-
-
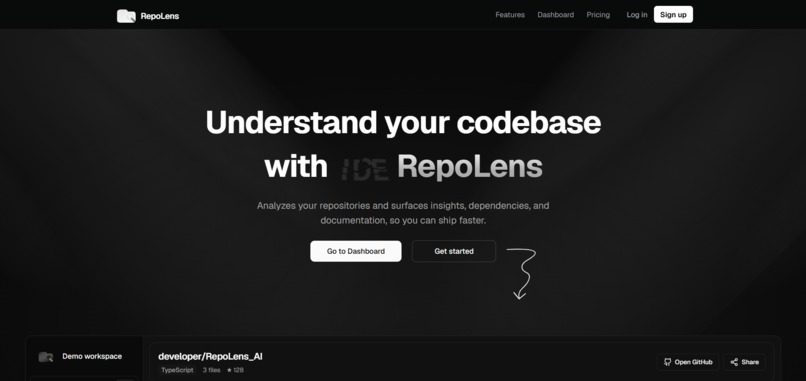
Landing Page
-
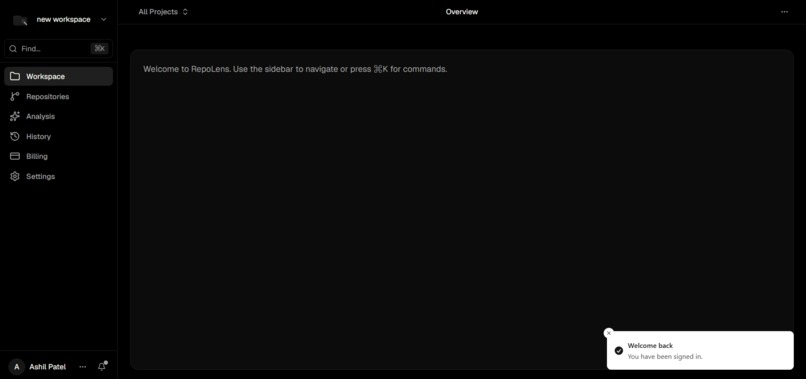
Dashboard
-
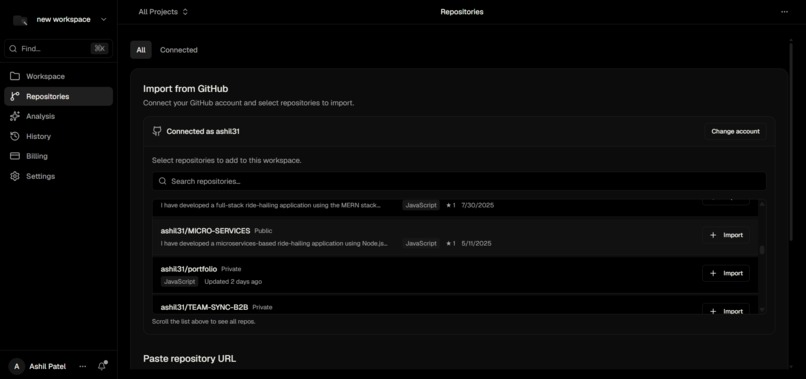
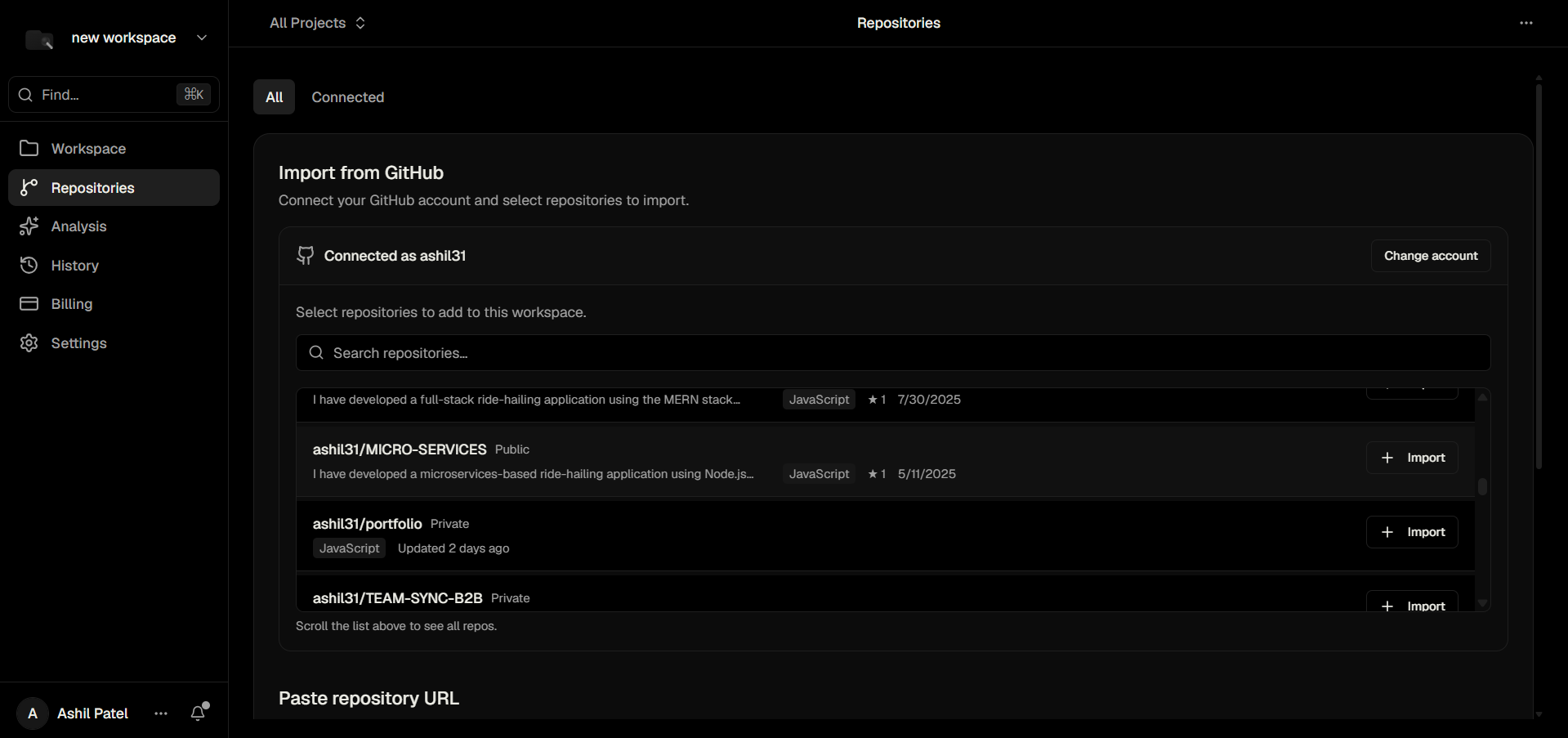
Repositories Page
-
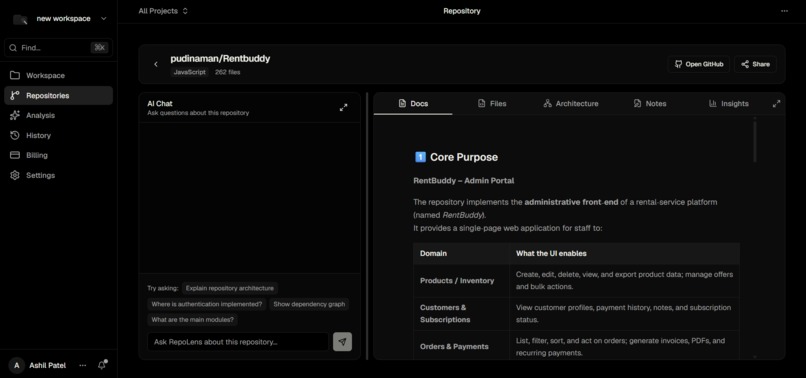
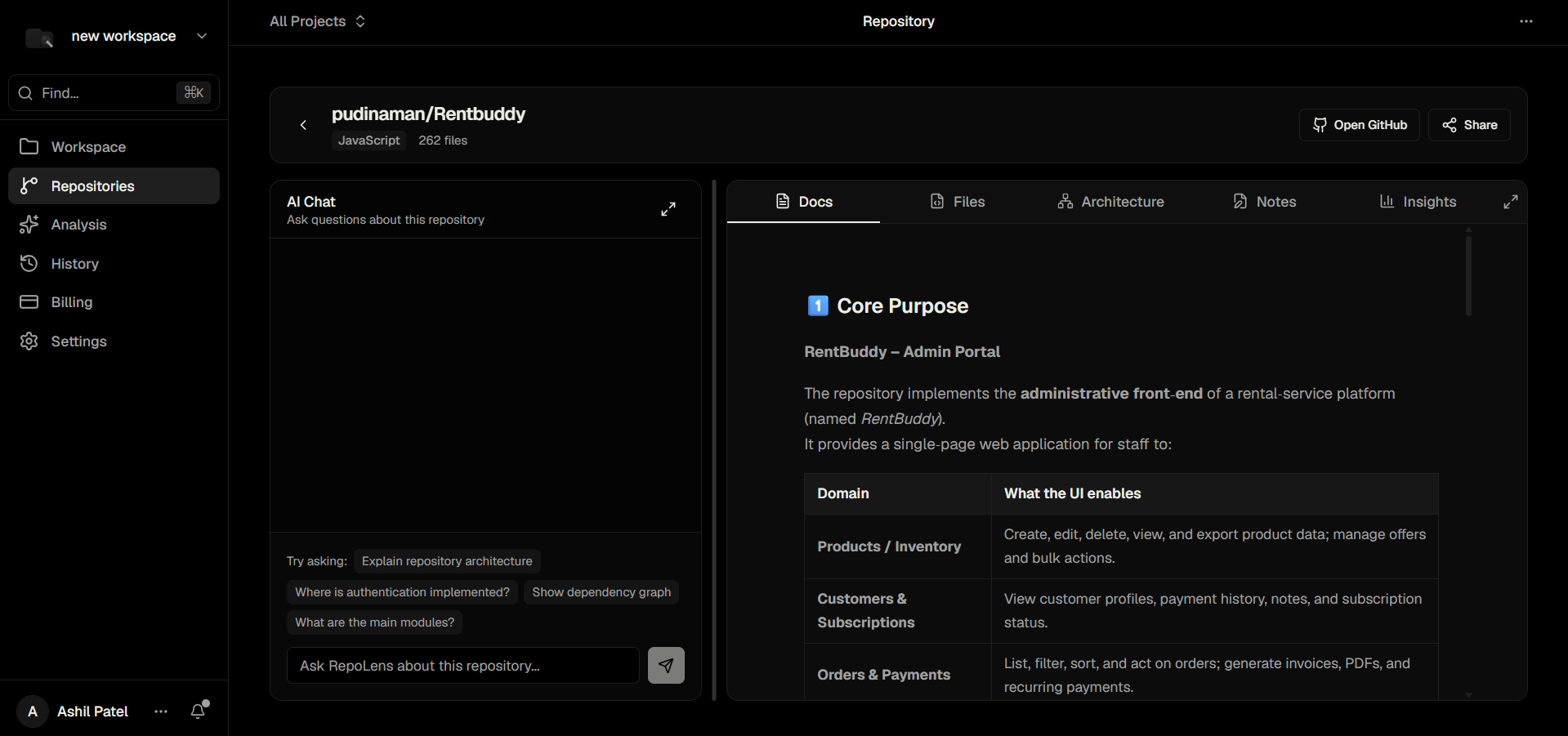
Individual Repo Page
-

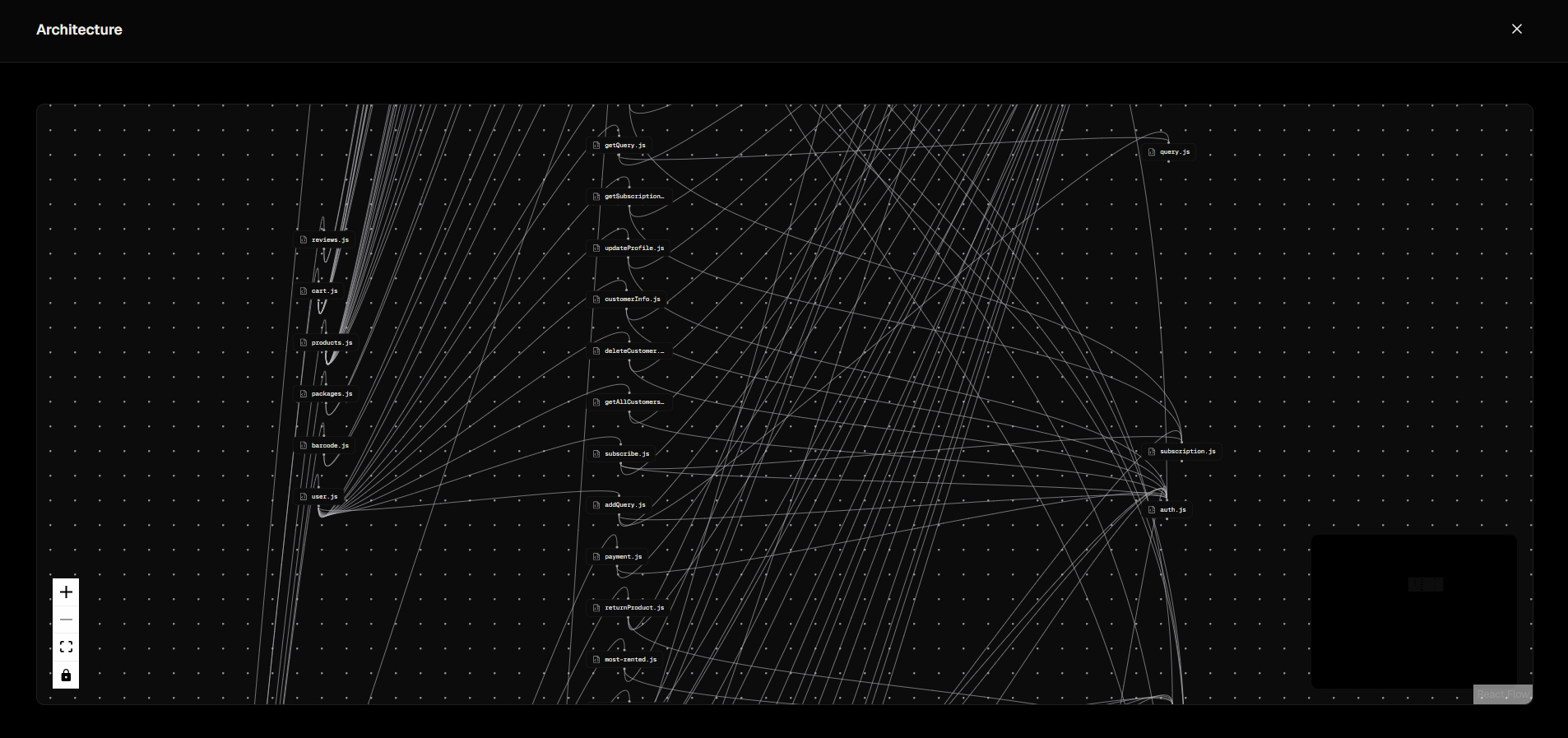
Architecture Graph
-
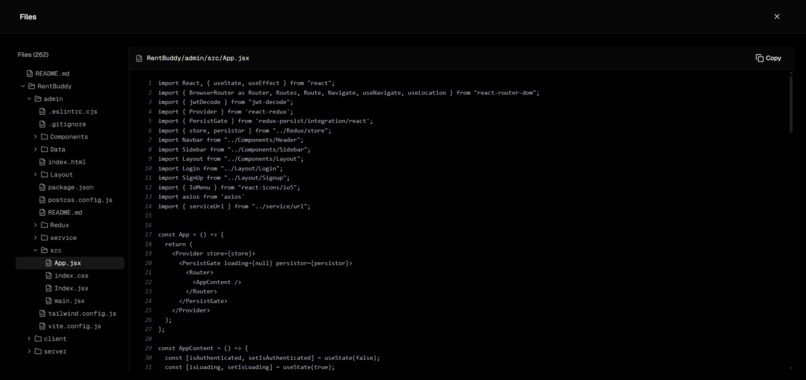
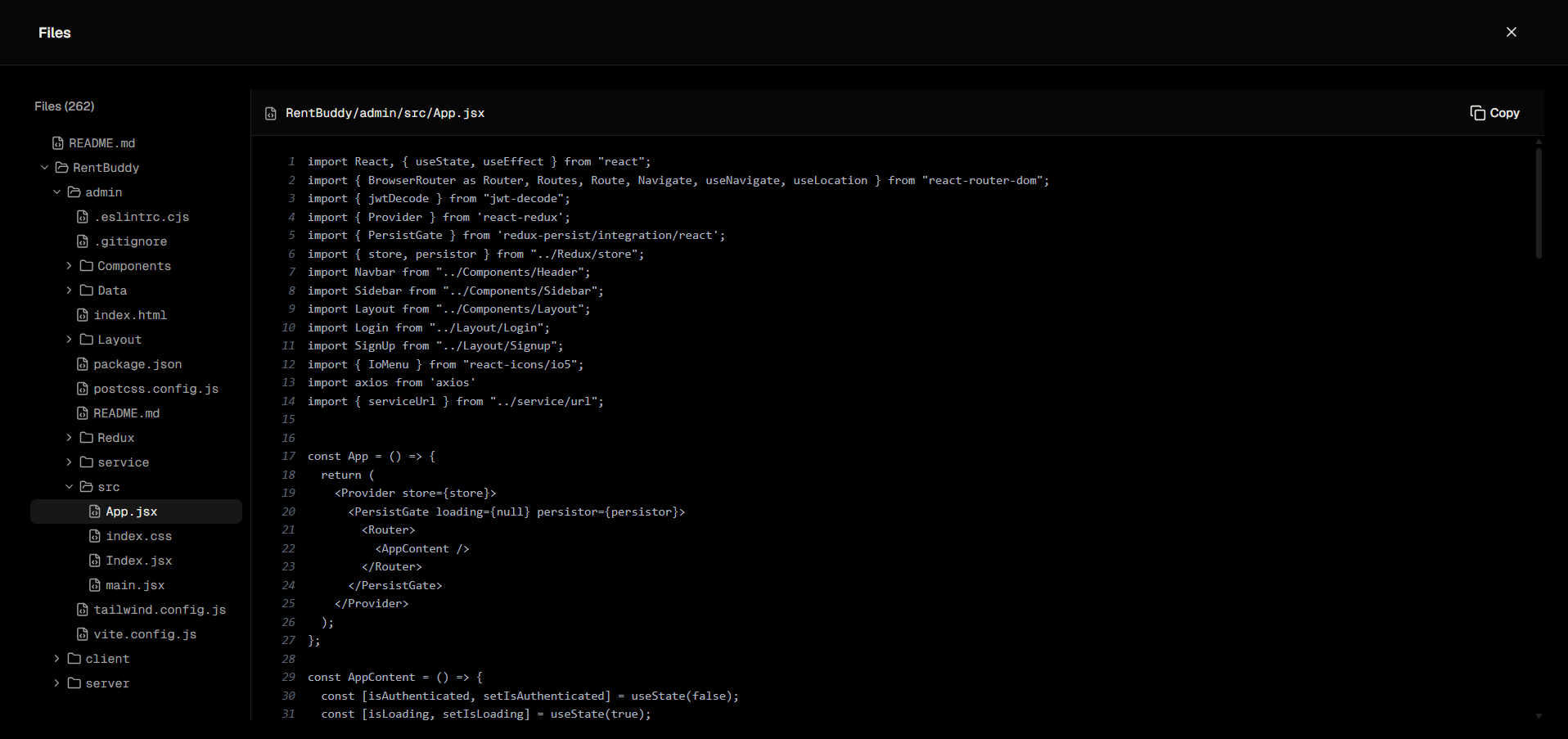
All code files page
-
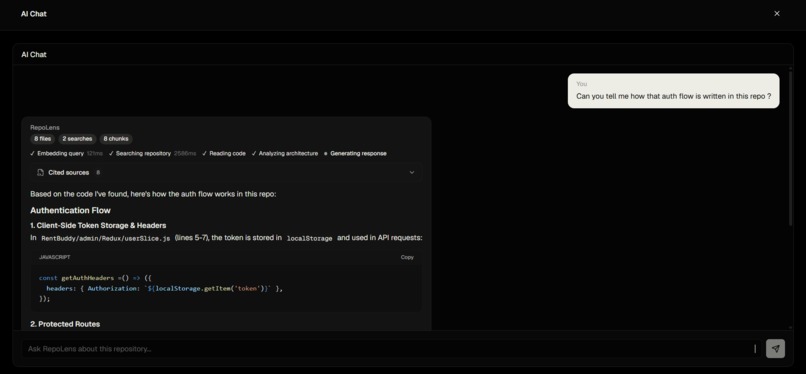
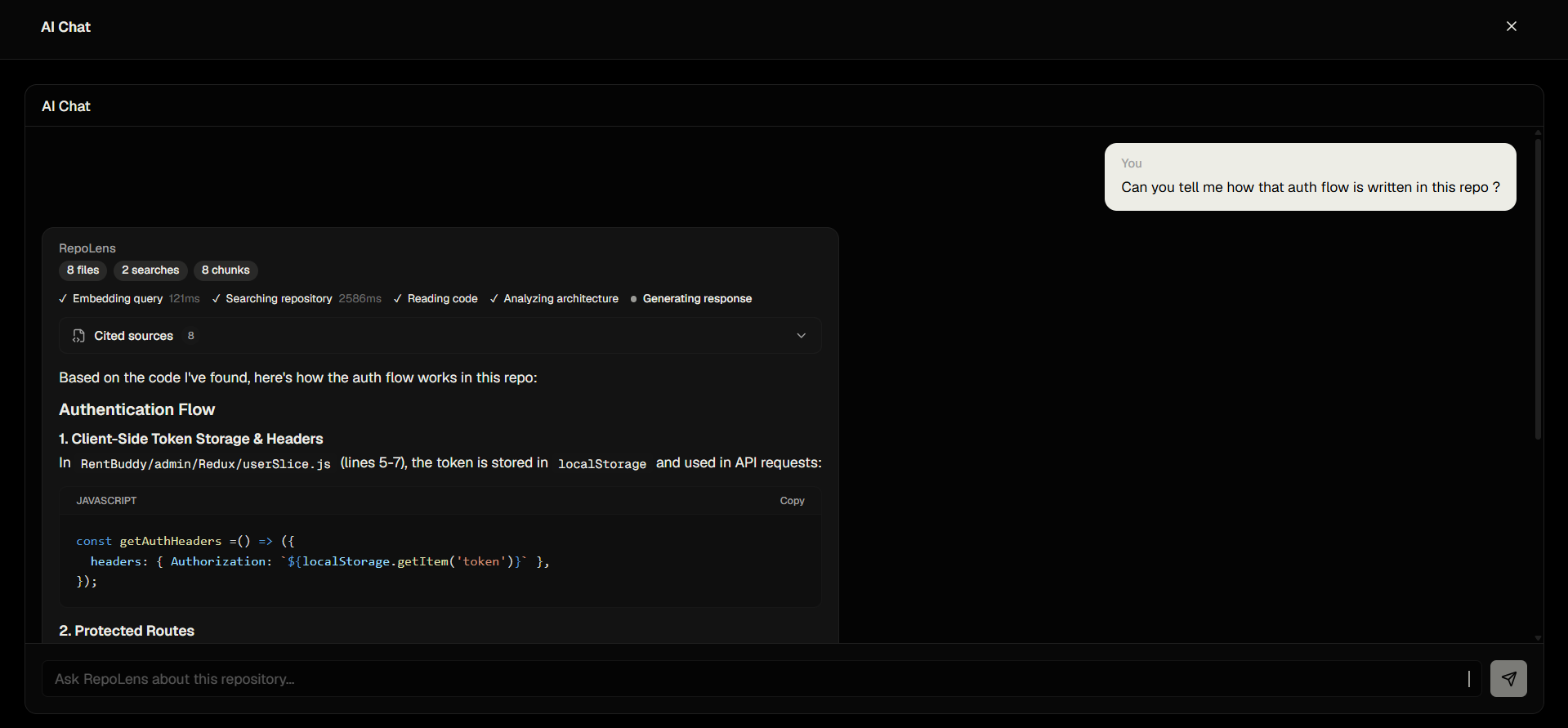
AI Chat Page
Inspiration
Understanding large codebases is one of the biggest pain points for developers. Whether it's onboarding to a new project or revisiting an old one, navigating thousands of files without context is slow and frustrating.
We wanted to build something that acts like an AI-powered guide for any repository, a system that not only reads code but truly understands its structure and relationships.
What it does
RepoLens is an AI-powered repository intelligence platform that helps developers explore, understand, and interact with codebases efficiently.
It provides:
Semantic code search using vector embeddings
Context-aware chat for explaining code
AST-based structural parsing for deep code understanding
Visualization of file relationships and dependencies
Auto-generated documentation from real code context
How we built it
We designed RepoLens as a distributed, full-stack AI system:
Frontend: Next.js for interactive UI and visualization
Backend: Node.js + Express for orchestration and APIs
AI Service: FastAPI for embedding generation and RAG pipeline
Parsing Engine: Tree-sitter for AST-based code analysis
Vector DB: PostgreSQL with pgvector for semantic search
Queue System: BullMQ for scalable background processing
The pipeline:
Repository ingestion
AST parsing and chunking
Embedding generation
Storage in vector database
Retrieval + LLM-based response generation
Challenges we ran into
Efficiently parsing large repositories without performance bottlenecks
Maintaining context across multiple files during retrieval
Reducing noise in vector search results
Designing a reliable RAG pipeline for accurate answers
Handling async processing with queues and workers
Accomplishments that we're proud of
Built a full end-to-end AI system from scratch
Achieved meaningful code understanding beyond simple text search
Implemented scalable ingestion using message queues
Combined AST parsing with embeddings for better accuracy
Enabled natural language interaction with codebases
What we learned
How to design and optimize RAG pipelines for real-world systems
Trade-offs between semantic search vs structural parsing
Importance of chunking strategy in embeddings
Building scalable distributed systems with queues
Integrating AI into developer workflows effectively
What's next for RepoLens
What's next for RepoLens
- Real-time repository syncing
- Smarter code reasoning (multi-file understanding)
- Advanced visualizations (call graphs, architecture maps)
Built With
- bullmq
- digitalocean
- fastapi
- minimaxai
- nextjs
- node.js
- postgreesql
- rag
- redis


Log in or sign up for Devpost to join the conversation.