-

RepoMapr
-
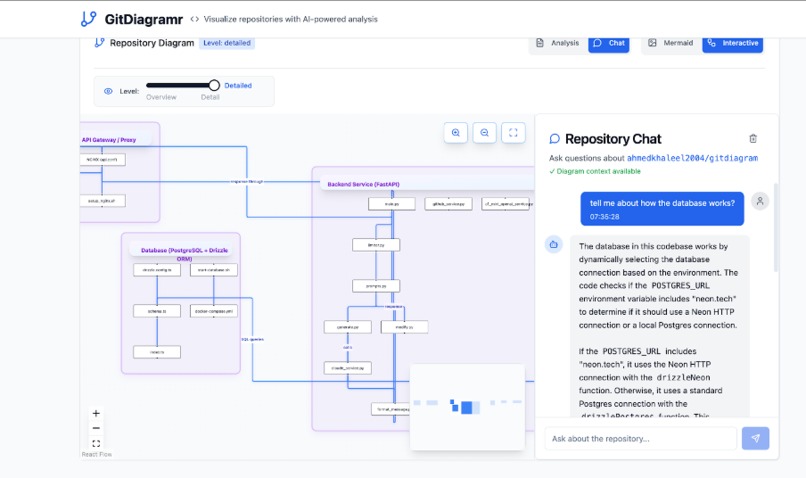
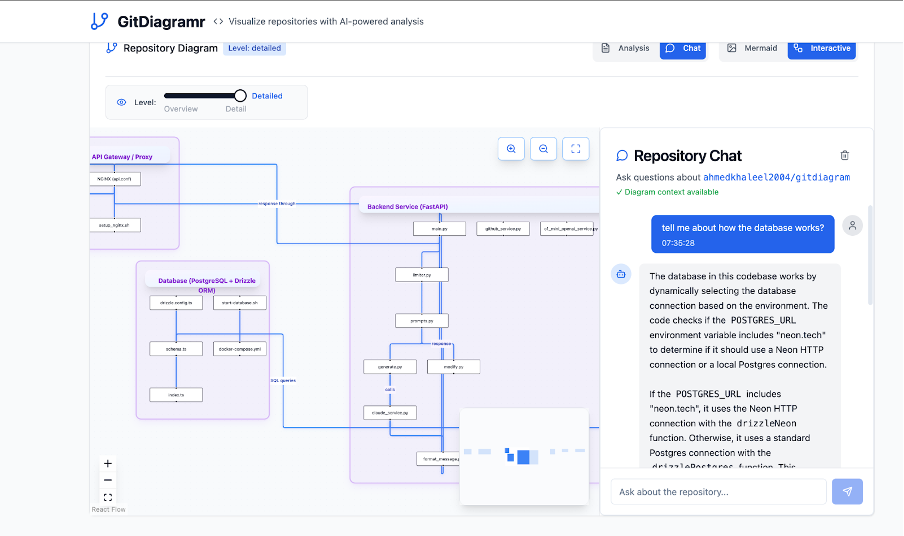
Architecture of our own backend using RepoMapr
-
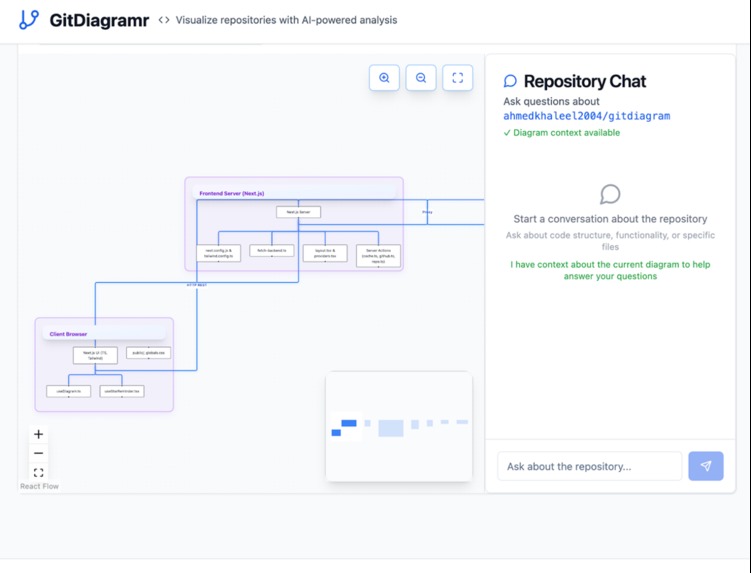
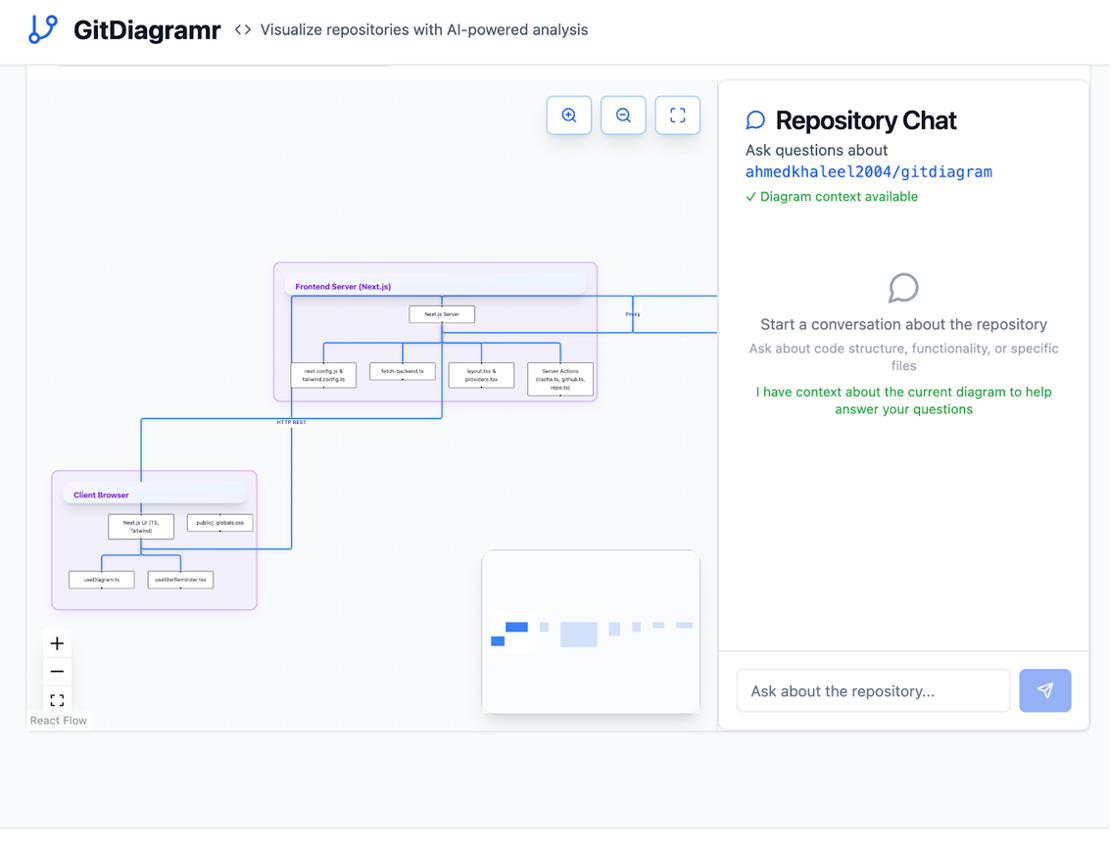
Architecture of our own frontend using RepoMapr

Inspiration
At YC Startup School there was a talk led by Andrej Karpathy, we were shown GitDiagram – a service that generates static architecture diagrams from GitHub repos. The concept was great, but we saw an opportunity to make those diagrams interactive and genuinely insightful. That spark turned into RepoMapr.
What it does
RepoMapr converts any public GitHub repository into an interactive React Flow graph.
- Click a node → view a GPT-4o summary, see the files it contains, and preview raw code.
- Shift-click multiple nodes → inspect their connections and read a combined description.
- Ask questions in natural language (e.g. “How does the Flutter plugin talk to the C++ core?”) and receive context-aware answers with direct links to the code.
How we built it
- Data extraction – Reverse-engineered GitDiagram’s public API to fetch Mermaid sources instead of static images.
- Graph rendering – Transformed Mermaid diagrams into React Flow components with custom edge routing.
- AI layer – Used LlamaIndex to chunk and embed every file, tagging each chunk with metadata (node, github link). Stored embeddings in Deep Lake, a vector DB tuned for ML workloads.
- Custom query engine – Pulls only the relevant vectors from Deep Lake and feeds them to GPT-4o for summarisation or Q&A.
- FastAPI backend – Orchestrates diagram fetch, indexing jobs, and AI endpoints consumed by the React UI.
Challenges we ran into
- Accessing GitDiagram data – Required network-sniffing and reconstructing unsigned requests.
- Mermaid → React Flow – Preserving layout fidelity and nested subgraphs demanded a bespoke converter.
- Embedding pipeline – Explored several vector-store products and embedding approaches before choosing LlamaIndex + Deep Lake for flexibility and speed.
- Performance on large repos – Our first pass struggled with 7 k+ chunks; we wrote an optimised query engine and still have room to optimise indexing and retrieval times.
Accomplishments that we’re proud of
- Shipped a fully-fledged product: live architecture map, node summaries, multi-node analysis, and conversational search.
- Can spin up a live map and embedding index for a new repo in minutes — developers start asking questions almost immediately.
What we learned
- Deep dive into embedding models, code-chunking strategies, and vector indexing.
- Practical lessons on balancing chunk size, metadata granularity, and retrieval latency.
- UX counts: raw-code previews and rich node descriptions greatly increase developer engagement.
What’s next for RepoMapr
- Faster indexing – research incremental and streamed embedding to handle very large repositories quickly.
- Query-time optimisation – refine similarity-search parameters and pruning strategies for lower latency.
- Deeper drill-downs – per-function graphs, diff views, and test-coverage overlays inside each node.


Log in or sign up for Devpost to join the conversation.