-
Interface
-
Ingesting data
-
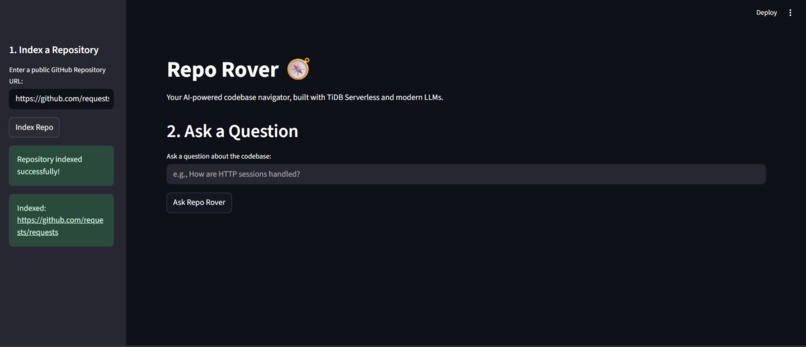
after ingesting data ask a question
-
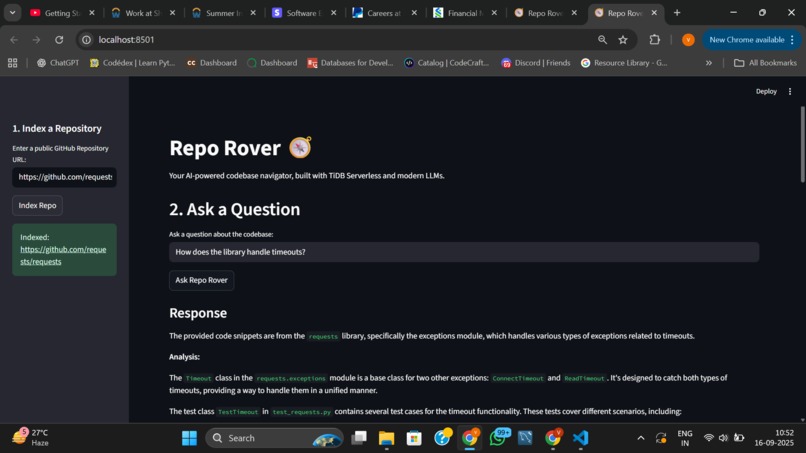
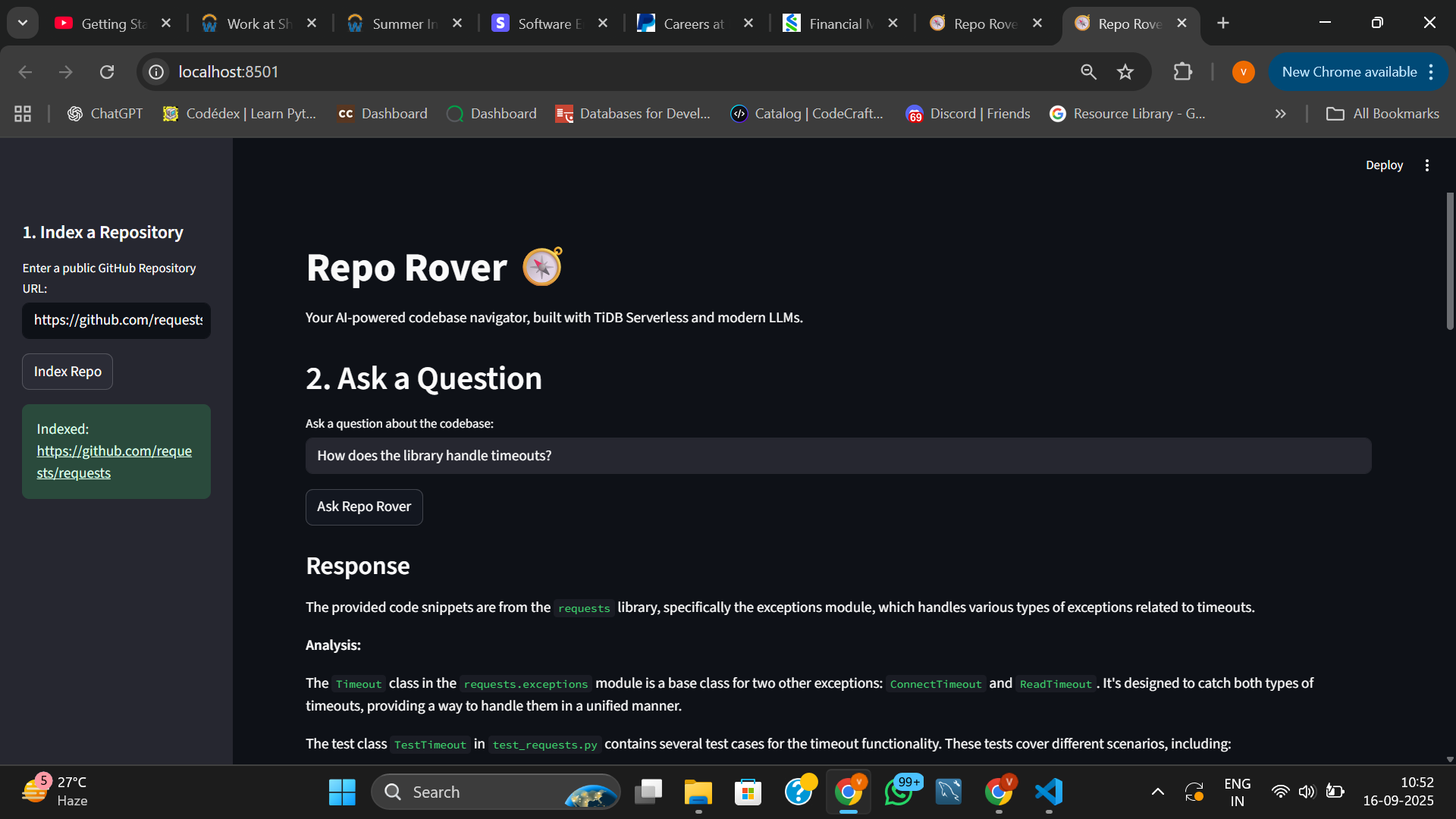
output
Inspiration:
As a developer, I've often faced the daunting task of onboarding to a new project or trying to contribute to a large open-source codebase. The initial days, and sometimes weeks, are spent just trying to understand the architecture, find where key logic is handled, and figure out how different components interact. Traditional text search is often inadequate, as it relies on knowing the exact keywords or function names.
I was inspired to build a tool that could act as an AI-powered "senior developer" sitting next to me, capable of answering high-level, conceptual questions about a codebase. I wanted to leverage the power of vector search to find code based on semantic meaning, not just keywords, and use modern LLMs to synthesize that information into a useful explanation. This led to the creation of Repo Rover.
What it does:
Repo Rover is an interactive web application that allows a user to ingest an entire public GitHub repository and then ask questions about it in plain English. For example, a user can index the Flask repository and ask, "How are HTTP sessions handled?"
The application then performs a two-step agentic workflow:
Retrieval: It searches a vector database (TiDB Serverless) to find the most relevant functions and classes related to the user's question.
Augmented Generation: It feeds this relevant code as context to a large language model (Llama 3), which then provides a detailed analysis of the code's purpose and offers suggestions for refactoring or improvement.
The result is a tool that dramatically accelerates the process of understanding and navigating unfamiliar code.
How I built it:
Repo Rover is a Python-based application built on a modern, multi-component stack:
Database: TiDB Serverless was the core of the project. I used it to store the vector embeddings of every function and class from a codebase. The VECTOR data type and the VEC_COSINE_DISTANCE function were crucial for performing efficient semantic searches.
Frontend: Streamlit was used to create a simple, clean, and interactive web interface where the user can input a repository URL and ask questions.
Backend & Agent Logic: LangChain was used to orchestrate the entire agentic workflow. It connects the data retrieval from TiDB to the prompt templates and the final call to the language model.
AI Services: The project uses a hybrid AI approach:
Google Gemini (text-embedding-004) is used for the critical task of generating high-quality vector embeddings from the source code during the ingestion phase.
Hugging Face Inference API (Llama 3) serves as the "brain" or chat model of the agent, providing the final analysis and suggestions.
Data Ingestion: A standalone script (ingest_data.py) handles the process of cloning the repository, parsing the Python code using the ast library, generating embeddings via the Google API, and storing the data in TiDB.
Challenges I ran into:
Building a system with this many interacting components was a significant challenge and a fantastic learning experience. My main hurdles were:
API Integration: I initially faced and overcame strict rate limits with the Google Gemini API's free tier. This forced me to optimize my agent from a two-call to a single-call chain. I also navigated several "model not found" and authentication errors, which led me to switch chat models and learn the specific library requirements for providers like Groq, Anthropic, and Hugging Face.
Database Queries: The vector search functionality was powerful but required precise syntax. I debugged a persistent FUNCTION ... does not exist error, which was ultimately solved by realizing the vector function names in TiDB are case-sensitive (VEC_COSINE_DISTANCE).
Secure Credential Management: Early on, GitHub's Push Protection feature correctly blocked my pushes because I had hardcoded API keys. This led me to implement a professional and secure workflow using .env files and a .gitignore file to protect my secrets.
Environment and DevOps: I troubleshooted several local environment issues, from platform-specific commands (like rm on Windows) to persistent file locks that required making my cleanup code more robust with Python's tempfile and shutil libraries.
Accomplishments that I'm proud of:
I am incredibly proud of building a fully functional, end-to-end application that solves a real-world problem for developers. Successfully integrating three distinct cloud services (TiDB Cloud, Google AI, and Hugging Face) into a single, seamless agentic workflow as a solo developer was a major accomplishment. Overcoming the numerous technical challenges taught me a great deal about resilience and methodical debugging.
What I learned:
This project was a deep dive into the practicalities of building modern AI applications. Key learnings include:
The immense power of vector search for understanding unstructured data like source code.
The critical importance of securely managing API keys from the very beginning of a project.
The nuances and trade-offs between different LLM providers and their respective free tiers and library integrations.
The necessity of writing robust, platform-agnostic code to handle file system operations and other environment-specific tasks.
What's next for Repo Rover:
Repo Rover is a solid proof-of-concept with a lot of potential for growth. Future steps I'd like to explore include:
Multi-Language Support: Extending the parsing and ingestion logic to support other languages like JavaScript, Java, and Go.
IDE Integration: Building a VS Code extension that allows developers to ask questions directly from their editor.
Automated Code Suggestions: Moving beyond just suggesting refactors to allowing the agent to generate and apply code patches.
Pull Request Analysis: Adding the ability to analyze a GitHub pull request and provide an automatic summary of changes and potential issues.

Log in or sign up for Devpost to join the conversation.