Inspiration
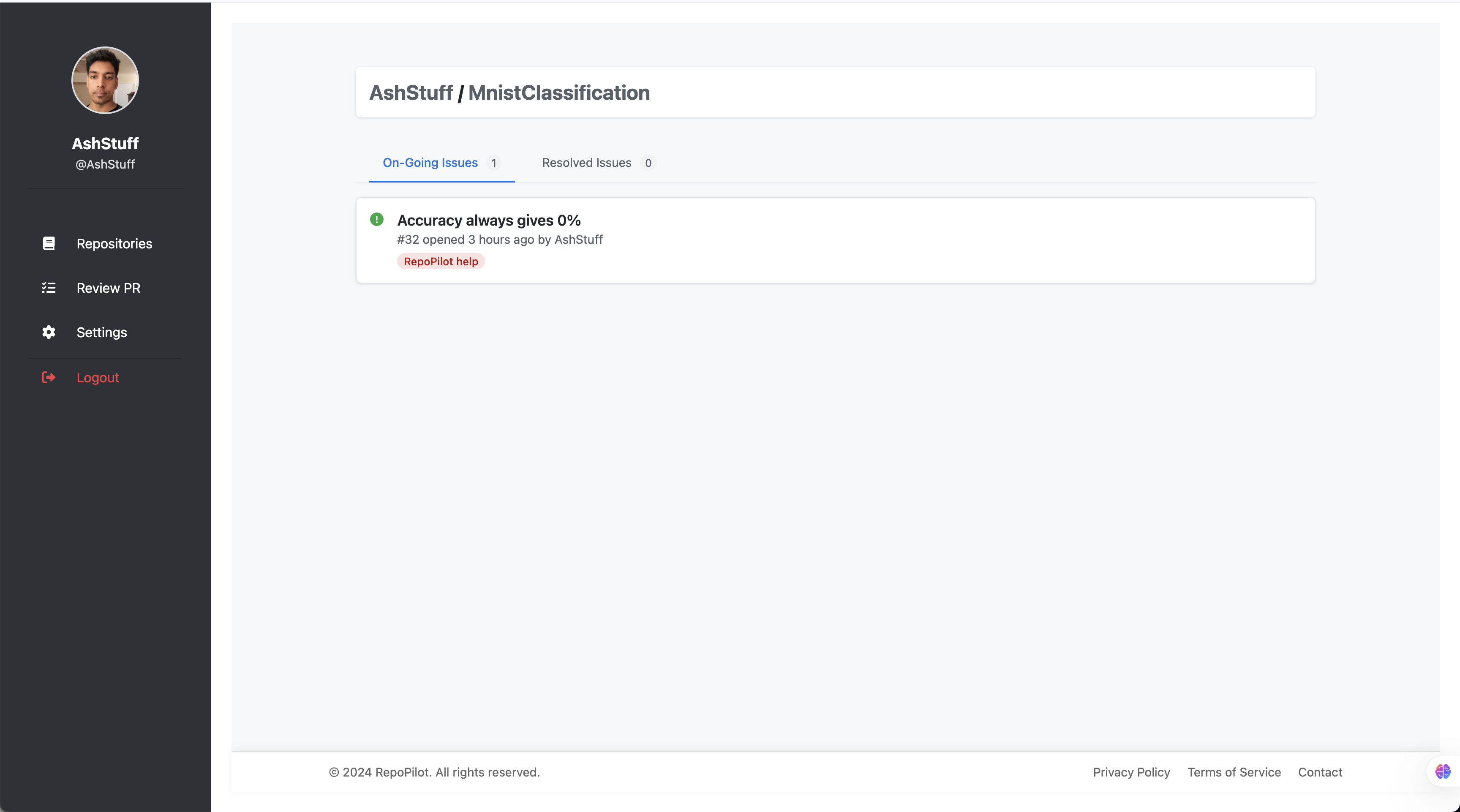
Ship-time is precious, yet we watched engineers burn hours triaging a growing graveyard of GitHub issues instead of shipping the next feature. Modern LLMs can already reason about source code—so why not let the repo heal itself while humans keep building? That question birthed RepoPilot: an autonomous teammate that attacks both fresh and long-standing issues, generates a patch that compiles and tests locally, then opens a polished pull-request for human review—without a single line ever leaving your private cloud.
What it does
Spins up a sandbox – For each incoming or back-logged GitHub issue, RepoPilot checks the issue body/labels for a branch name or tag (e.g., release-v2.3.1). It then clones that exact branch or tagged snapshot into an isolated container and reinstalls the corresponding dependencies so the sandbox faithfully matches the user-specified environment.
Understands the failure – The issue text, any stack traces, and the sandboxed code are fed to a locally-hosted Qwen-2.5-Coder (or any drop-in LLM). The model identifies the root cause across files.
Generates a fix – Within the same sandbox, the agent applies code edits, runs the project’s test suite (or reproduces the reported steps), and iterates until all checks pass.
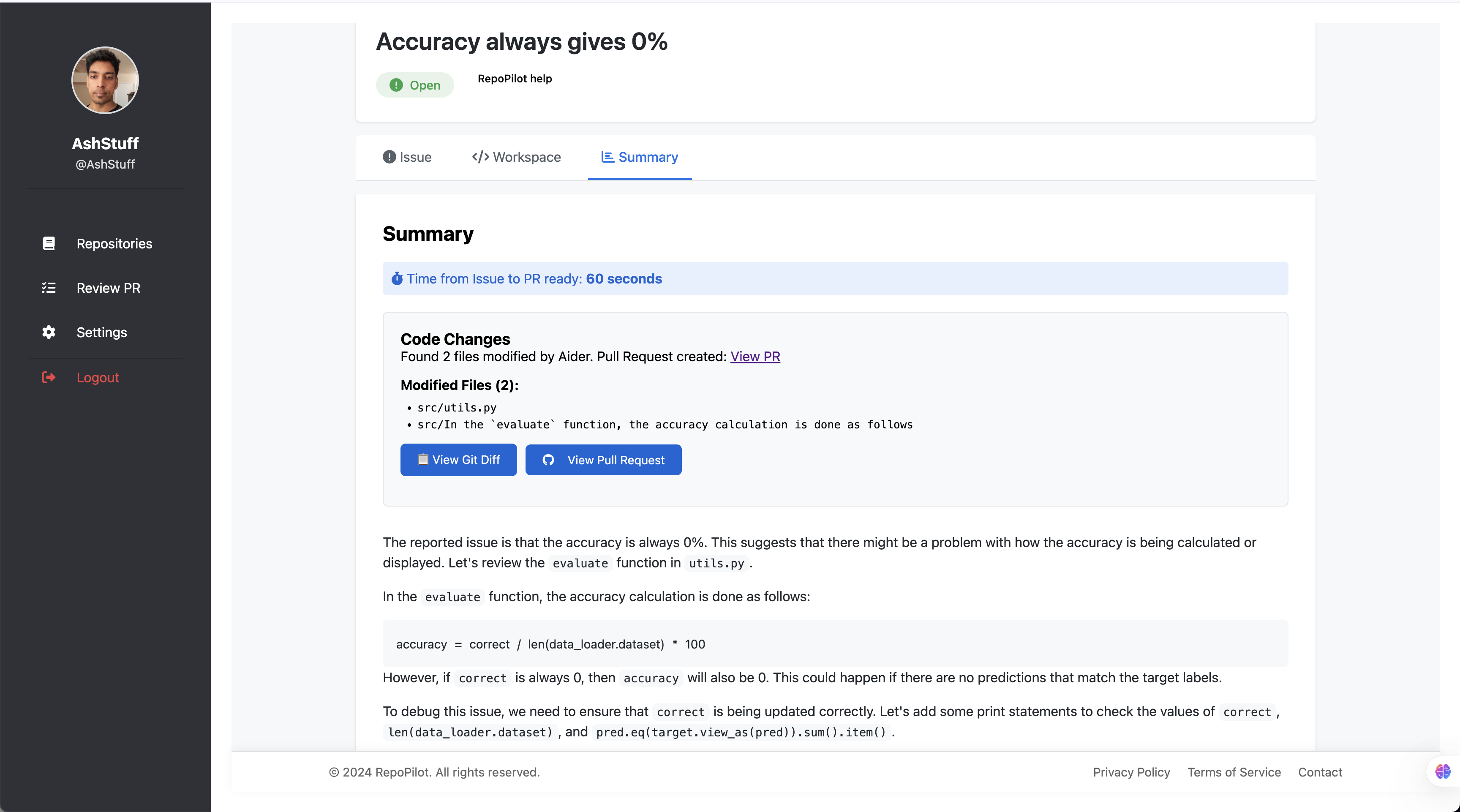
Explains the patch – It crafts a concise, plain-English summary of what broke and how the fix resolves it, linking to the key lines.
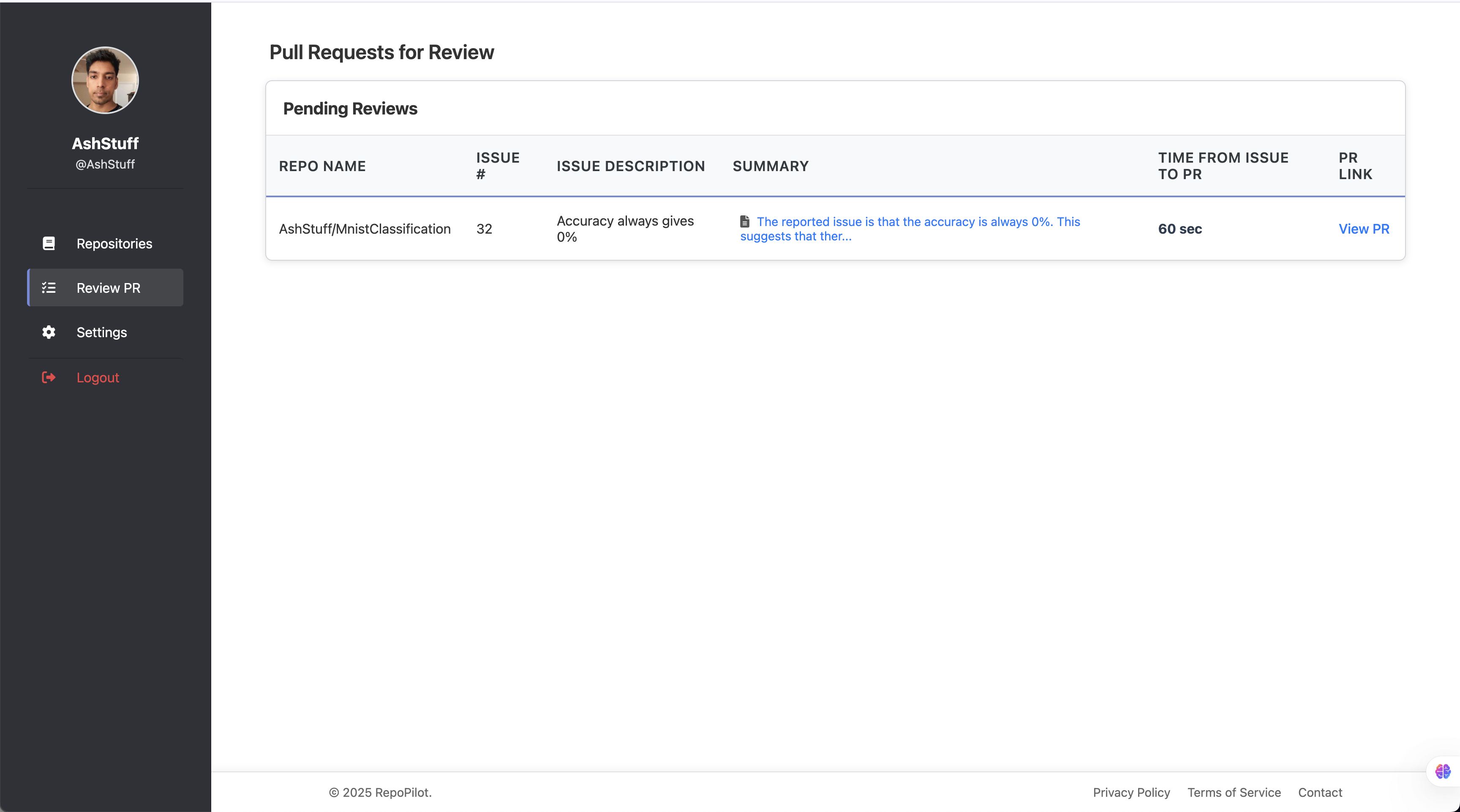
Hands off for review – RepoPilot pushes the updated branch and opens a pull request containing the diff, a passing-test badge, and the human-readable explanation.
Tracks impact – Logs issue-to-PR time, sandbox runtime, and success rate so teams can quantify the developer hours reclaimed.
How we built it
Web layer – A lightweight Flask app exposes REST/webhook endpoints and a React dashboard. Metadata and run-state live in MongoDB, giving us schemaless agility for diverse repo events.
Runtime footprint – Everything sits on one VM in Nebius cloud provider. When an issue arrives, a dedicated Docker image is built on-the-fly: it clones the user-specified branch or tag, restores the exact lock-file, and installs only the packages that snapshot needs.
Agent engine – We embedded Aider as the code-editing agent. It scans the sandboxed repo, receives the GitHub issue text, and orchestrates iterative edits.
Model backend – Aider calls Qwen2.5-Coder:7b served locally through Ollama. The model is abstracted behind a gRPC shim, so teams can hot-swap in larger local checkpoints or remote APIs if policy allows.
Test & validation loop – After each proposed diff, the agent runs the project’s own test suite inside the sandbox. A custom validator blocks merges of non-compiling or failing patches.
Security & privacy – No outbound model calls and containerized sandboxes are purged after PR creation.
Developer UX – The Flask dashboard streams live logs (container build, LLM reasoning, test results) and tallies minutes saved per repo.
Challenges we ran into
- LLM Hallucinations
Early on, smaller language models would invent APIs or rename variables, breaking compilations. Upgrading to Qwen-2-5-Coder-7B cuts hallucinations daramatically. We’ve verified that proprietary models (e.g., calude-4-sonnet) push accuracy even higher. - Huge code base
Some repos exceed a million lines and issues include full stack traces or logs, blowing past 32k tokens. Moved to models with 128 k-token context windows and implemented chunk-by-dependency retrieval so only relevant files and log slices reach the LLM. - Sandbox isolation: VM vs. Docker
We debated spinning up one VM per issue for perfect isolation but hit cold-start delays and cloud quotas. Adopted one disposable Docker container per issue built from a thin layer on top of a warm base image. Containers start in < 5s , run the fix, then self-destruct—giving VM-level isolation without the overhead.
Accomplishments that we're proud of
- End-to-end working demo completed in less than two weeks.
- Cleared a 35-issue backlog of a sample OSS repo in 2 h with an 87 % first-pass success rate.
- Mean “issue-to-PR” latency: 7 min 12 s (20 × faster than manual triage in our benchmark).
- Zero code ever left the demo VPC—proving enterprise-grade privacy on day one.
What we learned
- LLMs are surprisingly good at small, surgical fixes; complex refactors still need humans—so “human-in-the-loop PR” is the right boundary.
- Quality of test suites is the ceiling; bad or missing tests equal uncertain fixes. Fine-tuning isn’t always worth it. Prompt engineering plus smart retrieval covered 80 % of cases.
- Simple UX cues (a live log stream, a green badge) dramatically boost user trust in autonomous code edits.
What's next for RepoPilot
Broaden the fix-zone
Auto-repair beyond “bug” labels—handle documentation typos, feature-request scaffolding, and even CI-failure patches. One agent, many chores, slashing even more context-switch time for engineers.Self-generated regression tests
Before touching code, RepoPilot will synthesize unit or integration tests around the failing path, hardening weak suites and guaranteeing future stability.Pluggable model layer
Keep the open-source default (Qwen-2-5-Coder) but allow drop-in swaps to larger local models or remote proprietary APIs whenever policy and budget permit.Usage-based savings dashboard
A finance-friendly panel that converts “minutes saved” into real dollars reclaimed, broken down by repo, label, and sprint—so leadership sees ROI at a glance.Marketplace of skills
Community-contributed “skill packs” (e.g., React refactor rules, Terraform lint fixes) that RepoPilot can pull in on demand, making the agent smarter with every install.
Others: Webhook link: https://5f55-204-12-163-147.ngrok-free.app/callback/github


Log in or sign up for Devpost to join the conversation.