-
-

RescueLine
-
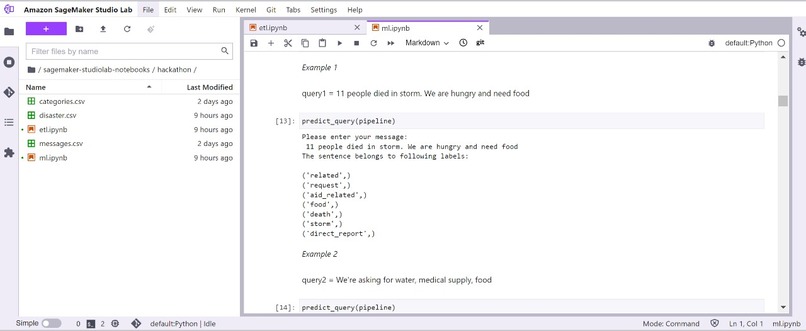
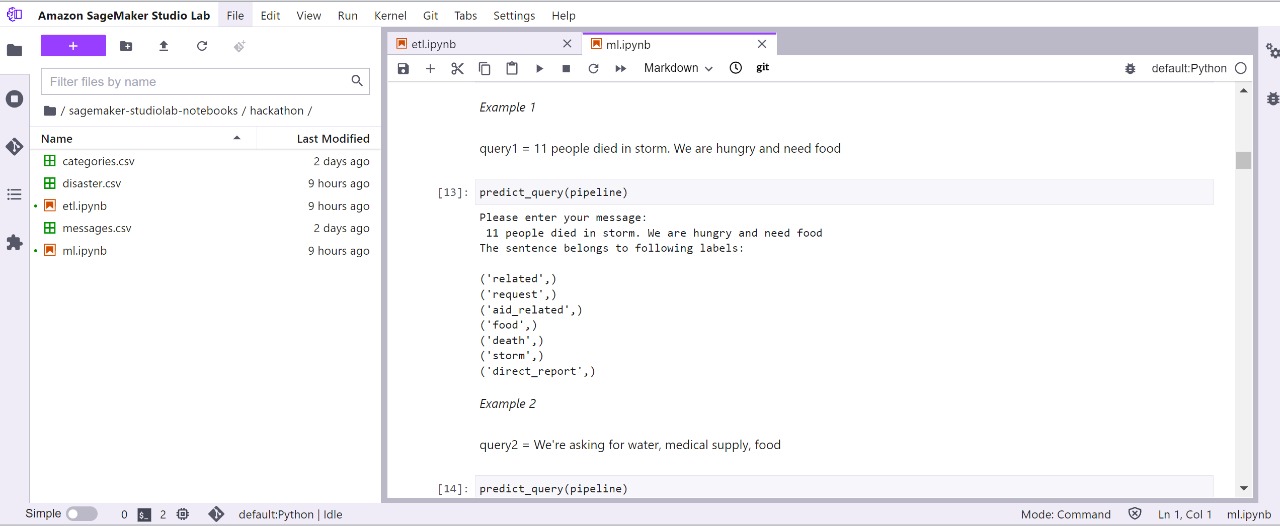
Screenshot of sample input

Inspiration
Disasters cause hardship, and different individuals can require different kinds of help. A flood can trap someone inside a collapsed building, while someone else gets stuck on the roof, or someone suddenly has no access to drinking water or food, or needs emergency medical help. The flood of emergency calls can and often does overwhelm local response teams, which is why we have built RescueLine.
What it does
RescueLine uses state of the art machine learning algorithms to automatically classify calls for help according to the nature of aid request, so that emergency responders can be dispatched quickly and with appropriate gear for the task.
How we built it
We used AWS SageMaker Lab, which is incredibly scalable and one of the cheapest solutions for developing Machine Learning models in the market. With essentially no server or infrastructure costs, and built-in geo-redundancy helped us create Jupyter Lab instance with ease. RescueLine is how we will save lives. For this pipeline, we have used the dataset provided by Figure Eight. There are 36 pre-defined categories like Aid Related, Medical Help, Search And Rescue, etc. The dataset consists of messages.csv containing the messages and categories.csv containing the corresponding tags associated with each message. The project consists of two sub-pipelines: 1. ETL Pipeline (responsible for Extraction-Transfer-Load part) 2. ML Pipeline (performs multi-label classification on the pre-processed dataset) ETL Pipeline
- We load messages.csv and categories.csv into pandas dataframes
- We merge the messages and categories datasets.
- The combined dataset is assigned to
df - Split the values in the
categoriescolumn on the;character so that each value becomes a separate column. - We perform one-hot encoding and this to ‘df’
- We remove the duplicate values. After cleaning the dataset, we save it as disaster.csv. This will serve as the dataset for ML pipeline. ML Pipeline ML Pipeline
- We import the relevant sci-kit and nltk libraries and read disaster.csv file into pandas dataframe.
- Then, train test split is performed on this dataset in 80:20 train test ratio
- Our model should take in the
messagecolumn as input and output classification results on the other 36 categories in the dataset. - We create a dictionary of multi-output estimators. Multioutput estimators are meta-estimators, which require a base estimator to be provided in their constructor. RandomForestClassifier, K-NearestNeighbours, XGBoostClassifier, and NaiveBayes are used are as based estimators for the multi-label classification task. Our machine learning model consists of a pipeline with sequentially applies CountVectorizer and Tf-idftransformer followed by the final classifier. CountVectorizer converts a collection of text documents to a matrix of token counts. This matrix is passed as an input to Tfidftransformer which transforms a count matrix to a normalized tf or tf-idf representation to reweight frequencies. The output hence produced is passed to the classifier for learning and the test set is used to evaluate the performance of this pipeline.
- For model evaluation, we use hamming score and hamming loss as our evaluation metrics.
- Next, we perform multilabel classification.
- Finally, we predict the labels of input queries.
Challenges we ran into
- The online mode of collaborative working presented some challenges.
- We had to figure out a performance metric for benchmarking various approaches.
- The grid search space was exhaustive.
- Training models on the data and comparing them is a time-consuming process, which meant that there is scope for improvements.
Accomplishments that we're proud of
- We are proud of how quickly we were able to get this done.
- We are proud that we have a viable product right now that can be built upon to become something that makes a difference in the real world, and how the current infrastructure on AWS makes it georedundant and instantaneously scalable according to the nature of the response required. This is a solution that requires very little in terms of investment for geo-redundancy and long-term deployment.
What we learned
- We learned about a lot of machine learning techniques as we started out to build this pipeline.
- It can be observed that XGBoost classifier performs the best on the chosen benchmark for multilabel text classification among the given models.
What's next for RescueLine
- We still have more models we would like to train and validate so that we can refine the idea.
- We want to improve language agnosticism to improve applicability in various regions.
- We can build a more end-to-end solution by connecting a call reception API, and a dispatch mechanism.
- We want to try building attention-based models (transformers like XLNet/BERT) to improve scores.
- We want to implement word2vector embeddings and deep learning architectures such as CNN, LSTM.
Built With
- amazon-web-services
- matplotlib
- nltk
- numpy
- pandas
- python
- sagemaker
- scikit-learn
- seaborn
- xgboost


Log in or sign up for Devpost to join the conversation.