-
-
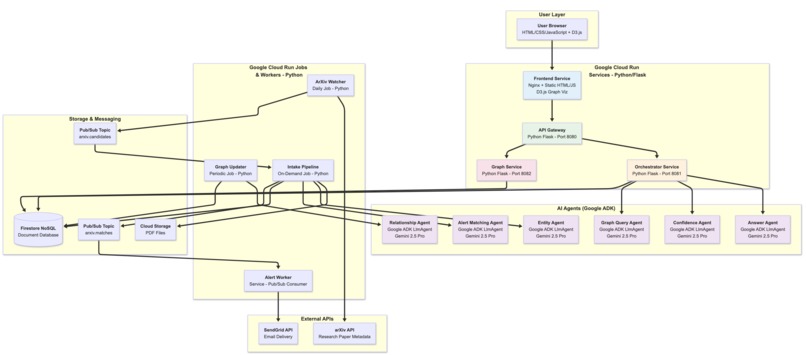
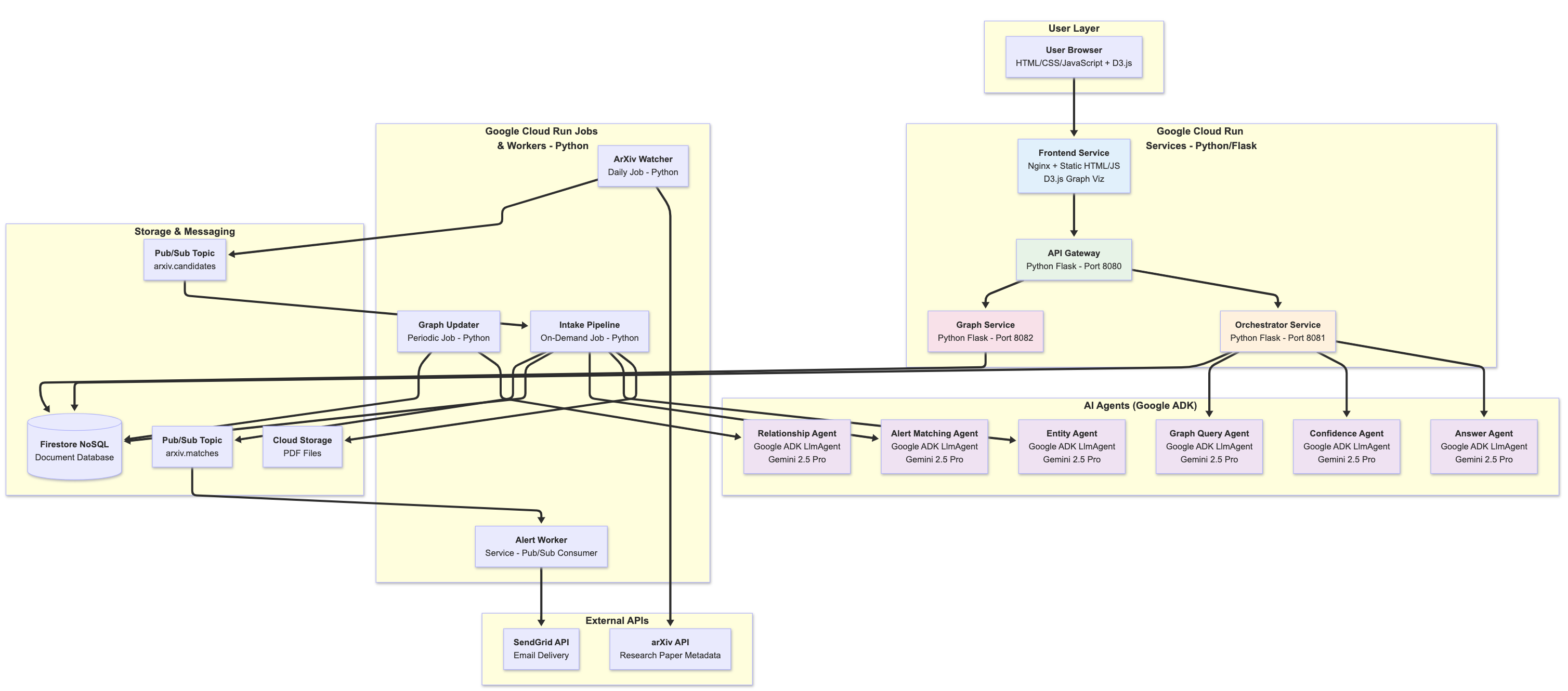
System architecture diagram showing all the services, frameworks and technologies used and how they come together
-
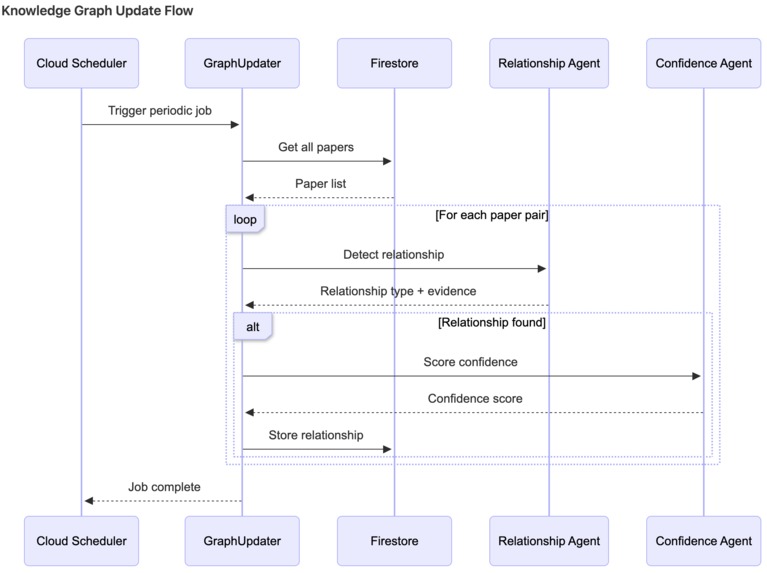
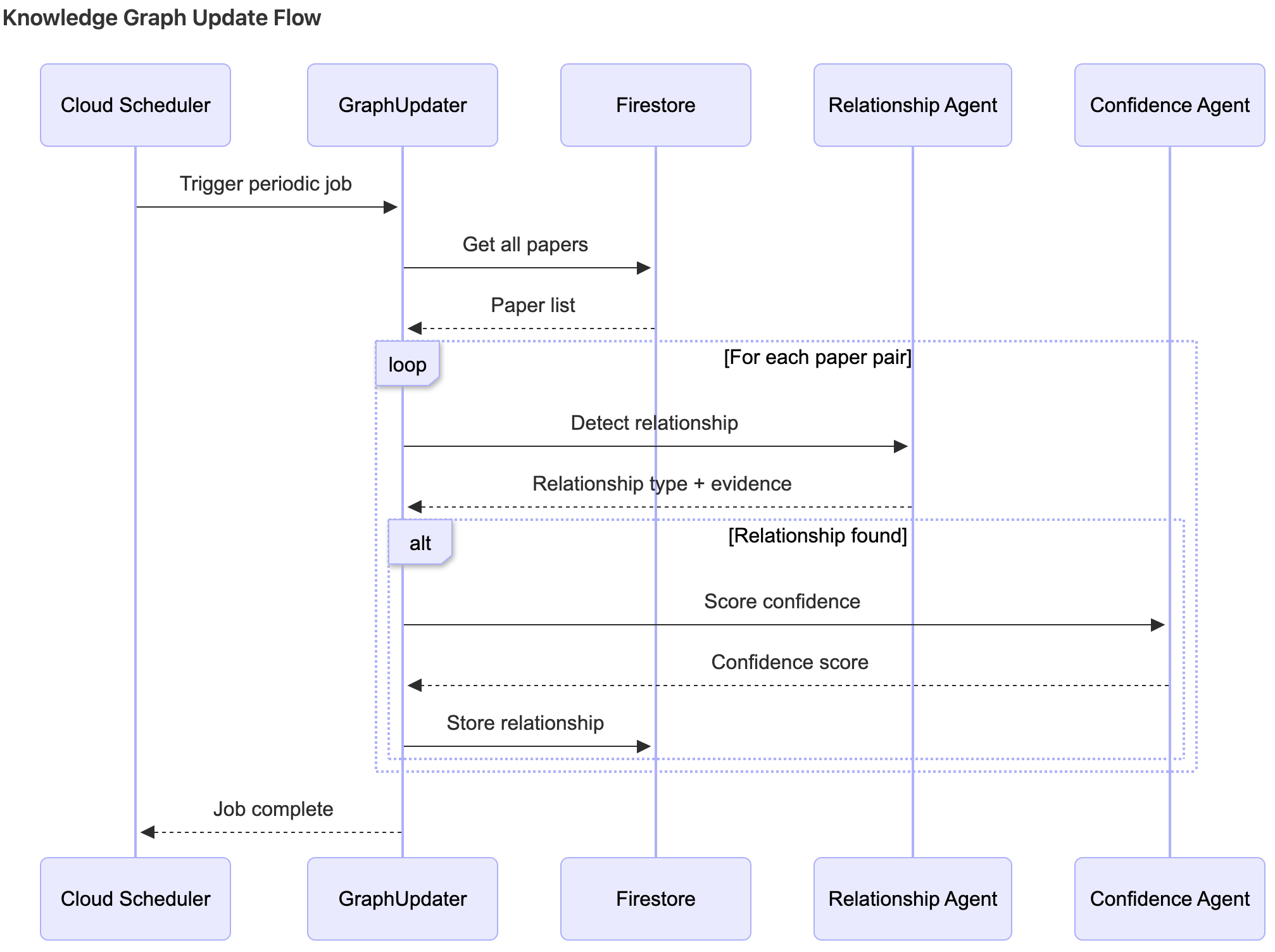
Dataflow diagram of knowledge graph update
-
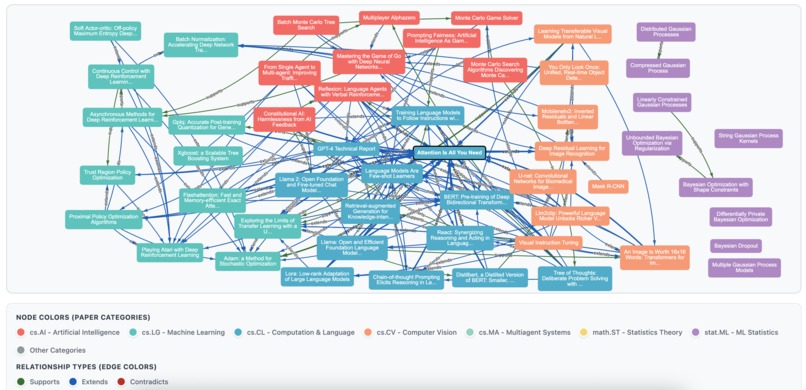
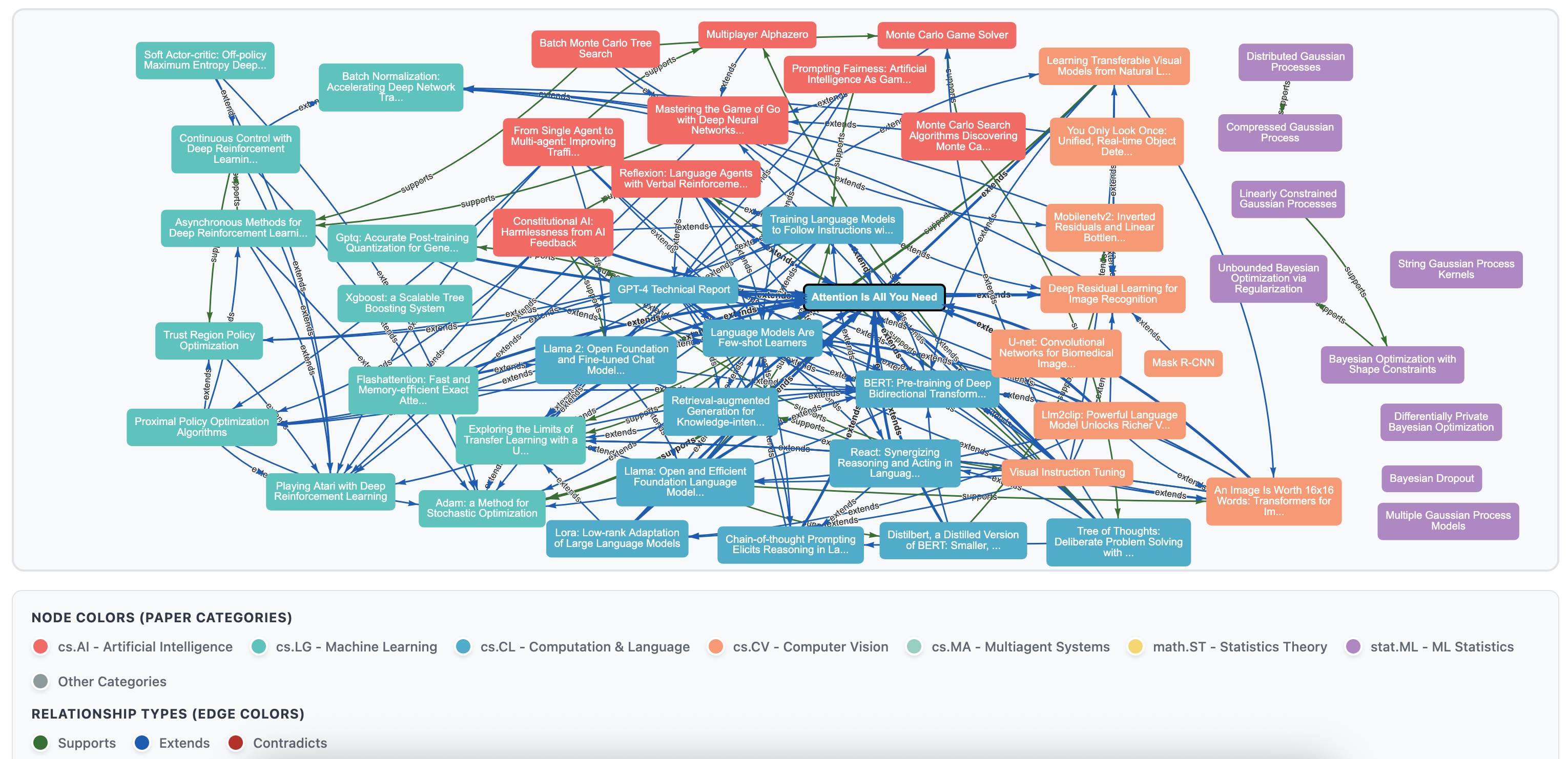
Snapshot of knowledge graph with papers from various arXiv subdomains - the relationship types are extends, supports and contradicts
-
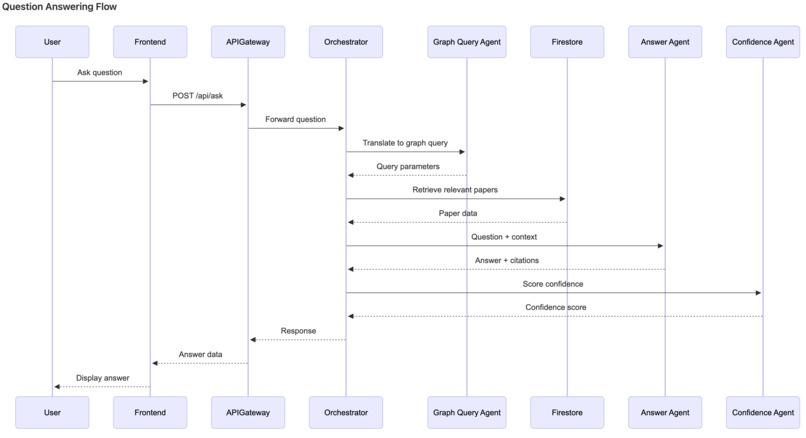
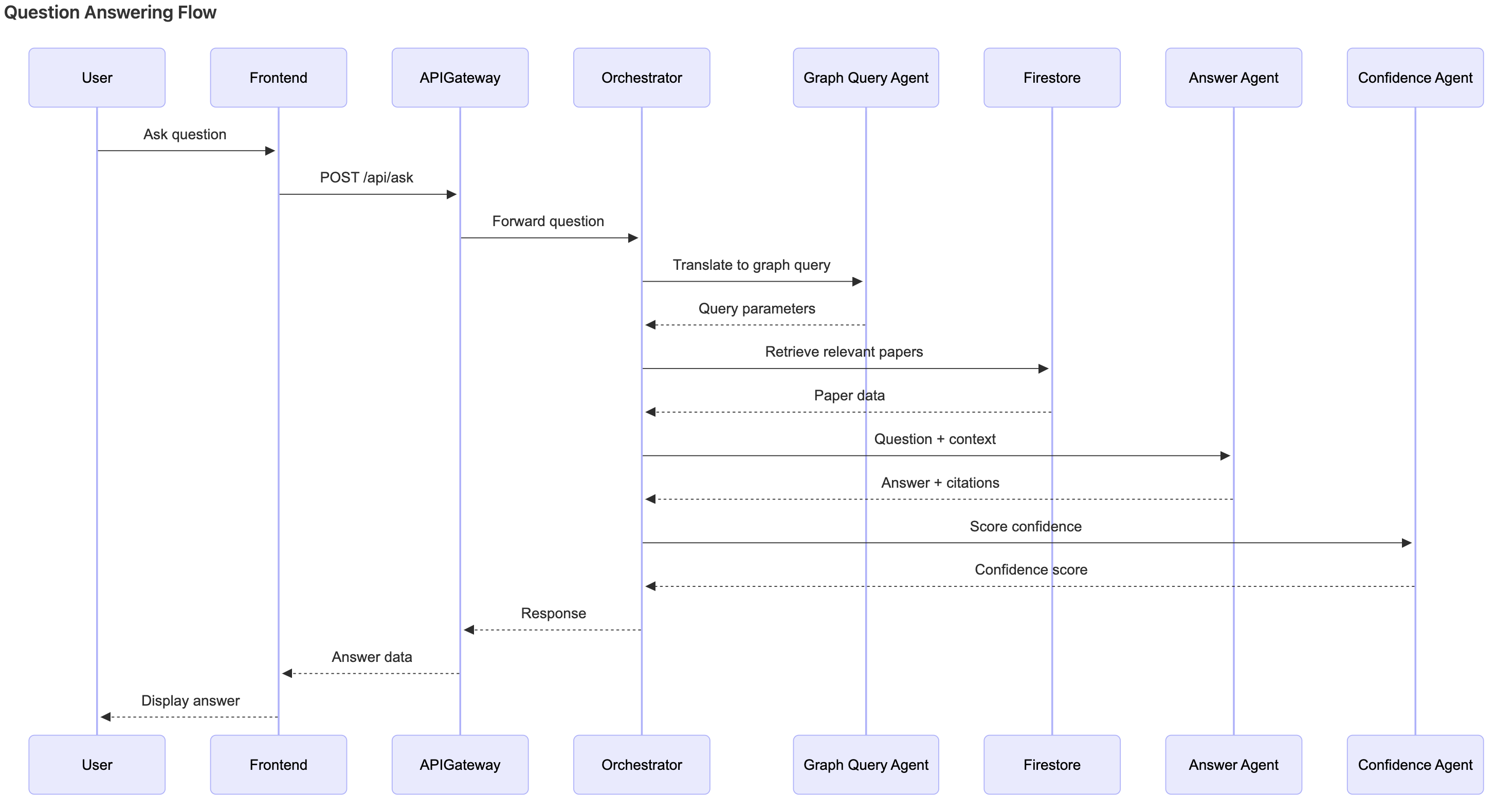
Dataflow diagram of Q&A
-

Example Q&A for a semantic graph query - 1
-

Example Q&A for a semantic graph query - 2
-
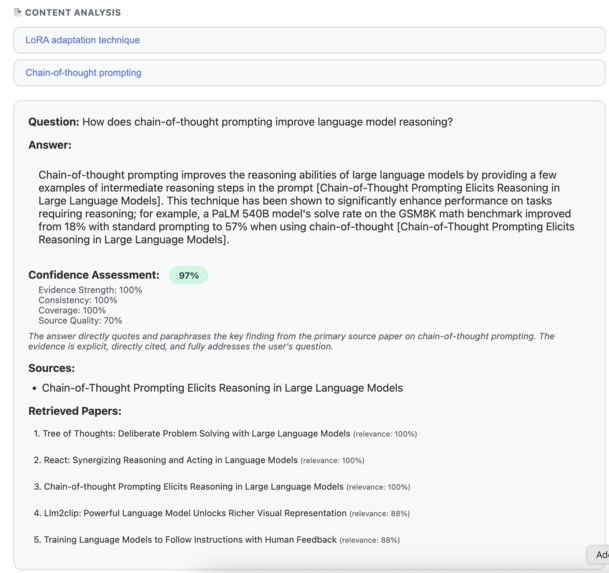
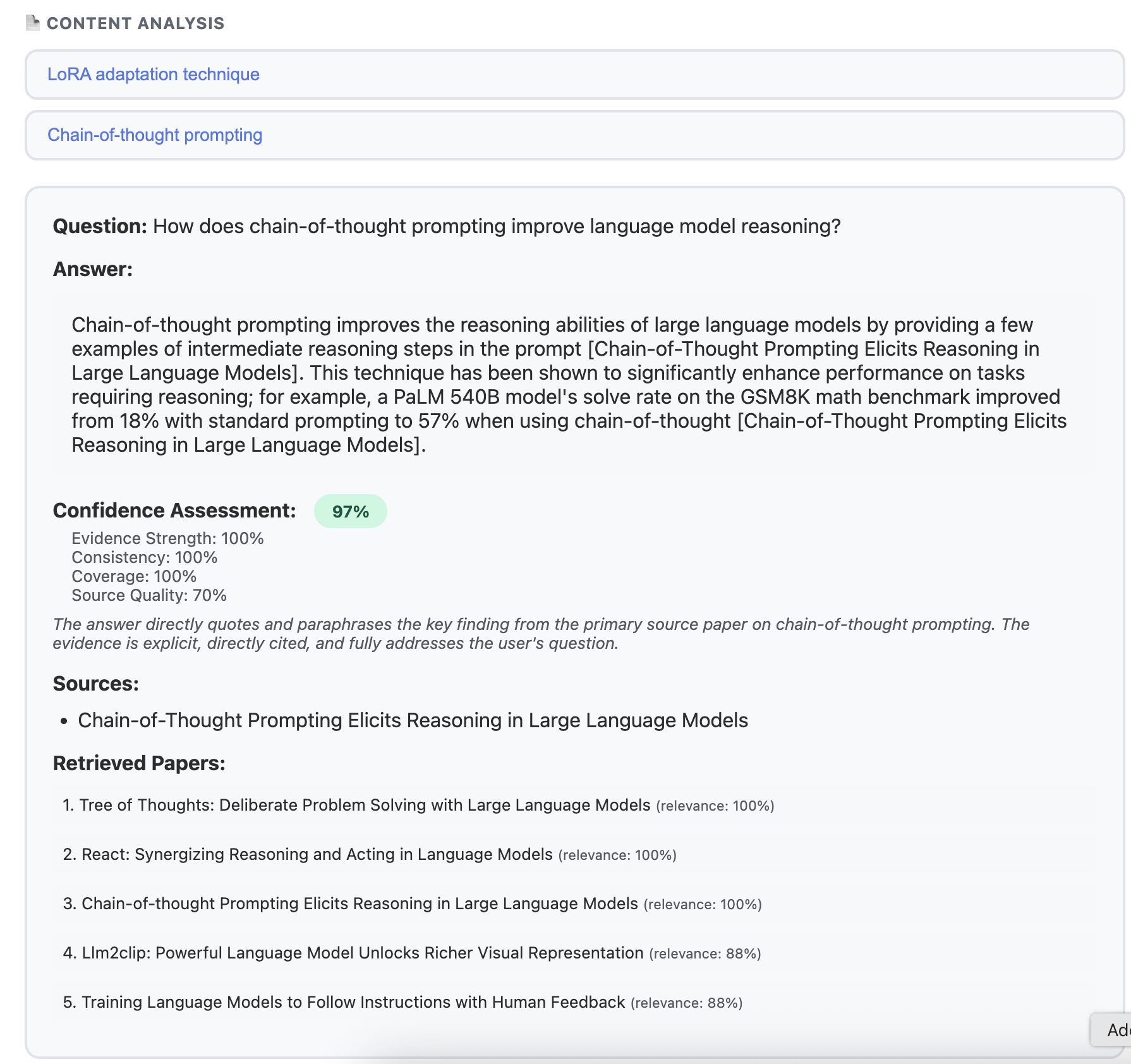
Example Q&A for a query on technical content of a paper
-
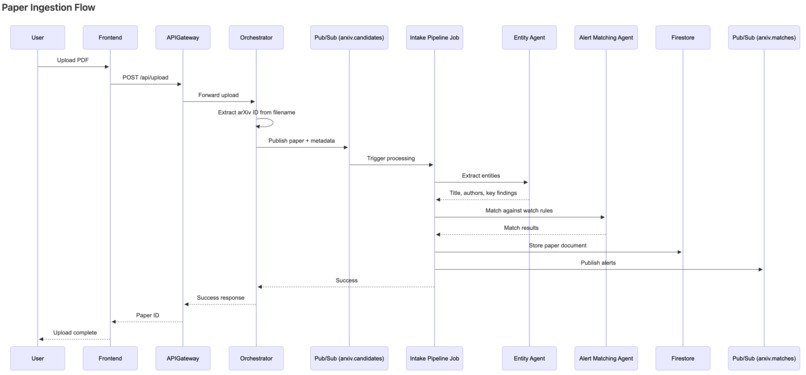
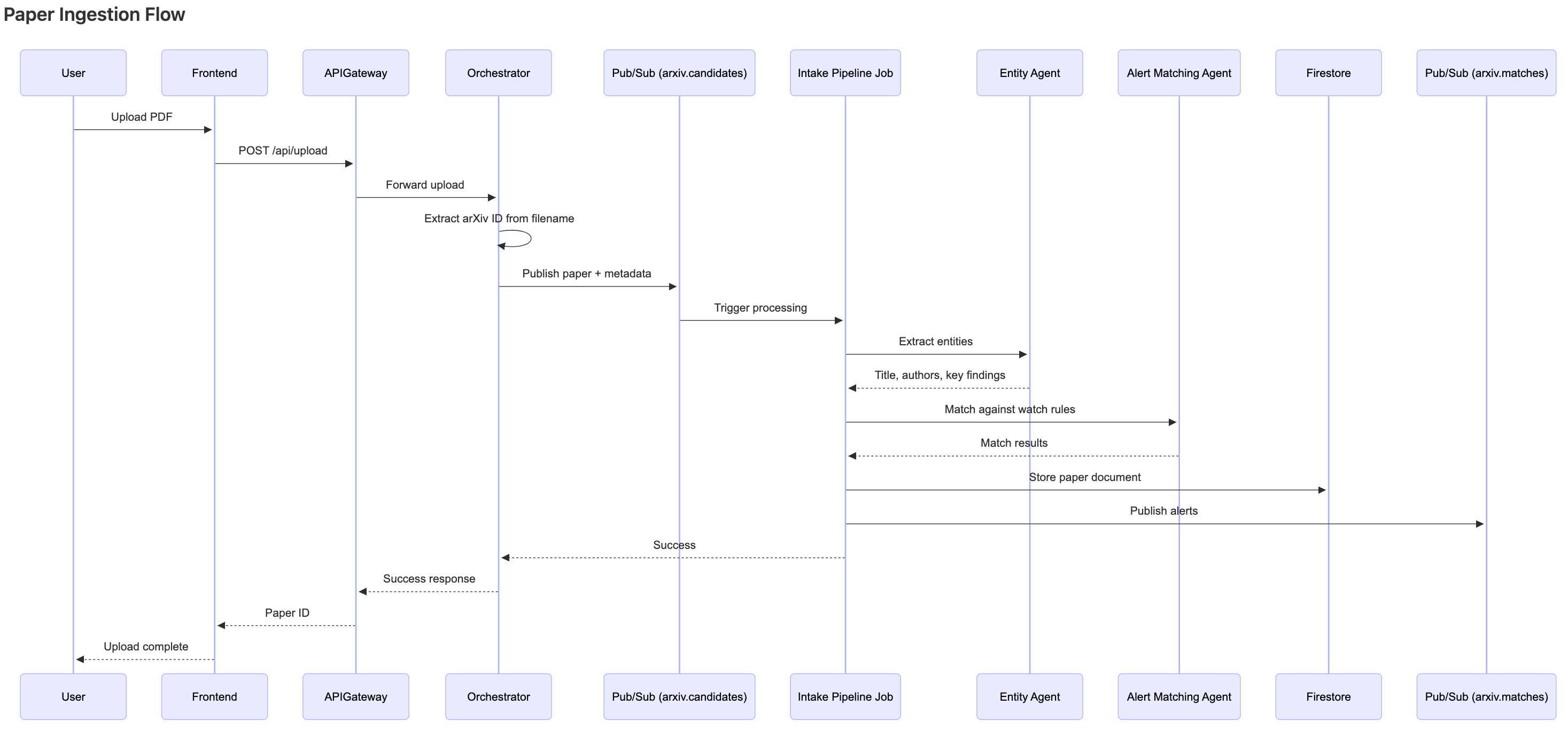
Dataflow diagram of paper ingestion flow
-
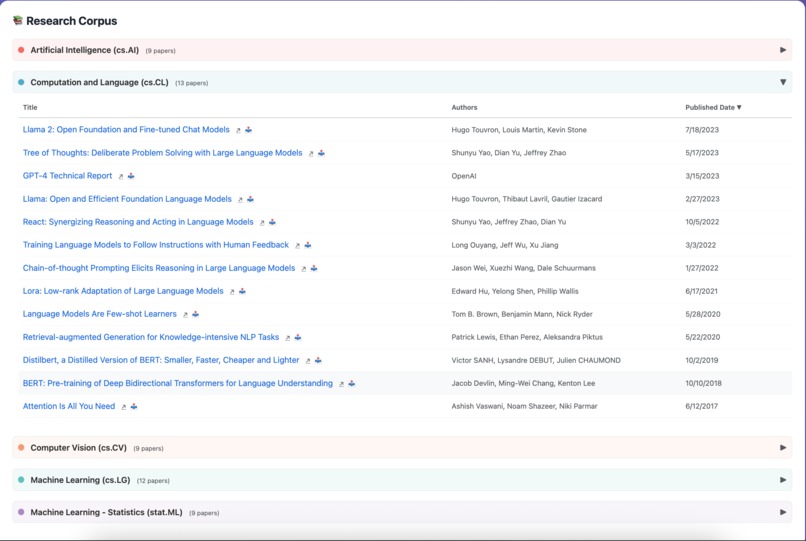
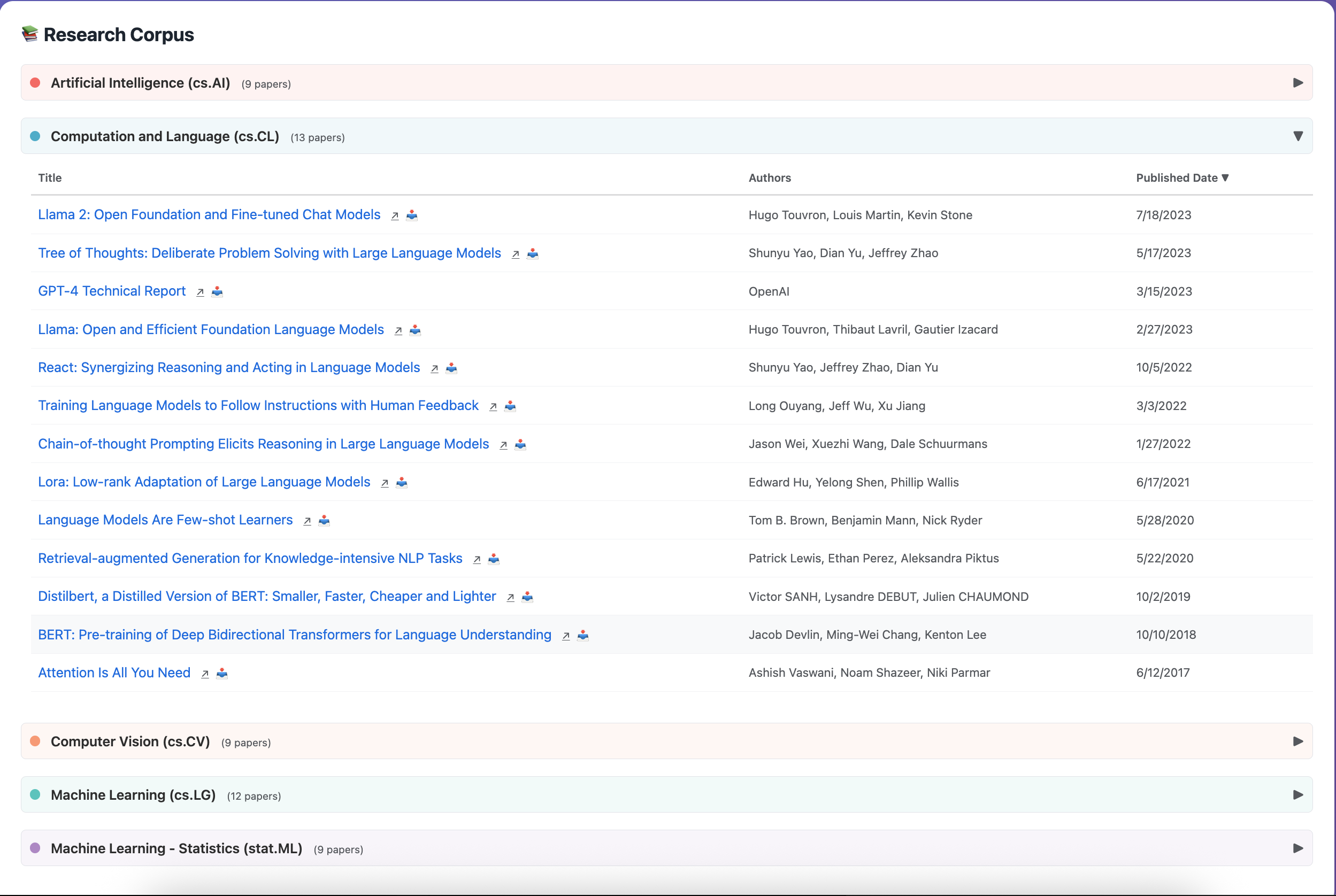
Front end view of ingested research corpus - collapsible sections by arXiv labels
-
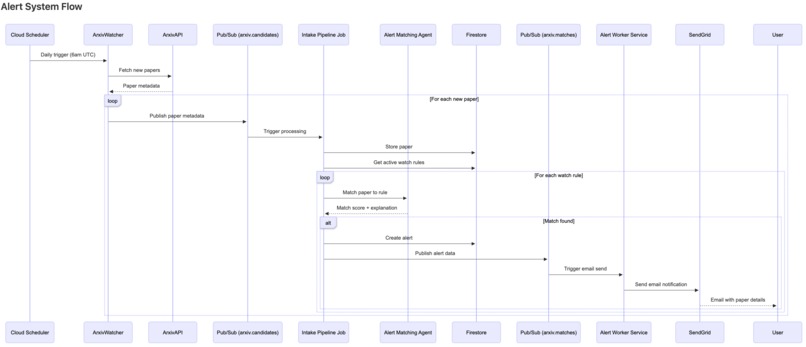
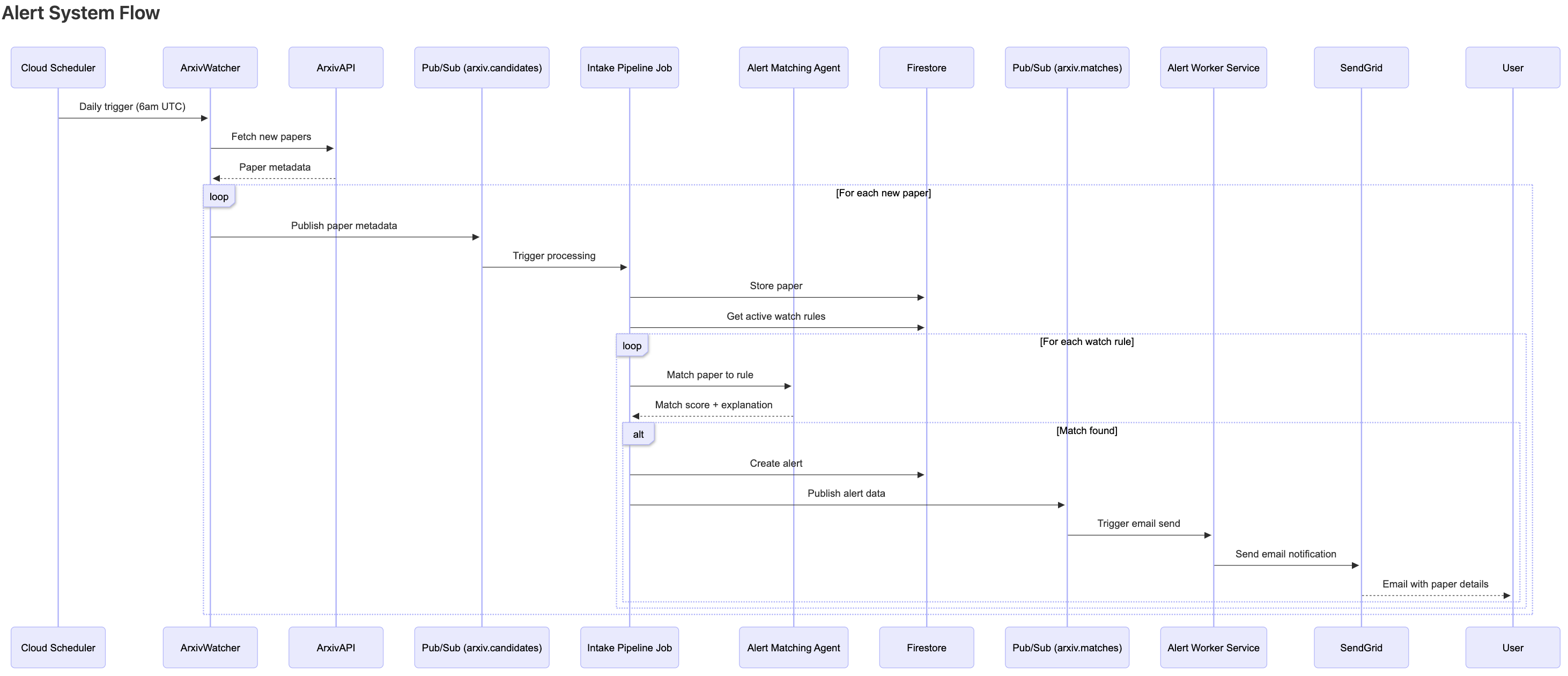
Dataflow diagram of alert system
-

Front end view of watch rules based on natural language description, specific authors and keywords (not shown here but available)
-
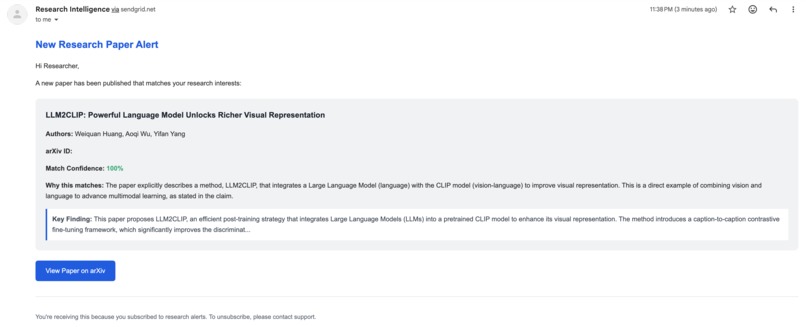
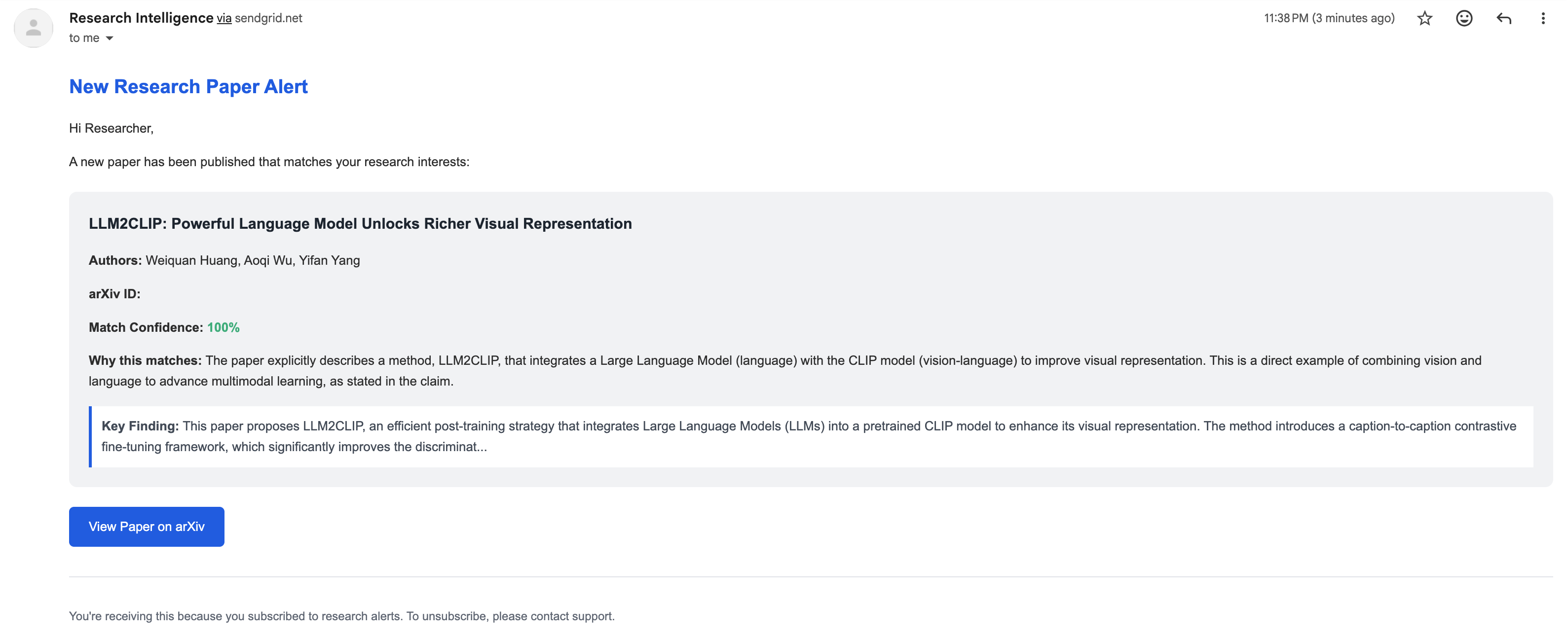
Example email alert when a new paper matching watch rule appears in the corpus



Inspiration
Picture this: 200-275 AI/ML research papers flood arXiv every single day. As researchers, we're drowning in literature.
But here's the thing - our research interests aren't simple keywords. We don't just want papers about "transformers." We want papers that contradict our recent findings, extend that specific technique we're exploring, or validate the hypothesis we're testing.
Google Scholar alerts give us keyword matching. We needed something that actually understands research.
We built an AI-powered research assistant that knows what we care about before we even search for it.
What it does
Research Intelligence Agents transforms academic literature monitoring from reactive search into proactive intelligence.
The Magic
Natural Language Watch Rules
"Papers claiming MMLU benchmark improvements > 2%"
"Work that contradicts findings in paper X"
"Applications of meta-learning to robotics"
Write your research interests in plain English. Get email alerts when relevant papers appear.
Knowledge Graph with Semantic Relationships
- Automatically detects how papers relate: extends, supports, contradicts
- Interactive D3.js visualization - see your field evolve in real-time
Q&A with Confidence Scores
Q: "What datasets were used to evaluate GPT-3?"
A: "GPT-3 was evaluated on multiple benchmarks including
LAMBADA (76.2% accuracy) and SuperGLUE..."
Confidence: 87% | Sources: [3 papers cited]
Tech Stack: Fully Serverless Multi-Agent System
6 Specialized AI Agents (Google ADK + Gemini 2.5 Pro)
- Entity Agent → Extracts metadata
- Relationship Agent → Detects paper connections
- Answer Agent → Generates responses with citations
- Confidence Agent → Scores answer quality
- Graph Query Agent → Translates natural language to graph queries
- Alert Matching Agent → Matches papers to watch rules
4 Cloud Run Services + 3 Jobs + 1 Pub/Sub Worker
- Frontend (Nginx + D3.js) → Interactive UI
- API Gateway → Request routing
- Orchestrator → Agent coordination
- Graph Service → Knowledge graph queries
- Intake Pipeline (Job) → Paper ingestion
- Graph Updater (Job) → Relationship detection
- ArXiv Watcher (Job) → Check for new arXiv papers at scheduled time
- Alert Worker (Worker) → Email notifications via SendGrid
All 3 Cloud Run resource types deployed and working in production.
Development: Crawl → Walk → Run
- Phase 1 (Crawl): PDF ingestion + basic Q&A → Proved the concept
- Phase 2 (Walk): Knowledge graph + proactive alerts → Added intelligence
- Phase 3 (Run): Production deployment + visualization → Demo-ready
Challenges we ran into
1. Semantic Search Backfired (Our Biggest Surprise!)
The Setup: Initial relationship detection was sparse (90 relationships, 7.7% density).
Our Intuition: Use semantic embeddings to pre-filter paper pairs. Only compare semantically similar papers → reduce comparisons, find relationships faster.
Negative Result: It made things worse.
Even at temperature=0.7, semantic filtering removed valid relationship candidates. The LLM found meaningful connections between papers that embeddings rated as dissimilar.
Example: A reinforcement learning paper extended a supervised learning technique. Low semantic similarity, but high conceptual relationship.
The Fix: Full N×N comparison with selective confidence thresholds and temperature tuning (0.3 → 0.7).
Result: 66% improvement → 172 relationships (12.7% density)
Key Learning: Semantic embeddings capture topical similarity. Relationship detection requires conceptual understanding. LLMs excel at the latter.
2. Deployment Complexity: The Service Discovery Dance
Challenge: Cloud Run URLs change on deployment. How do services find each other?
Solution: Deploy backend → discover URLs → deploy API Gateway with URLs as env vars → generate frontend config → deploy frontend.
Optimization: Pre-built base Docker images reduced build time from 15-20 minutes → 1-2 minutes (8-10x speedup).
3. Temperature Tuning for Relationship Detection
Initial graph density was too low (7.7%). We hypothesized the LLM was being overly conservative at the default temperature of 0.3.
The Trade-off:
- Low temperature (0.3): Deterministic, but conservative - misses subtle conceptual relationships
- High temperature (0.7): More exploratory outputs, captures nuanced connections
Our Approach:
- Increased temperature from 0.3 → 0.7 for relationship detection
- Ran detection multiple times and merged results (union strategy)
- Applied selective confidence thresholds:
contradicts= 0.7 (serious claim),extends/supports= 0.5
Result: 66% improvement in graph density (7.7% → 12.7%)
The union strategy was critical - at temp=0.7, the same prompt can yield different valid relationships. Running multiple passes and taking the union accounts for this stochasticity while maintaining quality through confidence filtering.
Accomplishments that we're proud of
Technical Scale
- 🤖 6 specialized AI agents orchestrated with Google ADK
- ☁️ All 3 Cloud Run resource types (4 services, 3 jobs, 1 worker) - comprehensive platform utilization
- 🕸️ 172 relationships across 52 research papers
- 📊 12.7% graph density (66% improvement from 7.7%)
- ⚡ Production-ready serverless architecture
Novel Insights
- Discovered that semantic search hurts relationship detection - counterintuitive finding that brute-force with good thresholds beats "smart" optimization
- Temperature tuning from 0.3 → 0.7 + union strategy = 66% density improvement
- Selective confidence thresholds per relationship type (contradicts=0.7, extends/supports=0.5) prevent false positives while maximizing recall
Production Engineering
- 8-10x faster deployments (15-20 min → 1-2 min) with pre-built base images - critical for hackathon iteration speed
- Interactive D3.js graph visualization with 12 relationship types - makes abstract knowledge graph tangible
What we learned
1. Semantic Embeddings Have Limits
We thought semantic similarity → likely relationships. Wrong.
LLMs find conceptual relationships that embeddings miss. Example: Meta-learning extending RL techniques - different domains, low embedding similarity, but strong conceptual link.
Takeaway: Use embeddings for retrieval, LLMs for reasoning.
2. Multi-Agent Architecture Wins
6 specialized agents (domain-specific prompts) >> 1 general agent.
Pattern: Entity extraction → Storage → Relationship detection → Alert matching
Agents communicate via Firestore. Decoupled, independently testable, easier to prompt-engineer.
3. Temperature Tuning for LLM Diversity
Same task, different temperatures:
- Temp 0.3: 90 relationships
- Temp 0.7: 172 relationships (+91%)
Running multiple times with union strategy = more robust than single-pass.
4. Deployment Time Optimization is Critical
Pre-built base images were a game-changer for hackathon iteration speed.
What's next for Research Intelligence Agents
Multi-Modal Content: Extract tables and charts from PDFs using Gemini vision API. Currently text-only.
Semantic Search for Q&A: Hybrid keyword + vector search for large corpus (>100 papers).
Citation Network Analysis: Identify influential papers, track emerging trends, detect research gaps.
User Research Memory: Track what you read, build personalized knowledge graph, resume research context.
Claim-Level Verification: Verify citations with exact quotes and page numbers; prevent hallucinations


Log in or sign up for Devpost to join the conversation.