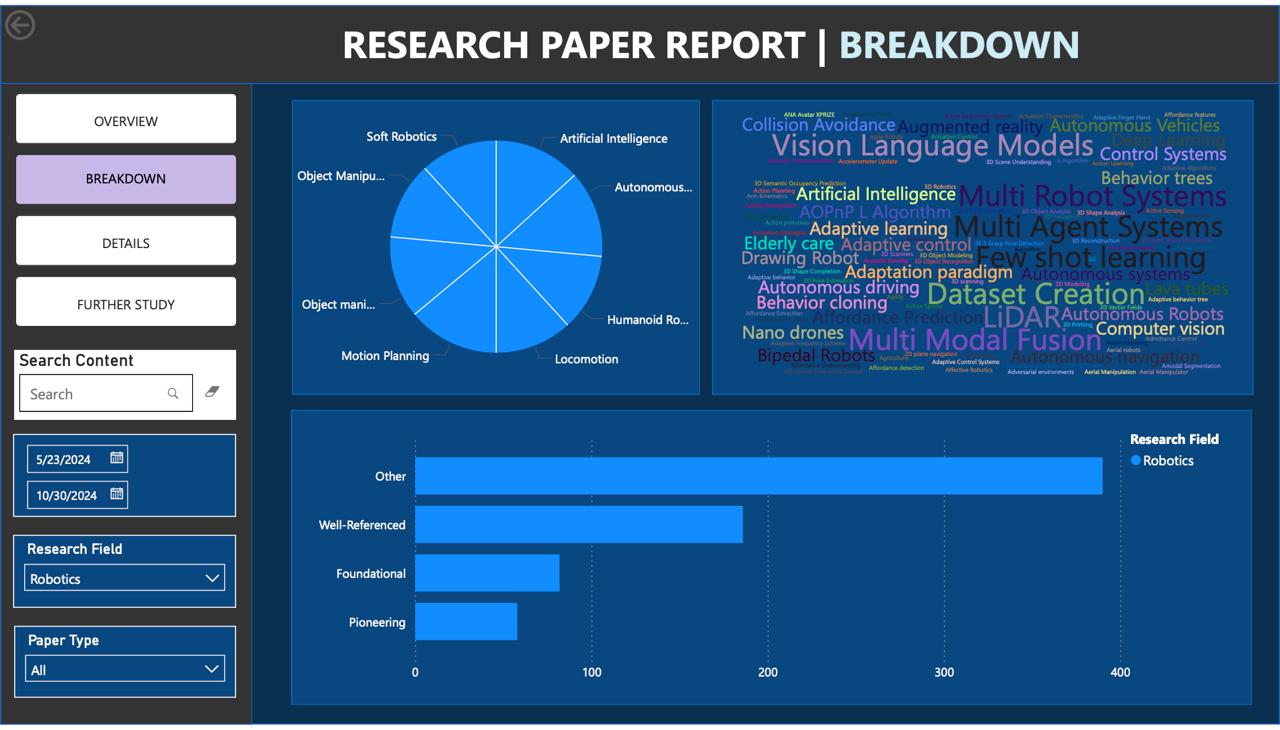
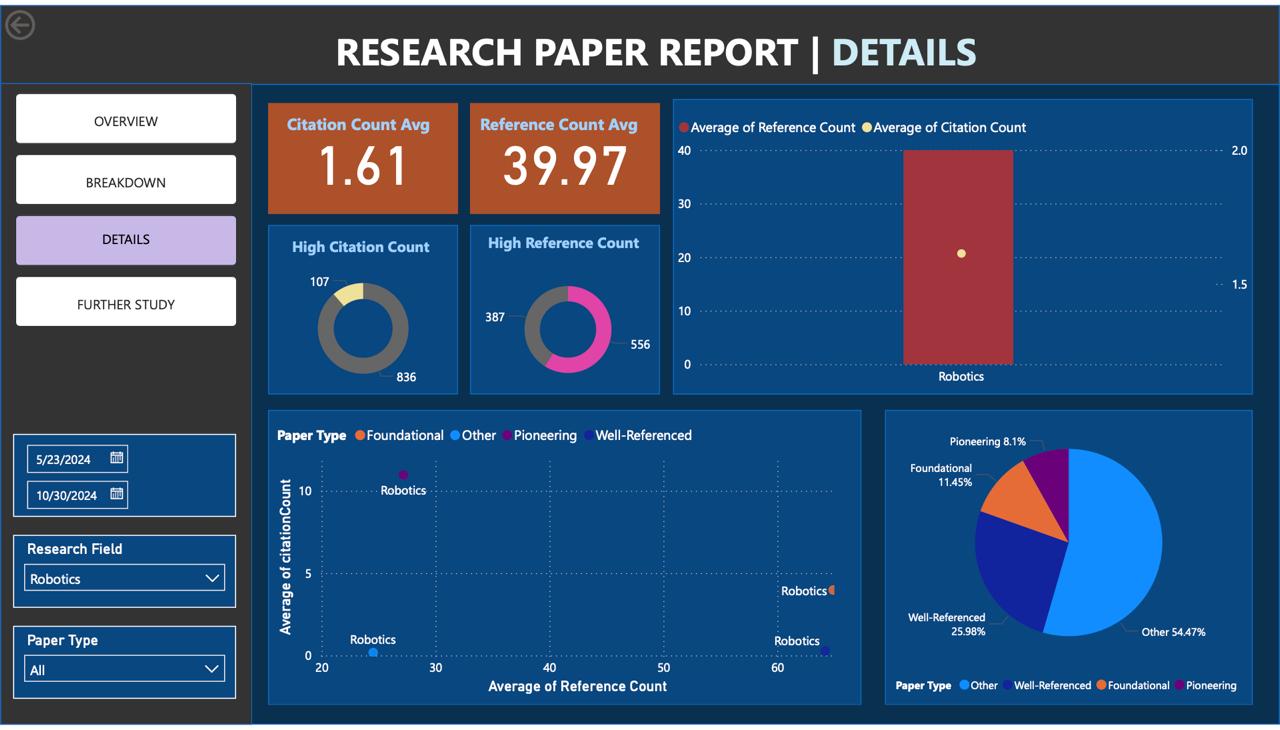
Research of Research is an automated platform that manages research queries, gathers and organizes relevant research data, and delivers actionable insights directly to users. Leveraging multiple APIs and AI-driven tagging, the system fetches, processes, and enriches metadata from scholarly databases. It updates reports dynamically in Power BI and sends them to users, ensuring they have access to the latest academic insights. Additionally, the platform continuously updates its AI-powered search index, making it a powerful tool for discovering new information with ease.
How we built it
The platform is built with a modular architecture, combining technologies like Flask, CosmosDB, and Azure functions for efficient data handling. The main components include: • Data Retrieval: Using Arxiv and Semantic Scholar APIs to fetch research paper metadata. • Concurrent Processing: Managed by arxiv_search_master, which runs arxiv_search and arxiv_tag tasks in parallel for faster data processing. • Lakehouse Storage: Storing raw metadata in the Bronze Lakehouse, processed and tagged data in the Silver Lakehouse, and formatted data for Power BI in the Gold Lakehouse. • Power BI and Automation: Power Automate handles dataset refreshes, report generation, and automated email notifications to users. • AI-Driven Search: An AI-powered search index, updated through CosmosDB indexers, ensures users can access the latest research results.
Challenges we ran into
One of the main challenges was ensuring seamless integration between multiple APIs and handling large volumes of data concurrently. Managing data flow from Bronze to Silver to Gold Lakehouses while maintaining data integrity and performance was another hurdle. Ensuring that the AI-driven tagging and search index updates were accurate and efficient required substantial testing and tuning.
Accomplishments that we're proud of
We’re proud of building a system that automates the end-to-end research discovery process, making academic insights accessible with minimal effort from users. Successfully integrating concurrent processing with multi-layered data storage and automated reporting has allowed us to create a solution that feels both robust and responsive. Our AI-powered tagging and search indexing functions have also demonstrated significant improvement in the relevance of search results, which was a major milestone for us.
What we learned
This project taught us a lot about managing complex data workflows and the importance of modular design for scalability. We deepened our understanding of API integration, concurrency management, and data lakehouse architectures. Working with Power Automate for seamless user notifications and report automation was also a valuable experience, helping us appreciate the power of automated workflows in reducing manual effort.
What's next for Research Of Research
Moving forward, we aim to enhance the platform’s AI capabilities by incorporating more advanced natural language processing for better topic suggestion and tagging accuracy. We also plan to expand the data sources beyond Arxiv and Semantic Scholar to provide a more comprehensive research experience. Additionally, implementing user personalization features and an interactive dashboard could make the system even more intuitive and tailored to individual research needs.
Built With
- azure-ai-search
- azure-openai
- cosmosdb
- fabric
- flask
- javascript
- power-automate
- powerbi
- python



Log in or sign up for Devpost to join the conversation.