-
-
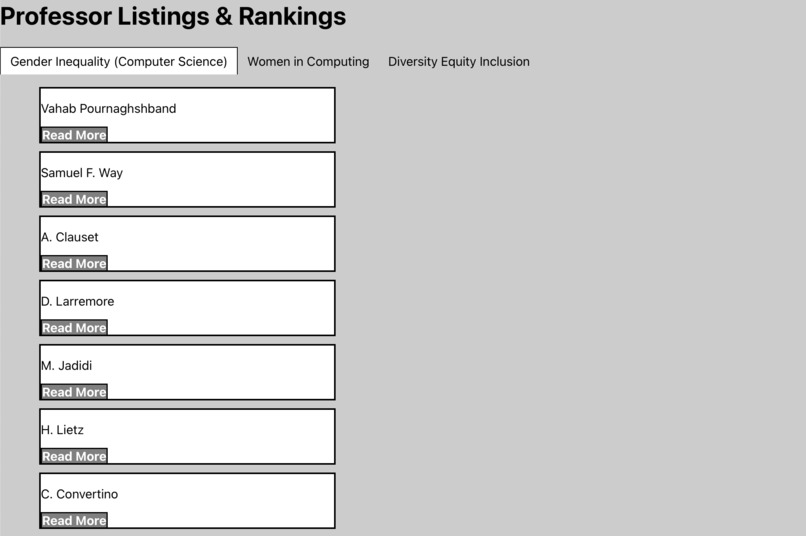
Home page
-
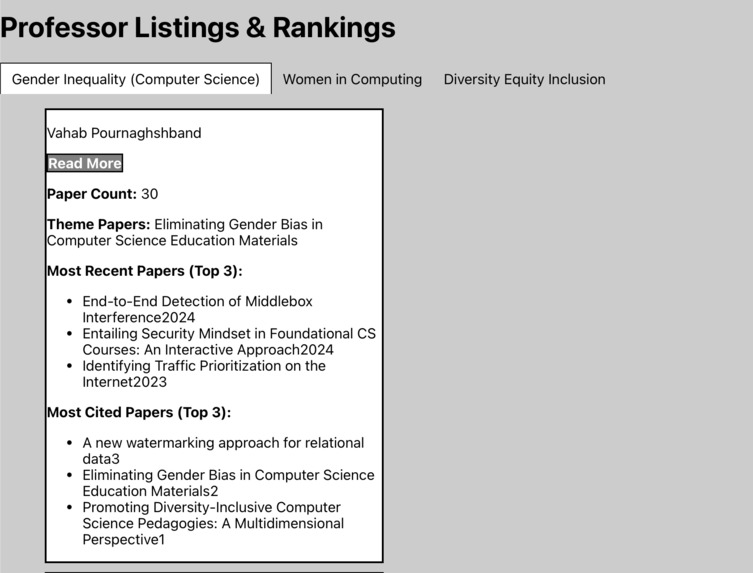
Professor description (collapsable)
-
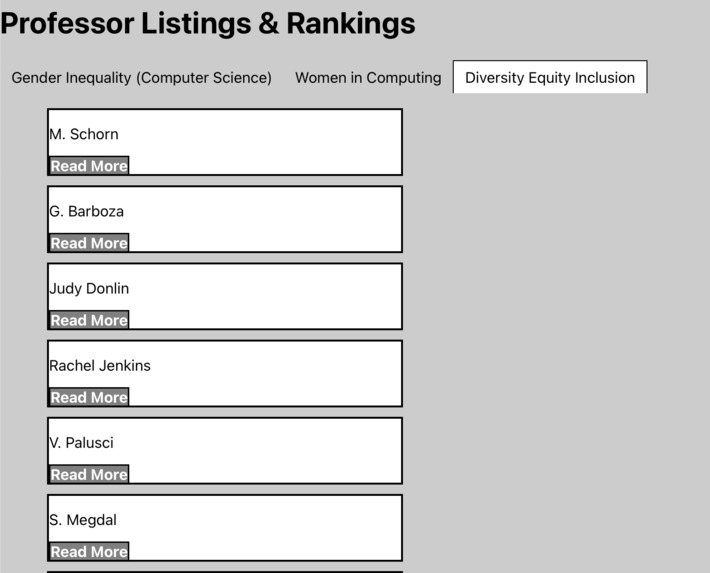
Alternate categories accessible by tabs
Why did we pursue this project for the hackathon?
As students interested in research, we’ve seen that papers in technical fields like AI are pushed significantly more into our attention. We wanted to make a website that would highlight interesting work discussing women in STEM as a resource to expose students exploring research, along with the authors who published those works. This will make it easier to find other people who are interested in the same research topics and have similar goals. The author information we highlight also allows us to get an overview on what each of these authors are working on, in addition to their research interests in women in STEM.
Hopefully, people will look at the papers highlighted and further explore the field and reflect on how they can help support them!
What we learned:
We learned how to set up a full stack web app with React for the front end and Python for the back end, as this is the first time we built an app with that specific tech stack.
We also learned how to implement the tabs feature, in which we were able to show different datasets on one webpage
We learned how to build a search filter bar feature, in which we built it to filter out professors based on their full name.
We learned how to use Selenium to scrape webpages dependent on Javascript to load. We learned how to use the inspector to find certain parts of the website, and how to use Beautiful Soup to read the text on those pages.
Project Tech Stack:
Front end -> React.js, HTML, CSS Webscraping -> Python Libraries Used: SemanticScholar API, Selenium, Beautiful Soup
Challenges we faced: There were many challenges. Our initial goal was to get professors along with their notable publications, and we aimed to scrape CSRankings and the Google Scholar links for each author (using the Google Scholar ID provided on CSRankings). However, Google Scholar was incredibly difficult to scrape. Google is very strict with bots 😔 We were unable to get more than ~50 professors’ worth of google scholar information, which isn’t much compared to the > 5k professors in the CSRankings database.
Another realization we had was that CSRankings only contains a curated list of tenure-track research professors in computer science; in order to expand our scope of authors, we wanted to include not only research professors, but any researchers who had published papers. We also wanted to highlight research and authors who had papers specifically relating to women in STEM.
We switched midway to using Semantic Scholar as our data source. Semantic Scholar is more friendly for web scraping scripts, including an API and documentation. Semantic Scholar also includes a wider range of papers, not just those written by research professors.




Log in or sign up for Devpost to join the conversation.