-
-
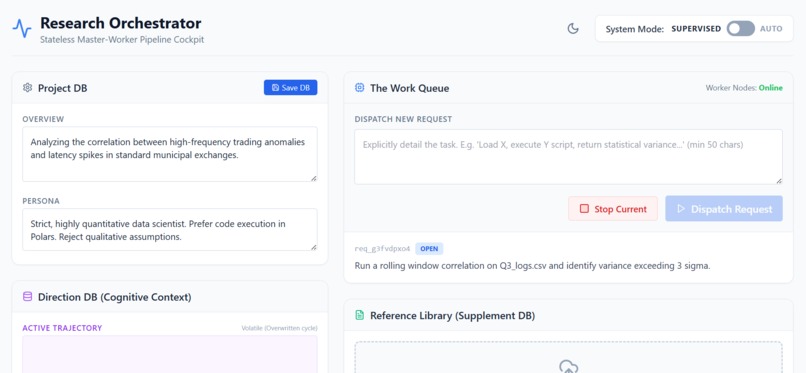
Main page
Inspiration
Most AI tools trap you in a "vibe-based" chat box. We wanted to build a deterministic compute engine where the user is the Prime Director, not just a prompter. We moved away from the traditional chatbot UI toward a Research Cockpit—a structured dashboard designed to oversee autonomous agents testing real-world hypotheses.
What it does
Research Cockpit is a stateless, database-driven pipeline that automates research execution:
Orchestrator (The Dispatcher): A master agent that evaluates the Project DB, dispatches parallel tasks, and reflects on findings via a Reflexion loop.
Workers (The Muscle): Sandboxed compute nodes that run experiments in isolated tmux sessions, submitting statistical reports back to the system.
Ingest Pipeline: A non-agentic system using MinerU and Bedrock to swallow PDFs and MD files, turning them into summaries the agents can actually use.
How we built it
FastAPI & SQLite: The backbone consists of two separate databases—Project DB for research state and Direction DB for the Orchestrator's internal reasoning.
AWS Bedrock (Claude Sonnet): Powers the high-level reasoning and statistical interpretation.
Process Isolation: Workers are decoupled using tmux sessions, allowing the system to scale and manage compute load without blocking the main loop.
MinerU: Handles complex document extraction, including tables and formulas, through a multi-mode (flash, precision, or local) pipeline.
Challenges we ran into
Zombie Workers: When a user pivots a project mid-execution, we had to ensure background workers didn't keep wasting compute on irrelevant tasks. We solved this with a "Hard Terminate" tool that kills tmux sessions instantly.
Statelessness: Because the Orchestrator’s context is wiped every 30 seconds, we had to build a system that perfectly reconstructs its "memory" from the Trajectory and Experience tables in the Direction DB on every cycle.
Race Conditions: Managing a live state tree shared by both users and autonomous agents required strict pessimistic locking and clear role division to prevent "thrashing".
Accomplishments that we're proud of
The Experience System: Our agents don't just work; they learn. They append lessons and heuristics (e.g., "Polars is 3x faster than pandas for this dataset") to an append-only list that guides future reasoning.
Parallel Dispatch: The Orchestrator can fire off multiple non-blocking worker requests simultaneously, significantly speeding up the research lifecycle.
Clean Separation: Agents never perform literature review; the ingest pipeline handles the "reading" so the agents can focus purely on statistical execution.
What we learned
Chat is a Bottleneck: For complex research, manipulating a database directly is far more efficient than trying to steer an agent through a conversational thread.
Persistence is Key: By making the agent stateless and the database the "source of truth," the user can manually overwrite the agent's internal reasoning at any time to fix a bad logic loop.
What's next for Research Cockpit Endless Autonomy: Fully enabling the is_auto toggle to allow the system to generate and test its own automated hypotheses indefinitely.
Advanced Statistical Deep-Dives: Expanding the Worker Report Contract to include more complex confidence intervals and automated visualization generation.
Local GPU Scaling: Optimizing the local MinerU extraction mode to handle massive document libraries without relying on external APIs.
Built With
- amazon-web-services
- fastapi
- gemini
- javascript
- python
- react
- sqlite
- tailwind

Log in or sign up for Devpost to join the conversation.