-
-
Landing page
-
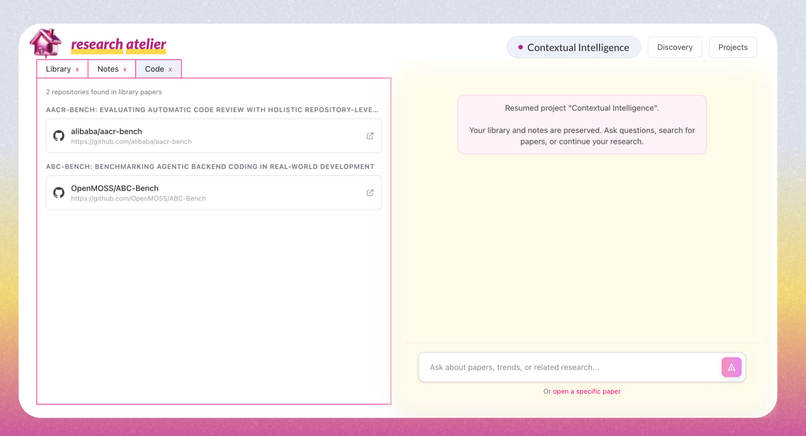
Research library and agent workflow
-
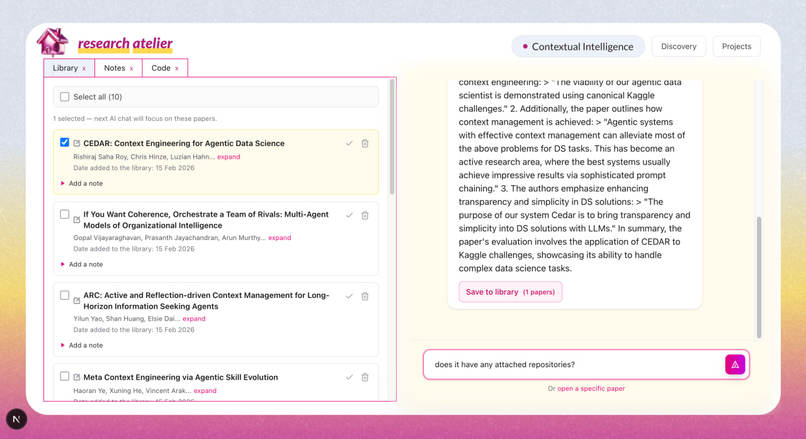
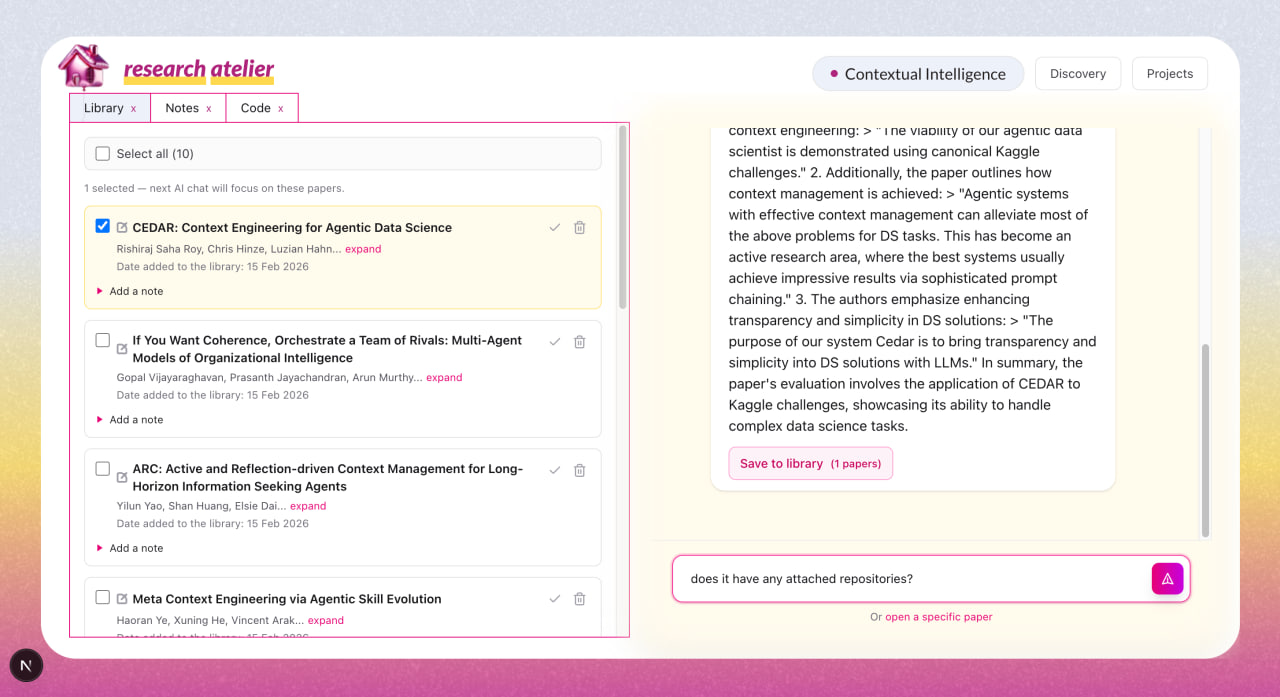
Add to library and select papers to chat about
-
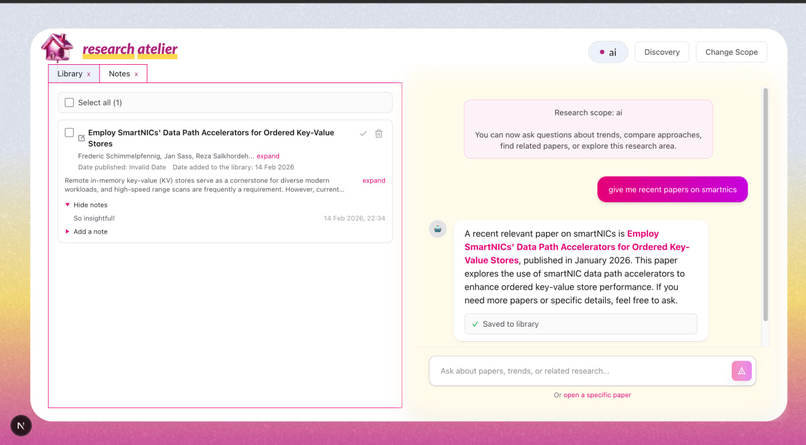
Write notes about papers and reference them later
-
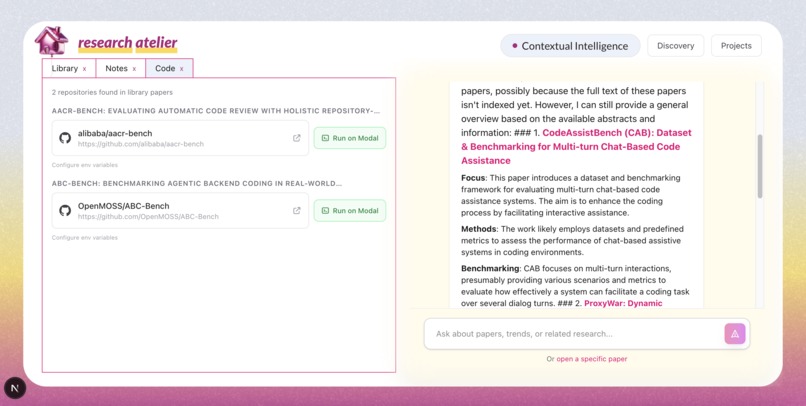
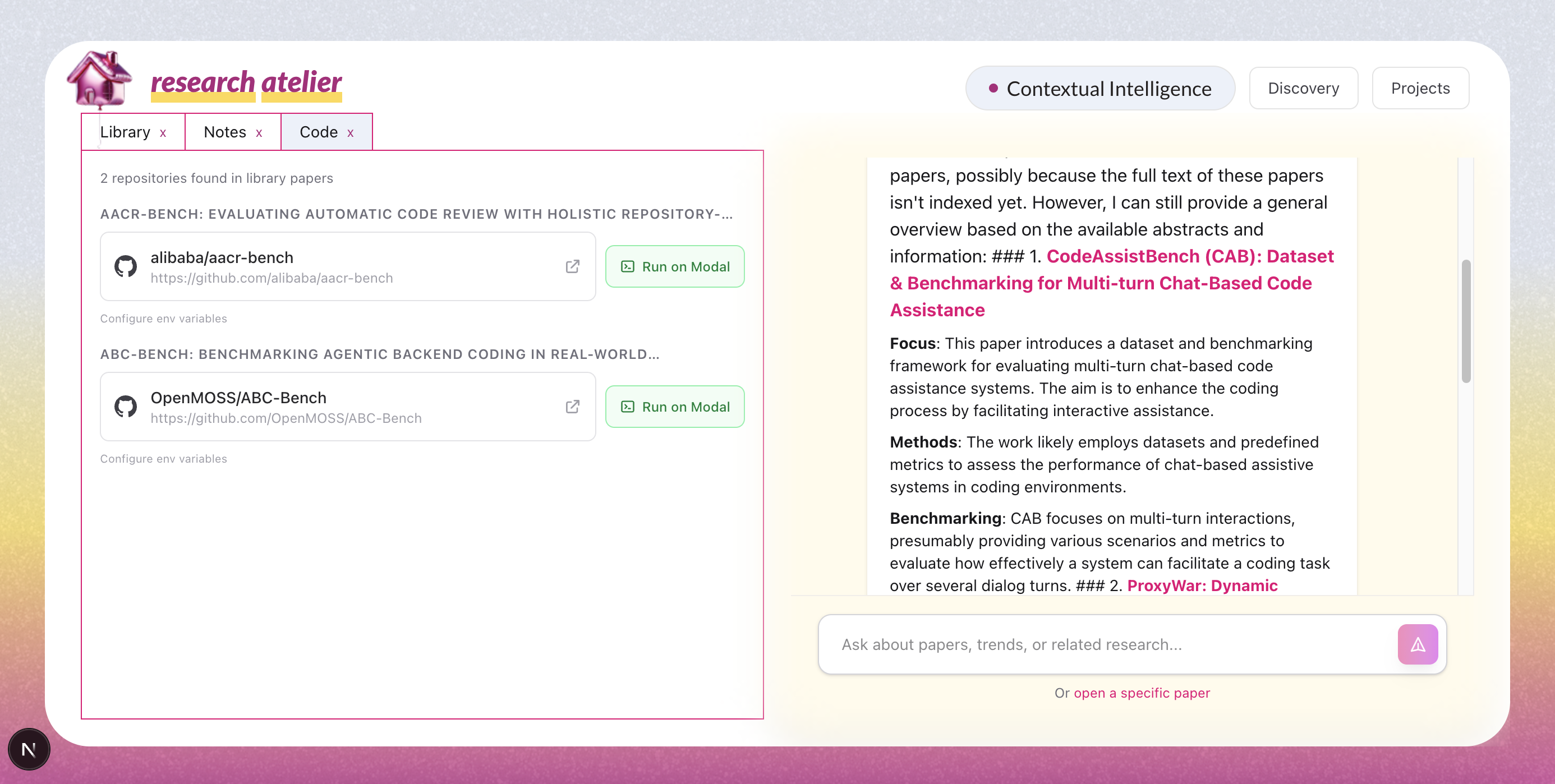
Auto-fetch all the repos for your library
-
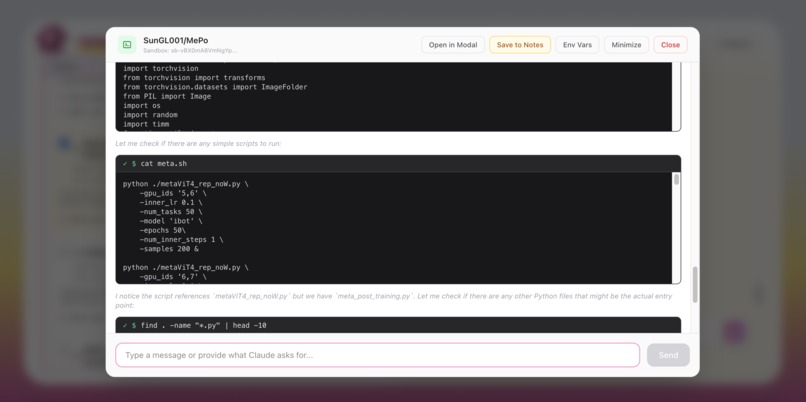
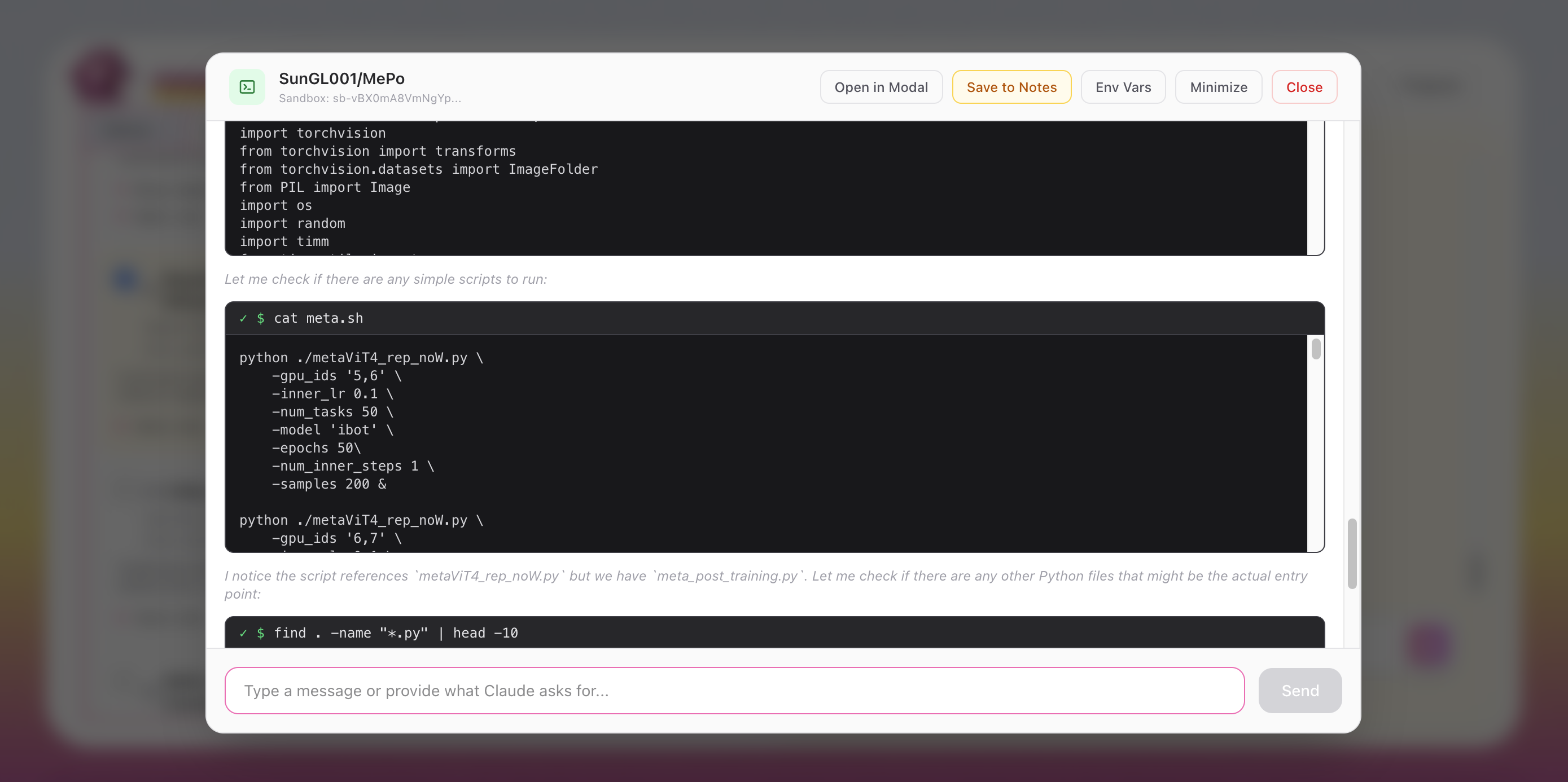
Launch and test code in a Modal Sandbox, orchestrated by Claude Code
Inspiration
Research is broken — not the science itself, but the workflow around it.
Researchers spend enormous amounts of time on tasks that should be automated: discovering relevant papers, realizing too late that someone already solved a problem, struggling to reproduce results because someone's junky code doesn’t run, and constantly switching between PDFs, notes, search engines, and terminals.
We wanted to build the system we wished existed: a single workspace where discovery, understanding, and experimentation happen in one continuous loop — powered by an AI assistant that understands what you’re working on.
What it does
Research Atelier turns research papers into interactive workflows.
The platform has three core modes:
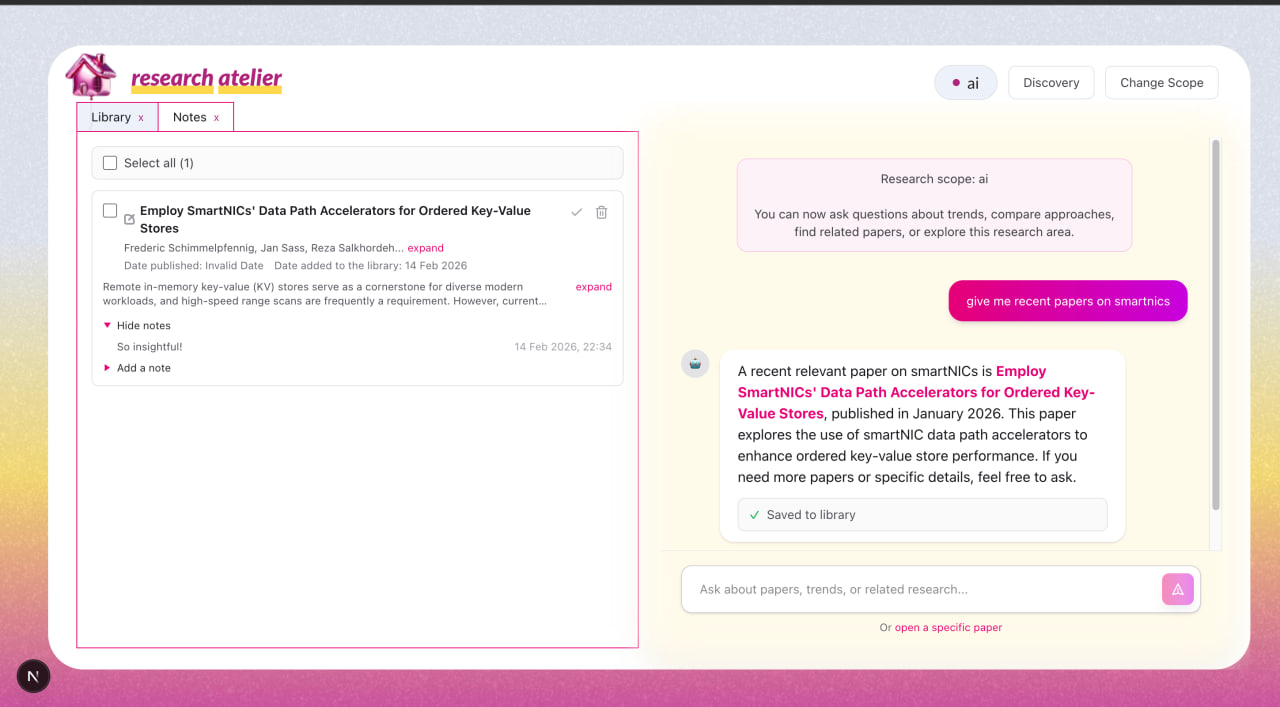
Discovery Mode
Find relevant research based on what you are already reading and working on.
We use Elasticsearch semantic search and more_like_this similarity over arXiv papers to recommend conceptually related work instead of keyword matches.
Work Mode
This is where you lock in. Each research topic becomes a persistent workspace containing:
- Library — papers automatically fetched, parsed, chunked, and indexed with Elasticsearch Jina semantic embeddings for deep semantic search.
- Notes — structured, project-linked research notes.
- Code — GitHub repositories automatically extracted from papers.
- AI Research Agent — an OpenAI-powered agent that can search papers, run RAG over full texts, retrieve metadata, and perform multi-step investigation using Elastic Agent Builder.
Runnable Research (Modal Integration)
Reading papers is only half the problem — reproducing them is even harder.
When a paper references a GitHub repository, Research Atelier can deploy it instantly using Modal sandboxes. We automatically:
- clone the repository,
- create an isolated execution environment,
- install dependencies,
- and use Claude Code to bootstrap and fix setup issues.
Researchers can go from paper → running experiment in one click.
How we built it
Research Atelier is built around three layers: retrieval, reasoning, and execution.
Knowledge Layer — Elasticsearch
Elasticsearch on Elastic Cloud and Elastic Agent Builder with Workflows serve as the backbone of the system.
- Global index for discovery across arXiv papers.
- Per-project indices created automatically when users add papers.
- Full-text papers are fetched via arXiv HTML, chunked (~1k chars), and indexed using
semantic_textwith Jina Embeddings v3 for passage-level semantic search. - Recommendations use Elasticsearch’s
more_like_thisquery over titles and abstracts. - Using Kibana API with workflows.
Agent Layer — OpenAI + Elastic Agent Builder
An OpenAI (gpt-4o-mini) agent operates through a tool-use loop.
The model decides when to search, retrieve passages, or launch deeper multi-step investigations through Elastic Agent Builder workflows.
Execution Layer — Modal Sandboxes
Referenced GitHub repositories can be launched in isolated Modal sandboxes.
We automatically clone repos, provision environments, install dependencies, and use Claude Code to get projects running without manual setup.
Application Stack
- Frontend: Next.js 15, React 19, TypeScript, Tailwind
- Database: Neon (serverless PostgreSQL)
- Deployment: Vercel
- Async ingestion pipelines handle paper parsing and indexing in the background.
OpenAI handles reasoning, Elasticsearch handles knowledge retrieval, and Modal enables execution — allowing the agent to move from understanding research to running it.
Challenges we ran into
Full-text paper extraction is messy.
arXiv papers come as PDFs with wildly inconsistent formatting. Traditional PDF parsers produced noisy text that hurt retrieval quality. Our breakthrough was using arXiv’s HTML rendering endpoint (available for most 2024+ papers), which provides clean structured text suitable for chunking and embedding. Older papers fall back to abstract-only indexing.
Keeping context focused.
Sending an entire project library to the LLM was slow and expensive. We introduced paper selection and passage-level RAG so the agent retrieves only relevant chunks instead of full documents, keeping responses fast and precise.
Cold-start latency for runnable environments.
Spinning up Modal sandboxes for arbitrary research repositories can be slow due to environment setup and dependency installation. To reduce wait time, we implemented a pre-warming strategy that keeps prepared sandbox environments queued and ready, allowing deployments to start almost immediately when users launch a paper’s code.
Accomplishments that we're proud of
End-to-end paper ingestion pipeline — add a paper → fetch structured text → chunk → embed → index → searchable within seconds. The system continuously builds a usable research knowledge base as you work.
Two-tier research architecture — global semantic search for discovery combined with per-project full-text RAG for deep understanding. The agent automatically chooses the right retrieval strategy.
Zero-training recommendation system — Elasticsearch’s
more_like_thisproduces strong, context-aware paper recommendations directly from a user’s library.Runnable research environments — papers don’t stop at reading. We automatically detect referenced GitHub repos and launch them in Modal sandboxes, turning papers into executable experiments.
A workspace researchers actually want to use — structured projects, integrated notes, and fast interactions make the experience feel like a real research tool rather than a chatbot wrapper.
What we learned
semantic_textsimplifies semantic search. Elasticsearch + Jina let us add high-quality retrieval without managing custom embedding infrastructure.Tool-based agents are more reliable. Giving the model explicit tools made reasoning more controllable and easier to debug than large prompt-only systems.
Simple methods go far. Elasticsearch’s
more_like_thisproduced strong recommendations without training data or complex models.Understanding matters more than search. The biggest value comes from helping researchers reason over papers and experiments, not just find them.
What's next for research atelier
Deeper execution workflows — expand Modal integration so the agent can automatically run experiments, evaluate outputs, and iterate on paper codebases with minimal user input.
Paper-vs-paper comparisons — structured, agent-generated comparisons across methods, benchmarks, datasets, and results using full-text understanding.
Smarter recommendations — hybrid retrieval combining semantic search, keyword matching, and citation graph signals, eventually adapting to individual research patterns.
Collaborative research spaces — shared projects where teams can build libraries, notes, and experiments together.
Beyond arXiv — expanding ingestion to sources like PubMed, Semantic Scholar, and major conference proceedings.
Built With
- arxiv
- css
- elasticsearch
- kibana
- neon
- next.js
- node.js
- openai
- python
- react19
- typescript
- vercel


Log in or sign up for Devpost to join the conversation.