-
-
Home page
-
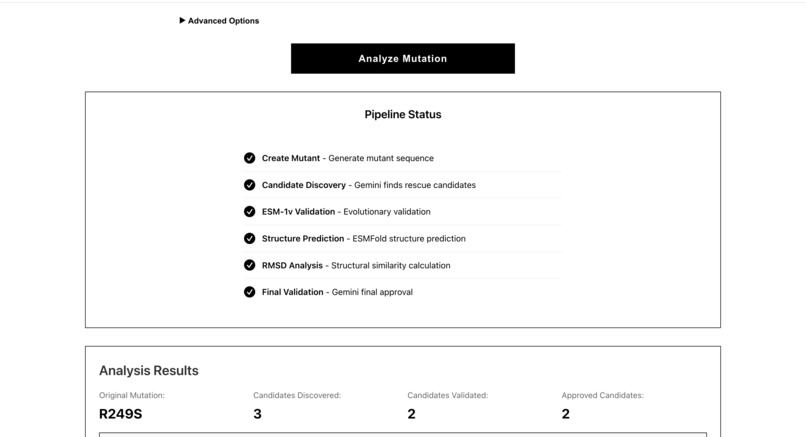
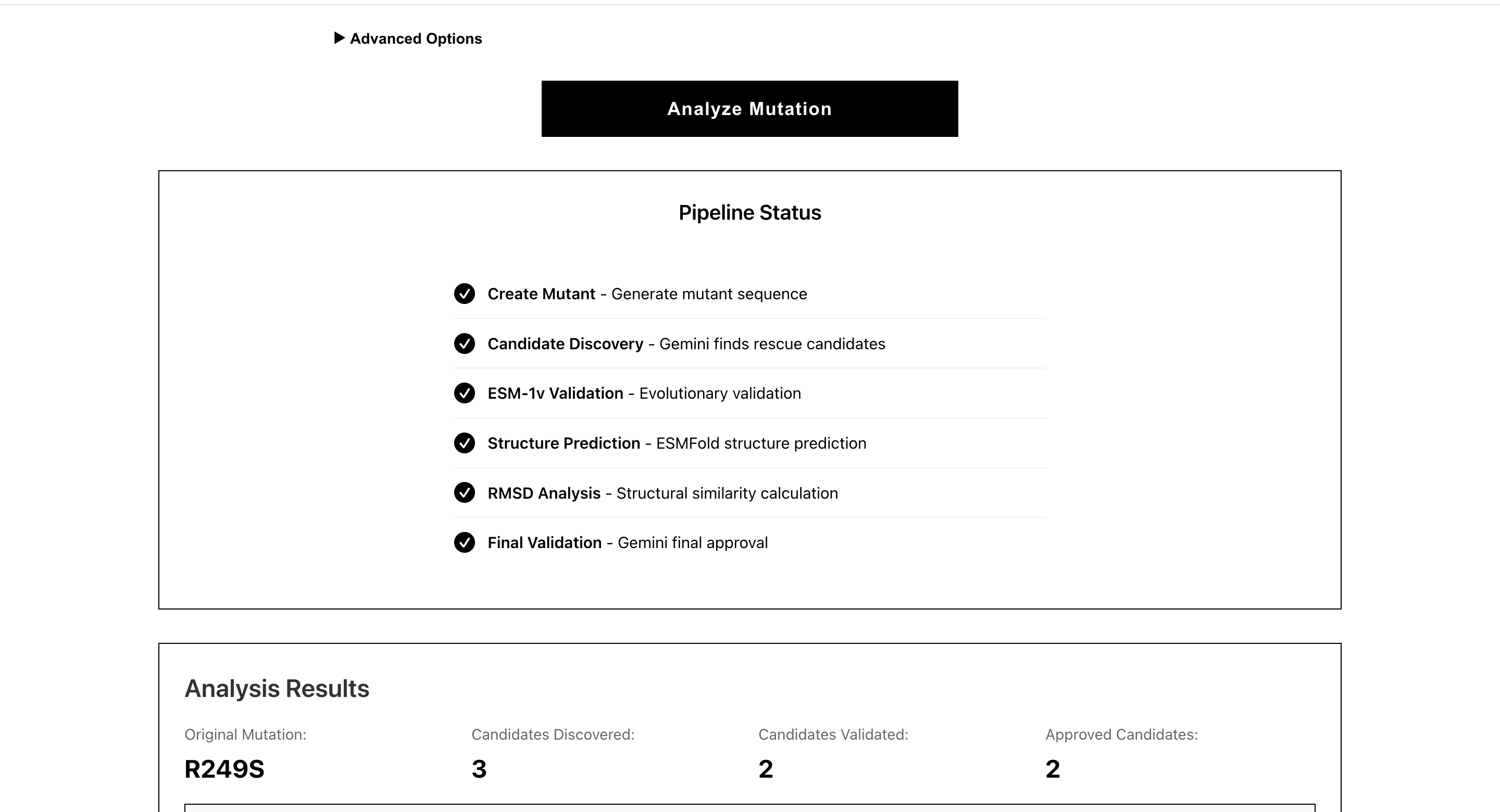
Pipeline Status
-
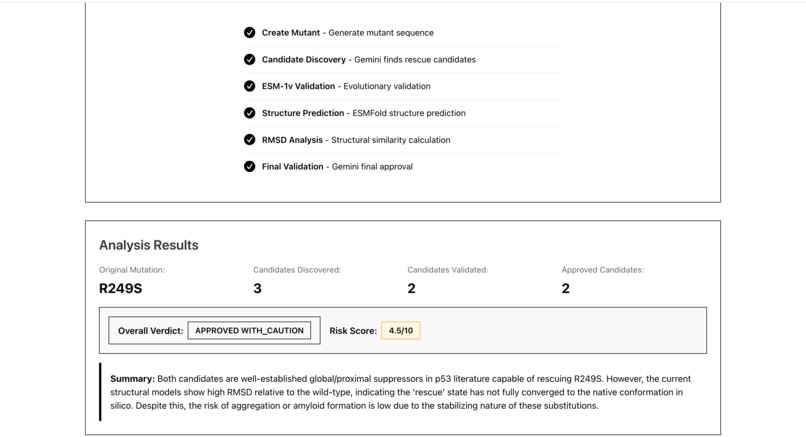
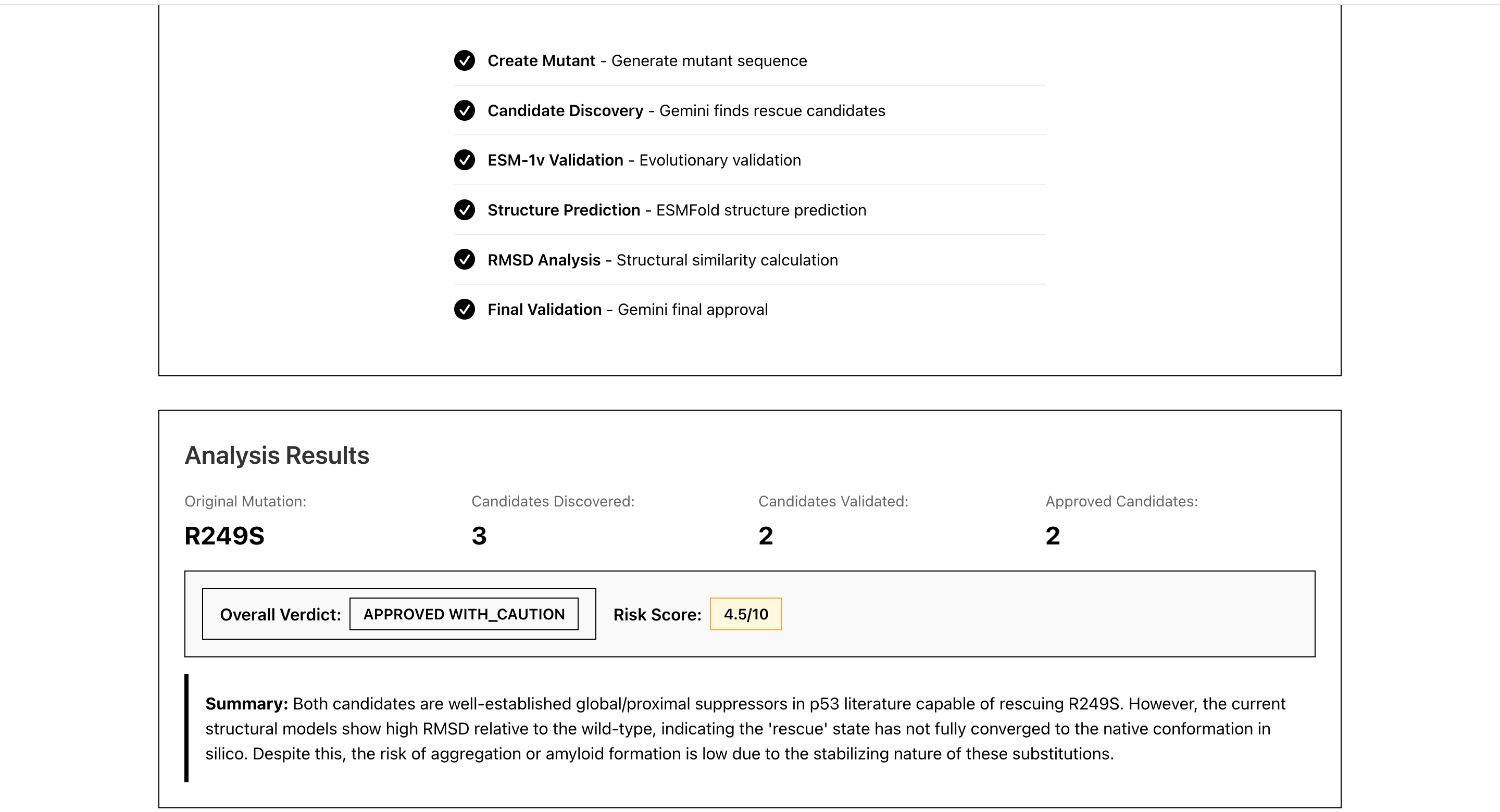
Analysis results
-
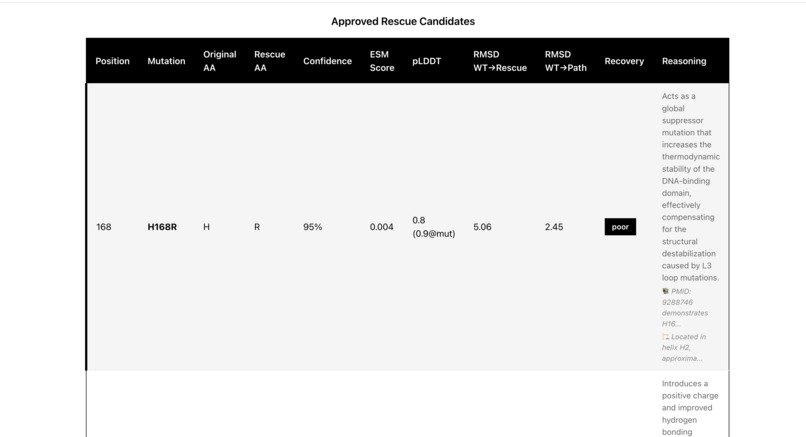
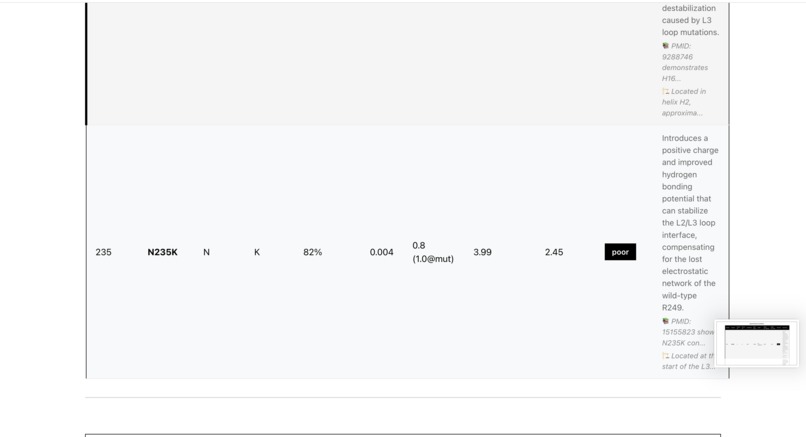
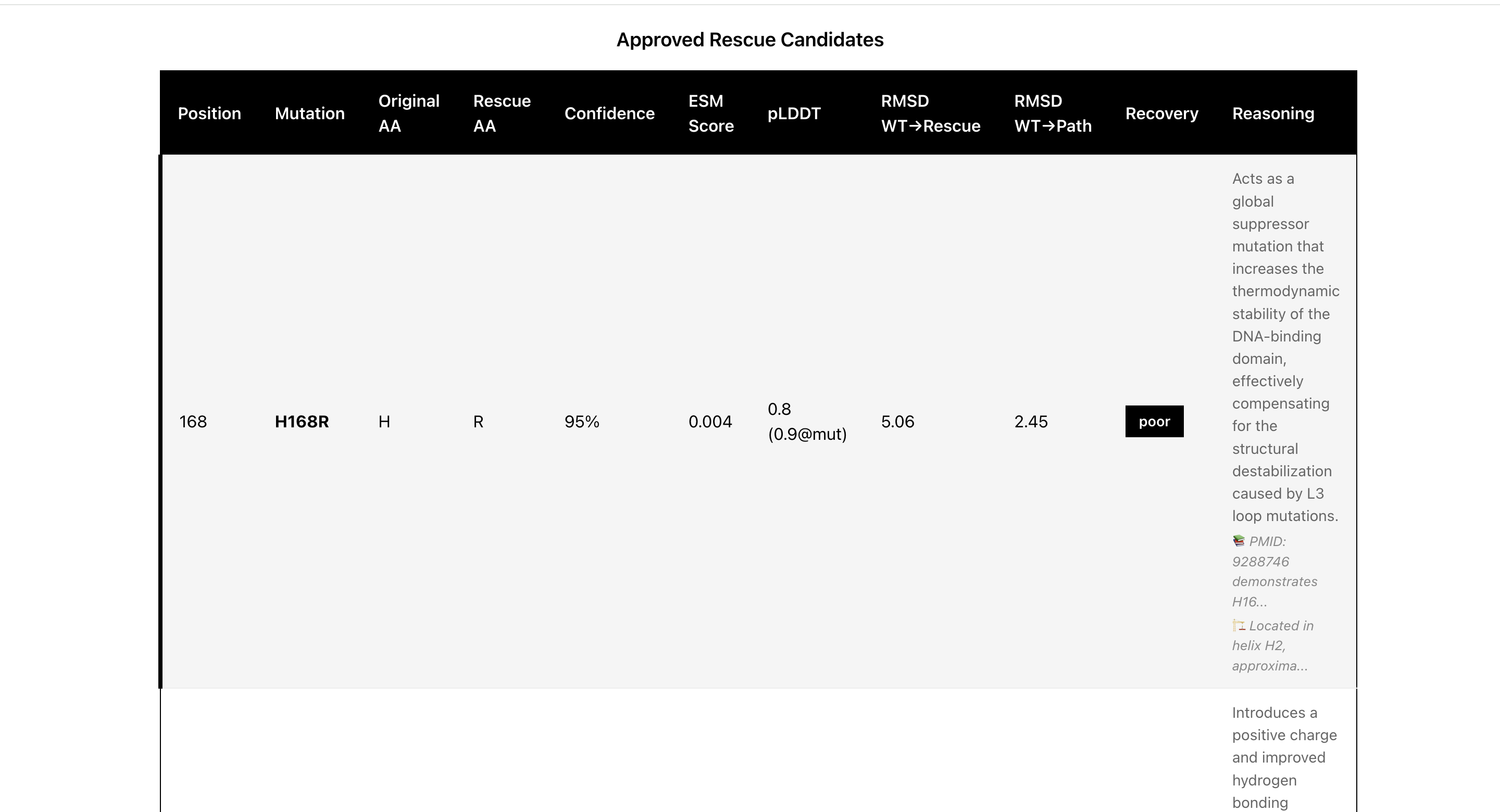
Rescue Candidates
-
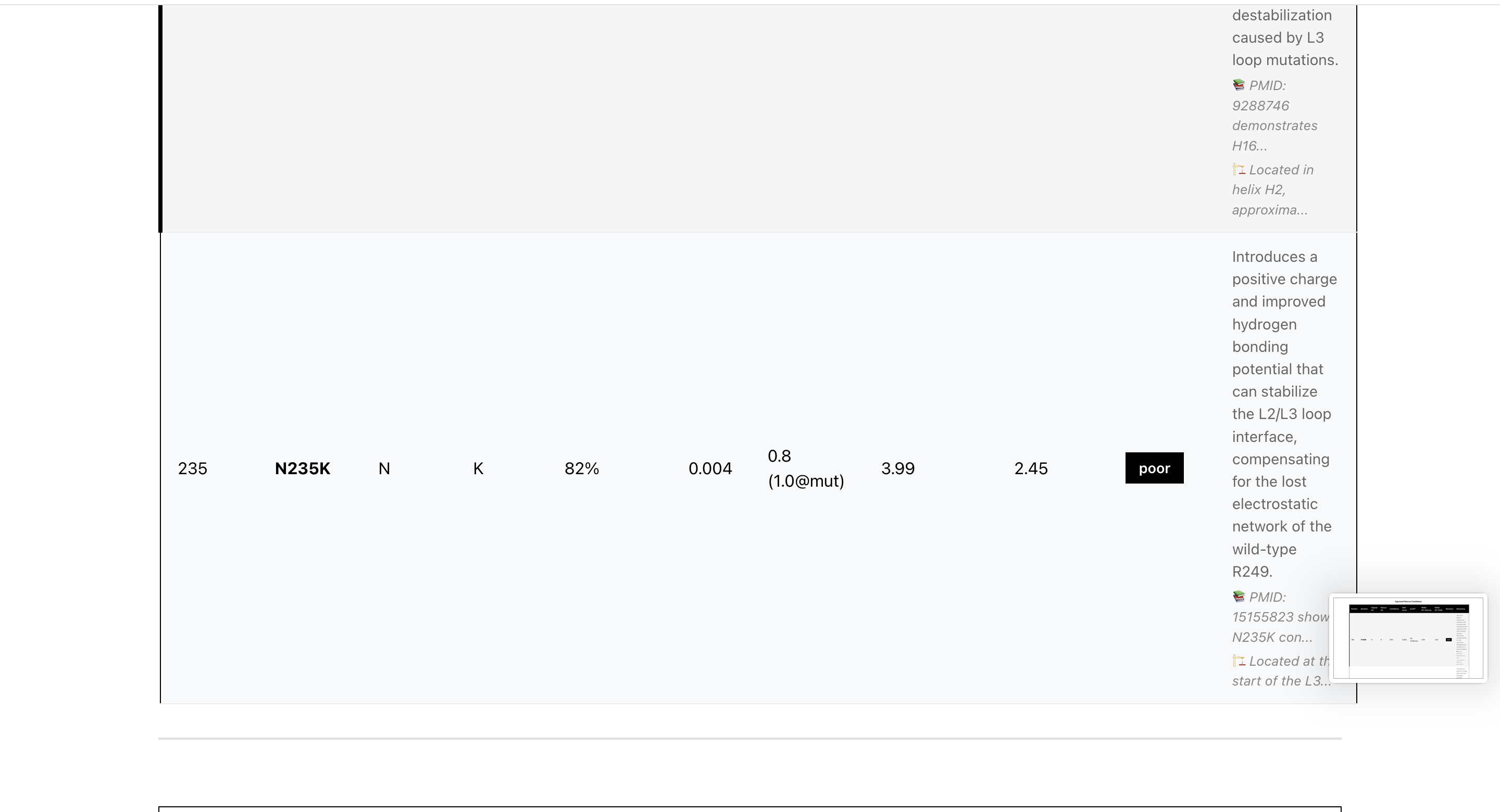
Rescue Candidates2
-
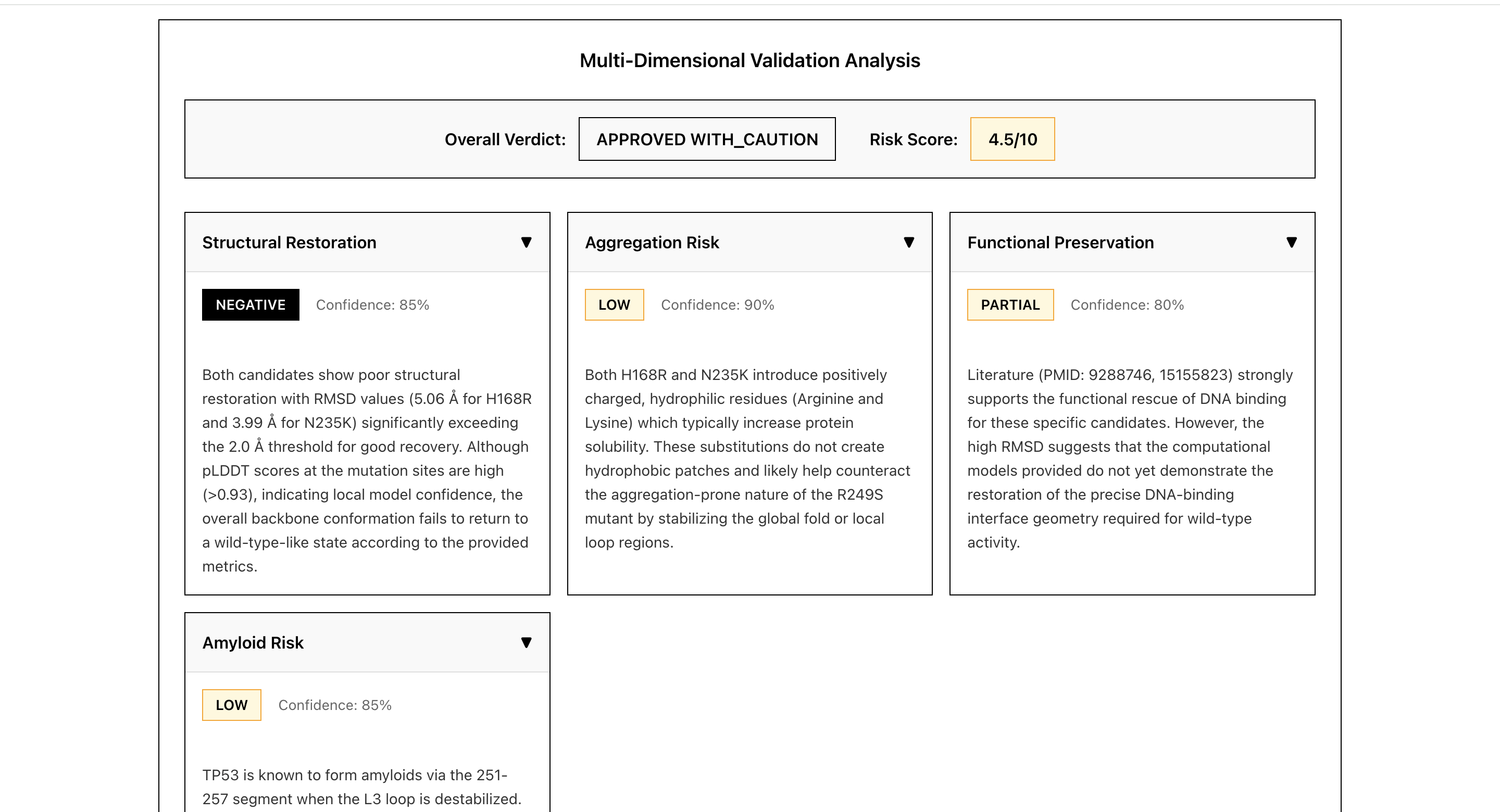
Validation Analysis results
-
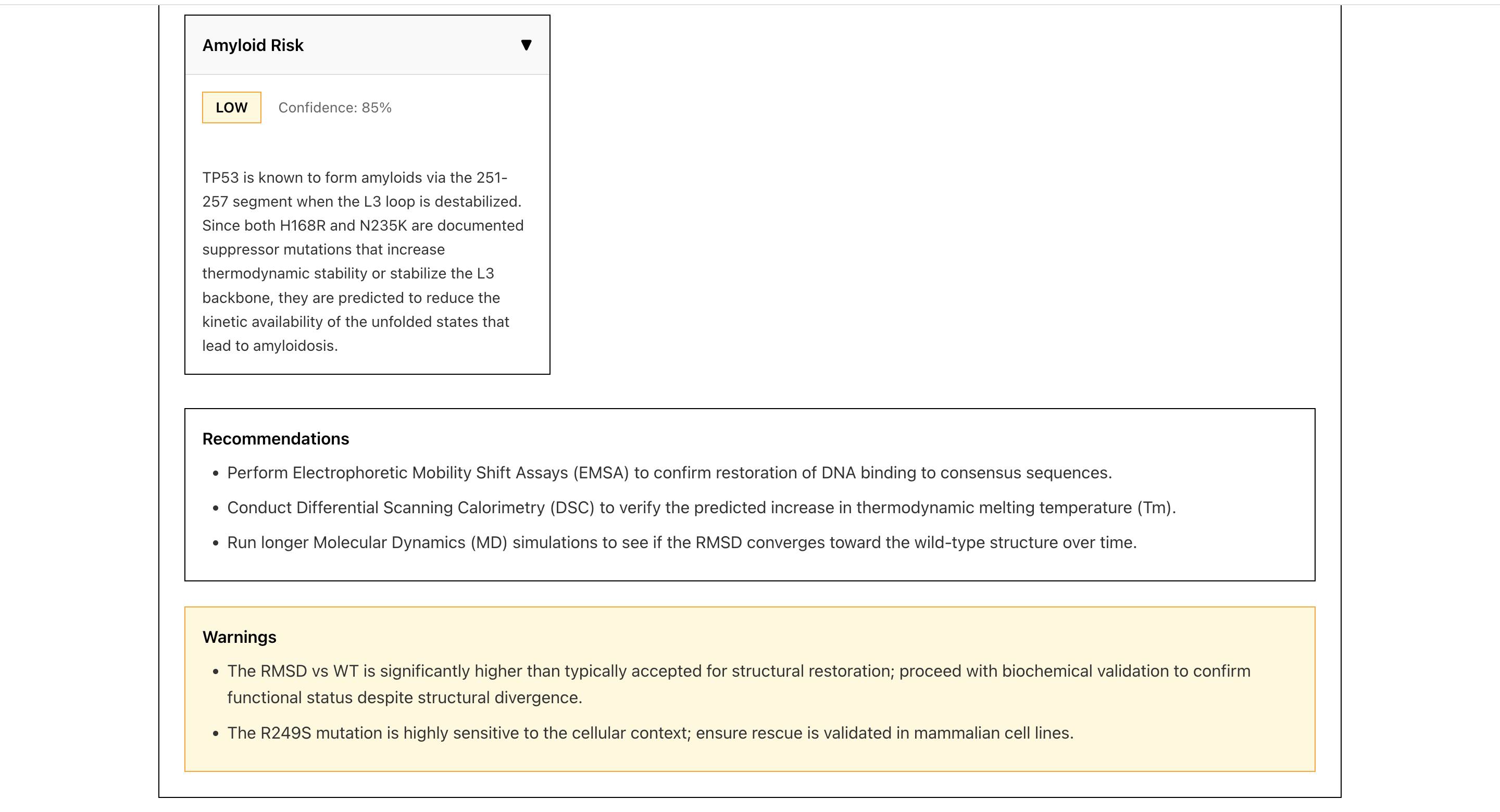
Validation Analysis results2
-
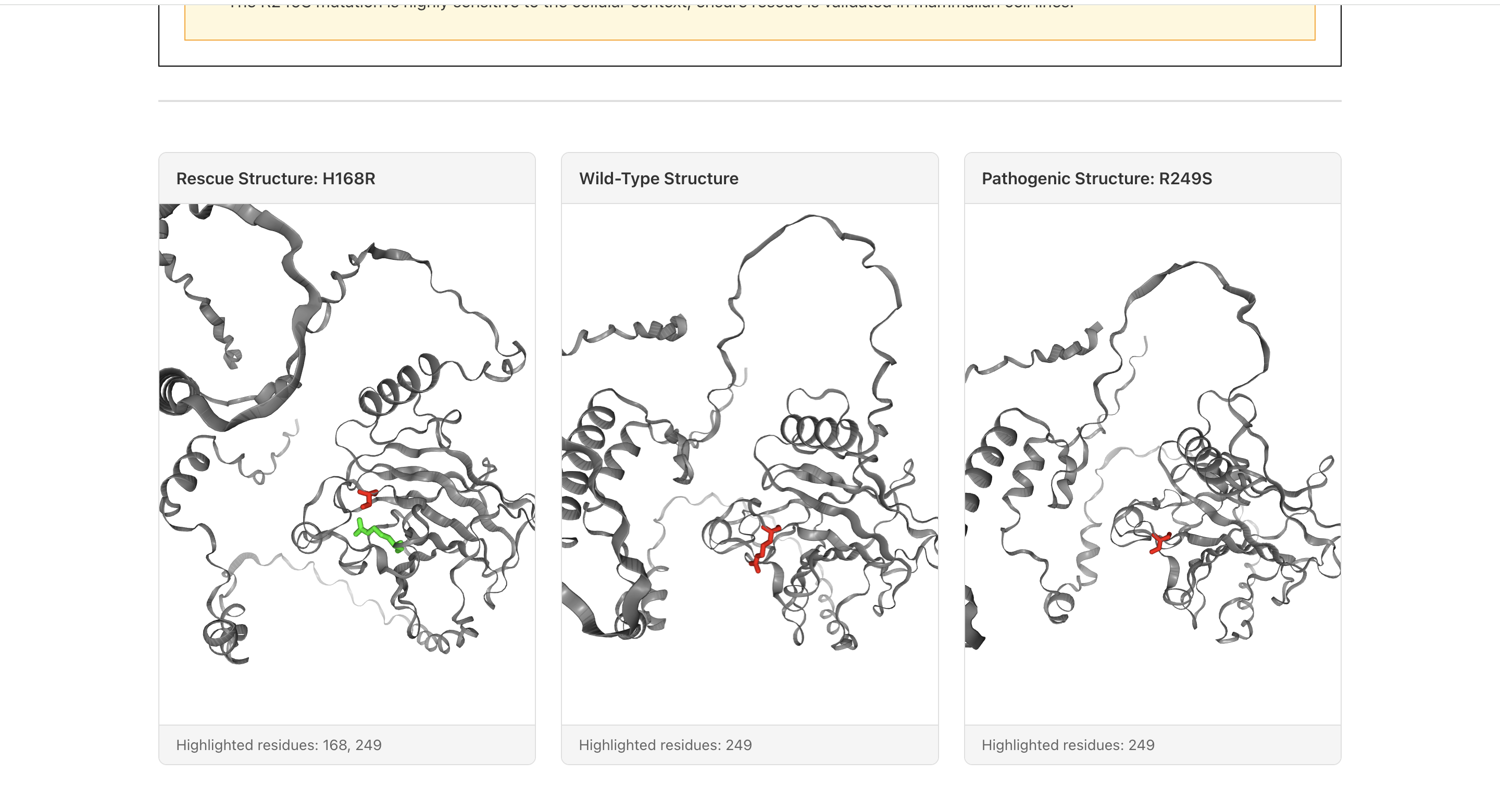
3D structures
Inspiration
The inspiration for Rescue Mutation came from a fundamental question in genetics: What if we could fix a broken gene not by replacing it, but by finding a second mutation that compensates for the first? Traditional approaches to genetic diseases focus on gene replacement or editing expensive, technically challenging, and often impossible. But nature has already solved this problem through intragenic suppression: second-site mutations that restore function to proteins damaged by pathogenic variants. This phenomenon has been observed across species, from bacteria to humans, yet discovering these rescue mutations has remained a lengthy, labor-intensive process requiring years of wet-lab experiments. The advent of large language models like Google Gemini and protein language models like ESM-1v opened a new possibility: Could we leverage AI to mine decades of scientific literature, predict evolutionary fitness, and validate structural restoration all computationally? Could we compress years of laboratory work into minutes? We were particularly inspired by recent breakthroughs:
- AlphaFold/ESMFold proving that AI can predict 3D protein structures with near-experimental accuracy
- ESM-1v demonstrating that language models trained on evolution can predict mutation effects
- Gemini 3 showing unprecedented capability in multimodal scientific reasoning
What it does
Rescue Mutation is an end-to-end AI pipeline that discovers and validates compensatory mutations capable of rescuing proteins damaged by pathogenic missense mutations. Input: A wild-type fasta sequence (DNA/RNA/protein) + a pathogenic mutation (e.g., TP53 R249S) Output: A validated rescue mutation recommendation (e.g., H168R) with 3D model depiction, safety assessment and experimental protocols. Six-Phase Pipeline: Phase 0: Sequence Processing
- Parses FASTA files (DNA/RNA/protein)
- Translates nucleotides to amino acids (if format is DNA/RNA fasta files)
- Uses deterministic algorithm to create the pathogenic mutant sequence
Phase 1: Gemini Literature-Based Discovery
- Leverages Gemini's knowledge of scientific literature
- Analyzes the pathogenic mutation's structural and functional impact
- Identifies 3-5 candidate rescue mutations based on:
- Published compensatory mutations
- Structural biology principles (charge compensation, steric effects)
- Protein-protein interaction networks
- Evolutionary constraints
Phase 2: ESM-1v Evolutionary Validation
- For each Gemini candidate, masks the rescue position in the mutant sequence
- Uses ESM-1v (BioLM API) to predict which amino acid is evolutionarily favored
- Validates if Gemini's prediction aligns with evolutionary fitness
- Filters top k candidates
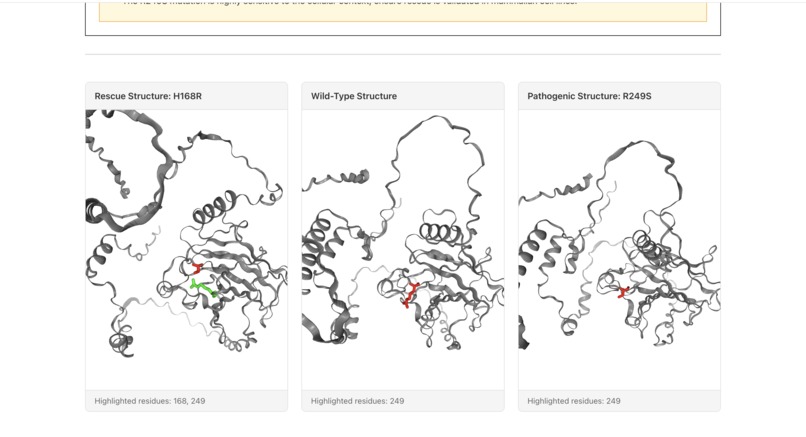
Phase 3: ESMFold Structure Prediction
- Predicts 3D structures for three variants:
- Wild-type (original functional protein)
- Pathogenic mutant (R249S - broken protein)
- Rescue double mutant (R249S + H168R - potentially fixed)
- Uses ESMFold API for fast, accurate structure prediction
- Extracts per-residue confidence scores (pLDDT)
Phase 4: Structural Analysis
- Calculates RMSD (Root Mean Square Deviation) using BioPython
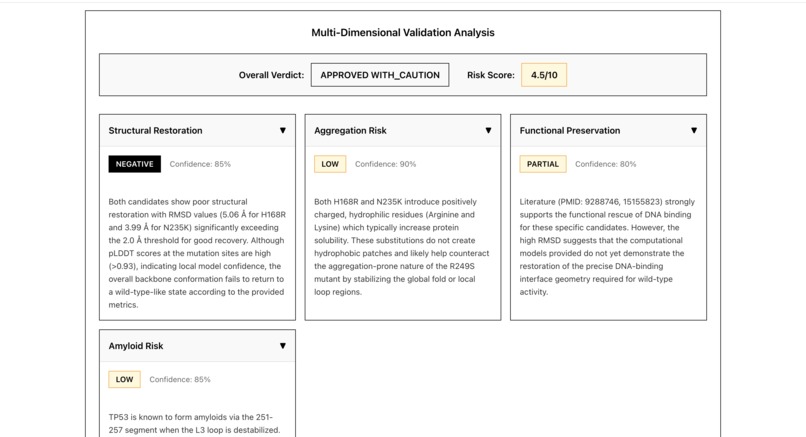
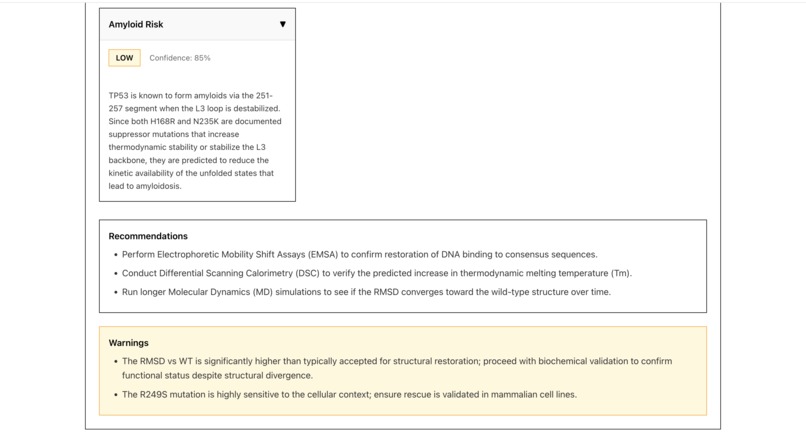
Phase 5: Gemini Final Safety Validation
- Evaluates four critical safety dimensions:
- Structural Restoration: Does the rescue restore wild-type-like structure?
- Aggregation Risk: Does it create sticky hydrophobic patches?
- Functional Preservation: Is the protein's biological function maintained?
- Amyloid Formation Risk: Could it promote disease-causing fibrils?
- Calculates risk score (0-10, lower is safer)
- Provides experimental validation protocols
- Issues final verdict: APPROVED / APPROVED_WITH_CAUTION / FLAGGED / REJECTED
How we built it
Architecture Overview We built GeneRescue as a microservices-style architecture using modern Python best practices: User Request ↓ FastAPI REST API ↓ Pipeline Orchestrator ↓ ┌─────────────────────────────────────┐ │ Phase 0: Sequence Processing │ → Deterministic function │ Phase 1: Gemini Discovery │ → Gemini (Literature) │ Phase 2: ESM Validation │ → BioLM ESM-1v API │ Phase 3: Structure Prediction │ → ESMFold API │ Phase 4: Structural Analysis │ → BioPython │ Phase 5: Final Validation │ → Gemini (Multimodal) └─────────────────────────────────────┘ ↓ 3D Results + Report
Technology Stack Backend Framework:
-FastAPI 0.109+: Modern, fast Python web framework with automatic API documentation -Uvicorn: ASGI server for async operations -Pydantic 2.5+: Data validation and settings management -Python 3.11+: Type hints, async/await, pattern matching
AI/ML Models: -Google Gemini 1.5 Pro: Literature mining and safety validation -ESM-1v (via BioLM API): Evolutionary fitness scoring -ESMFold: 3D structure prediction
Bioinformatics: -BioPython 1.83: PDB parsing, sequence alignment, RMSD calculation -NumPy: Numerical computations for structural analysis
API Integration: -httpx: Async HTTP client for API calls -tenacity: Retry logic with exponential backoff -python-multipart: File upload handling
Challenges we ran into
- Gemini rate limits and 503 “overloaded” errors Challenge: Free‑tier Gemini has a rolling 60‑second token window; calling it twice in the same pipeline (discovery and final validation) frequently triggered 503/UNAVAILABLE errors. Solution:
- Explicit detection of 503/overloaded errors in gemini_service.get_rescue_candidates and final_validation, and special handling with clear error prefixes (e.g. 503_UNAVAILABLE).
- Inserted a hard await asyncio.sleep(60) between Phase 1 and Phase 5 in orchestrator.py so the two heavy Gemini calls don’t overlap in the quota window.
When Gemini is unavailable in Phase 1, we fall back to “demo mode” with zero candidates but still a valid response.
Token / payload limits with structural data Challenge: Passing full PDB strings and images into Gemini would easily blow past token limits, especially in Phase 5. Solution: In build_validation_prompt, we intentionally strip large fields (pdb_structure, pathogenic_pdb_structure, overlay_image) and only send compact numeric/summary metrics (ESM scores, RMSD, qualitative flags).
3D structure visualization in the browser Challenge: Visualizing PDB structures and highlighting specific residues without a heavy build‑time dependency, and handling failures gracefully. Solution:
Used NGL via CDN inside StructureViewer.tsx, with runtime script loading, error handling, and cleanup (stage.dispose() on unmount).
Implemented residue highlighting by grouping positions by color and adding extra cartoon + licorice representations, plus a simple overlay‑image mode toggle when an alignment image is available.
Keeping the API user‑friendly despite long‑running work Challenge: The full 6‑phase pipeline is slow and can be brittle under load (especially with external models). Solution: Added FastAPI‑level rate limiting (via limiter and config‑driven limits), structured logs per phase, and a typed AnalysisResponse model so the frontend can reliably show progress and results, even when some phases degrade.
Accomplishments that we're proud of
- Production-Quality Multimodal AI Integration Successfully integrated three cutting-edge AI models into a cohesive pipeline:
- Gemini 1.5 Pro: Handles both text (literature mining) and images (structure analysis)
- ESM-1v: Evolutionary fitness prediction across 5 model ensemble
- ESMFold: Fast, accurate 3D structure prediction Technical Achievement: Each model speaks a different "language" (prompts, masked sequences, amino acid strings), and we created robust adapters that translate between them seamlessly.
- Comprehensive System Prompt Engineering Created a 500+ line system prompt for Gemini Phase 5 validation that:
- Defines expert persona (computational structural biologist)
- Provides evaluation frameworks for each safety dimension
- Includes decision logic trees
- Specifies exact JSON output format
- Contains example analyses
- Guides mechanistic reasoning Result: Consistent, high-quality safety assessments with scientific depth comparable to human expert analysis.
What we learned
Key Insight: Large language models like Gemini aren't just for chatbots—they're compressed knowledge bases of scientific literature. What worked:
- Gemini can reason about protein structure-function relationships
- It understands concepts like "charge compensation" and "steric clash"
- It can cite (approximate) PubMed IDs for supporting literature
- Multimodal capability allows it to "see" 3D structures
What didn't work:
- Can't calculate precise energetics (not a physics simulator)
- Occasional hallucination of specific PMID numbers (general concepts accurate, specific citations need verification)
- Requires very detailed system prompts for consistent outputs Lesson: Use LLMs for pattern recognition and knowledge retrieval, but validate quantitative predictions with specialized models (ESM, ESMFold).
What's next for Rescue Mutations
Goal: Build a database of validated rescue mutations. Deliverable: Public database with:
- Pathogenic mutation → Rescue mutation mappings
- Confidence scores
- Experimental validation status
- Downloadable PDB structures
Built With
- esm-1v
- esmfold
- gemini
- python
- react
- typescript

Log in or sign up for Devpost to join the conversation.