Inspiration
One of teammates, was a new software dev intern. On his first day he was given a github repository owned by the company that was complex and was gigantic in size. He struggled to read and understand every file and its code structure as well as the functions classes the company used for its tech stack.
What it does
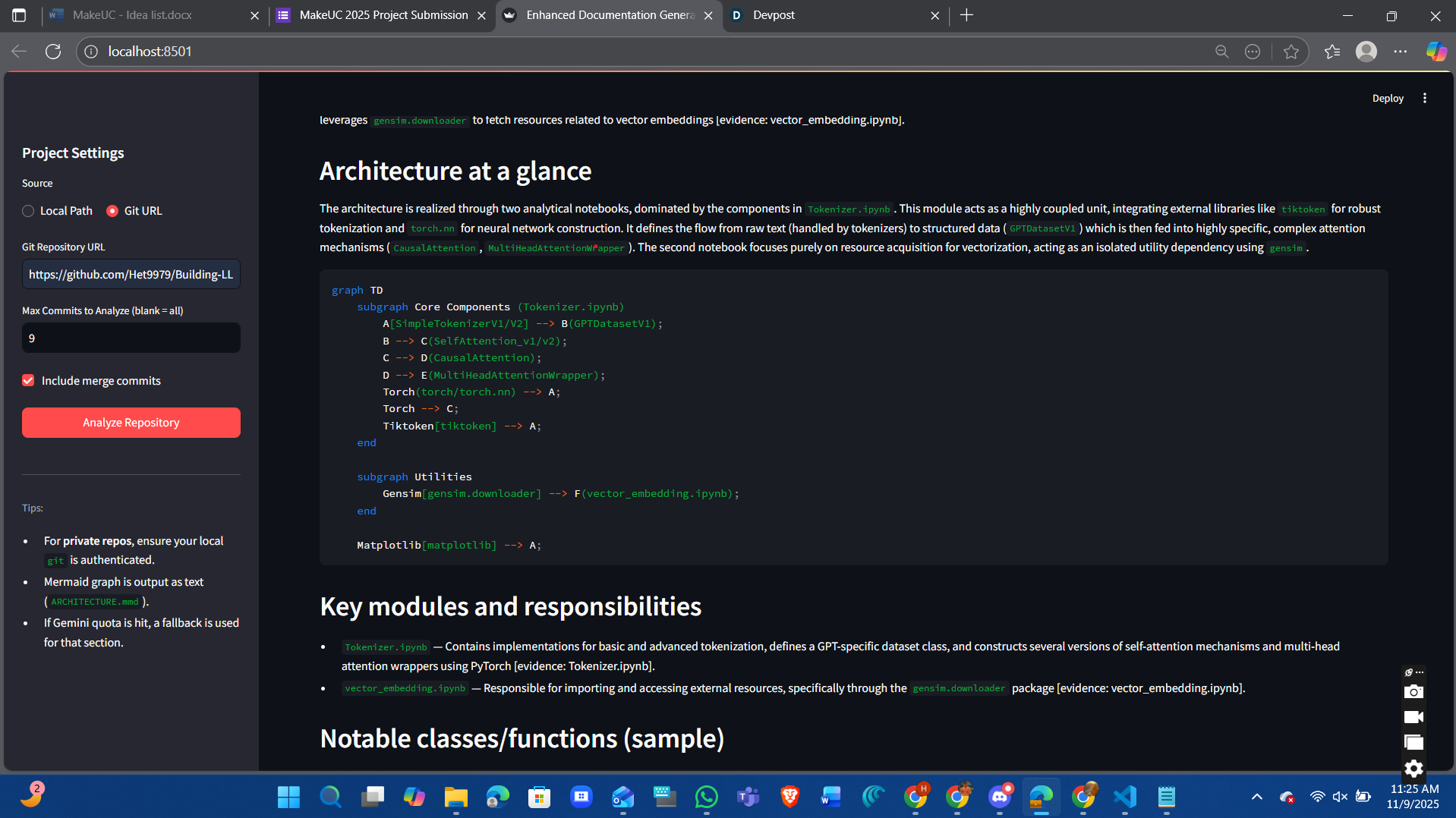
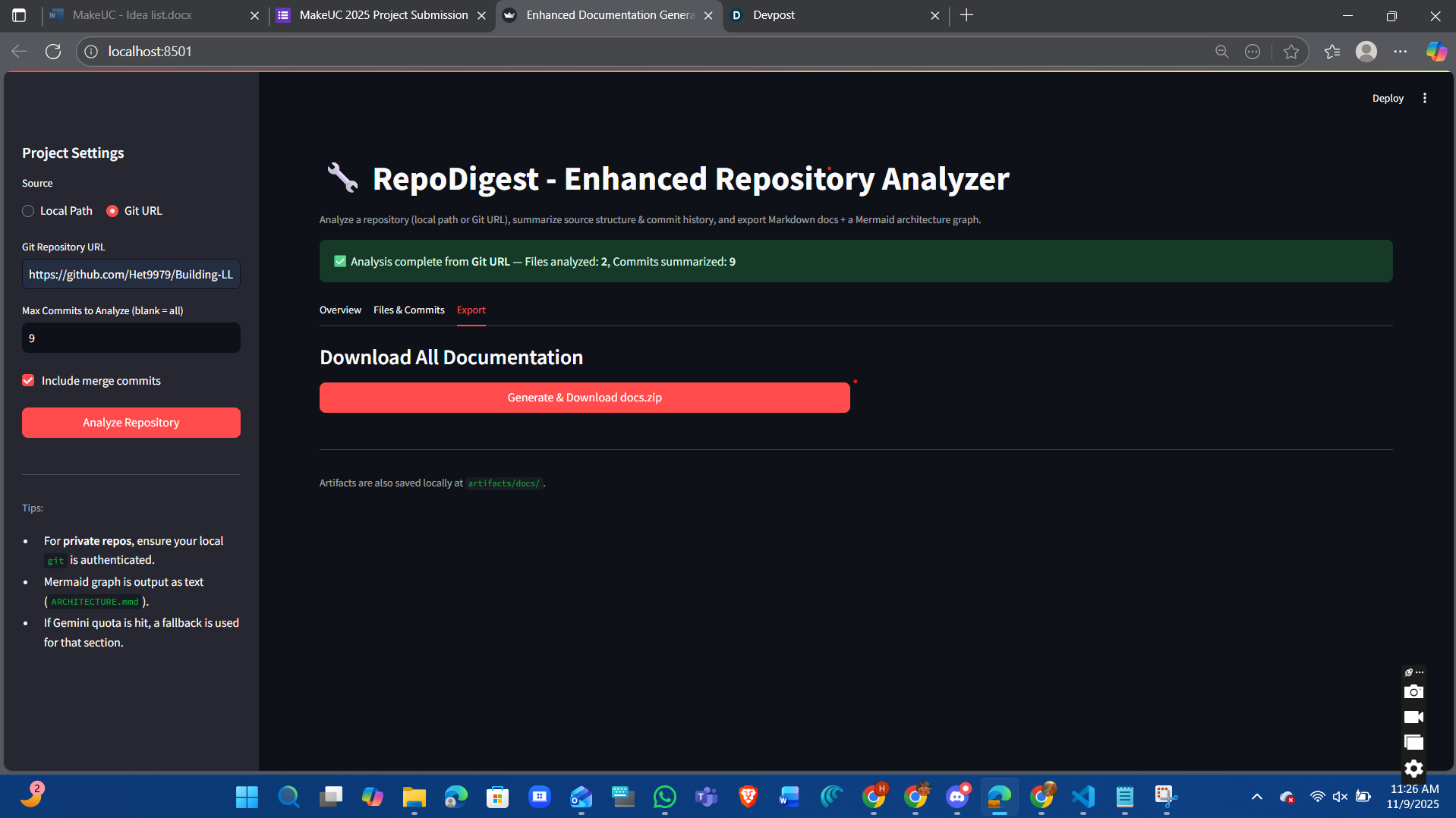
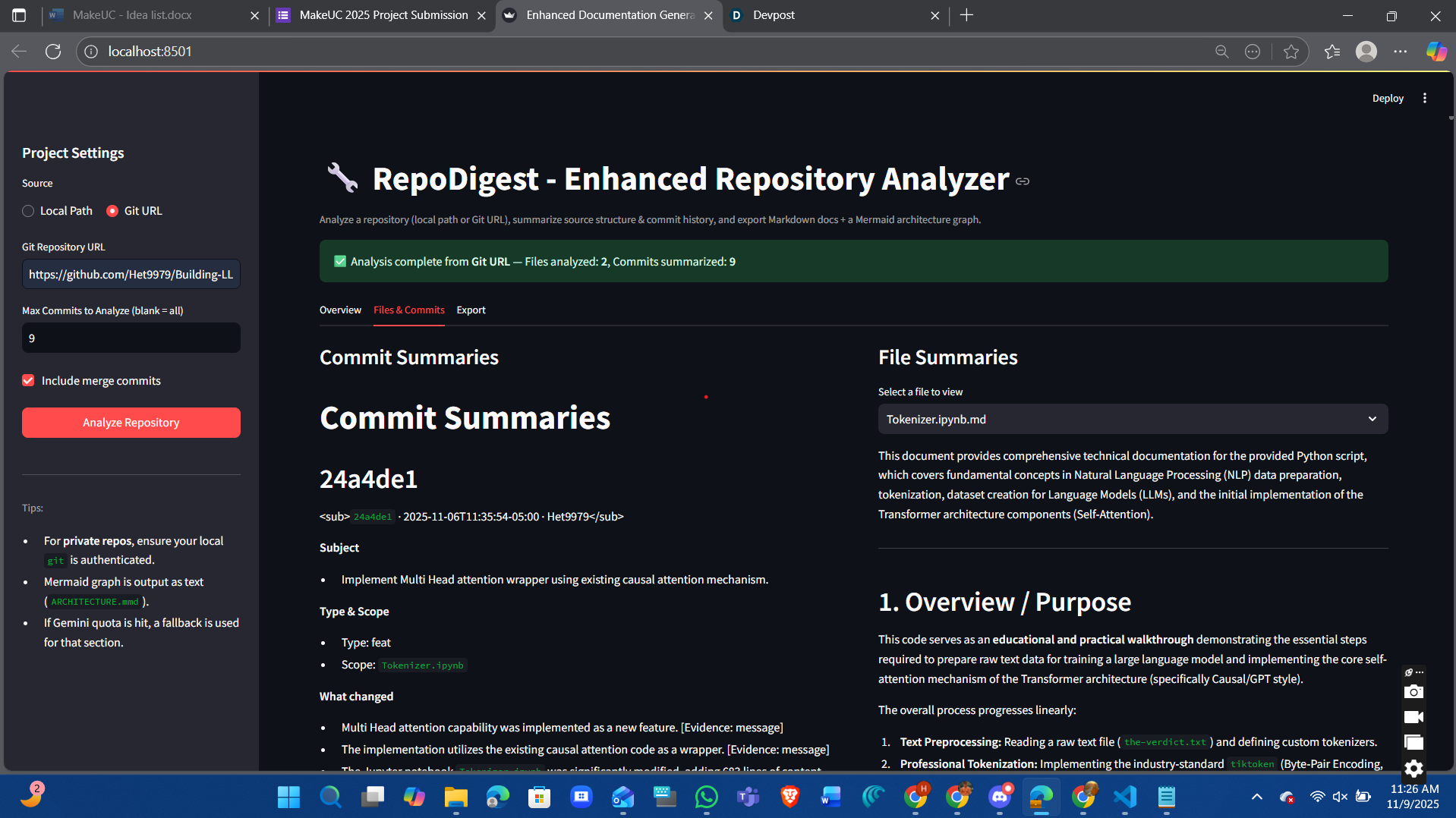
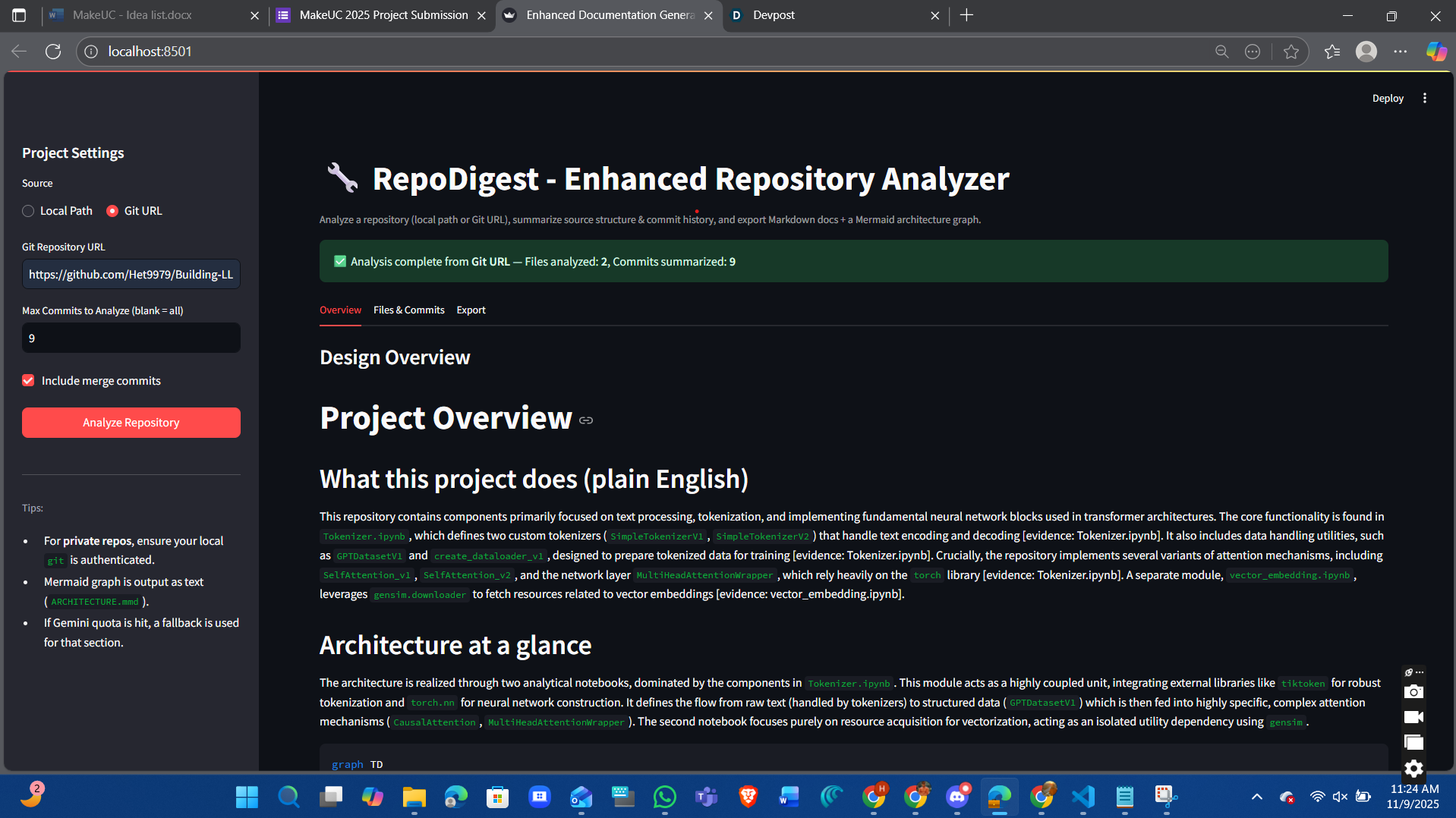
The repo digest is a web app that allows a developer to insert a github repository link. Once inserted and when the user clicks "Analyze Repository". The web application analyzes files, commit history, functions, classes, subclasses, and imports. The web application will also go through line by line of code to analyze and summarize the general idea of the code, functionality and purpose.
How we built it
We used python for the entire project as well as different libraries such as streamlit, FastAPI, uvicorn, pydantic, requests, pydriller, and markdown. We also utilized AI to help better understand each library.
Challenges we ran into
Route wiring & startup: 404s and “app not found” fixed by registering both /analyze + /analyze/ and exporting app cleanly. Data contracts: mismatched shapes/keys across modules (e.g., summary_md, short_hash) standardized with safe defaults. Git/PyDriller quirks: shallow clones and ModifiedFile attribute issues handled via full clones + guarded access. Code parsing: AST walker now robust to encodings, large files, and skipped dirs; strictly discovers .py modules. LLM stability: Gemini 429s/empty responses mitigated with model auto-pick, retry/backoff, and deterministic prompts. Overview accuracy: removed hallucinations by building a “facts-only” summary from parsed modules before LLM. Exports/UI: ZIP solid; PDF needs optional reportlab; Streamlit rerun quirks handled to keep buttons predictable. Windows specifics: normalized paths, consistent 127.0.0.1, and shell-independent git calls to avoid env pitfalls.
Accomplishments that we're proud of
End-to-end pipeline: Git/Local → clone → AST parse → LLM docs → artifacts → export. Facts-first overview built from real code (functions/classes/imports), not guesses. Commit intel: Subject/Scope/What changed/Impact/Risk/Rollback/Verification per commit. Full-history traversal (oldest→newest) with merge filtering and PyDriller-safe ingest. Robust LLM layer: model auto-pick, retry/backoff for 429s, stable prompts. Clean UX in Streamlit with instant artifact viewing and Mermaid architecture. Reliable exports: docs.zip always; optional single-file PDF report when available. Windows-friendly paths, explicit 127.0.0.1, safe file/encoding handling. Modular core (parse/summarize/diagram/writer) for easy extension to new languages. Measurable quality bump: fewer hallucinations, more actionable, audit-ready docs.
What we learned
We learned a lot at this hackathon. We were all new to hackathons and its structure. With the project itself we learned how to link different cross functional codes together. Furthermore we learned how to use different web server such as uvicorn and streamlit.
What's next for RepoDigest - Enhanced Repository Analyzer
Team comms ingestion: Securely connect Slack, Teams, and other channels to capture design decisions and context—respecting workspace permissions and retention policies. RAG-powered Q&A: Add a retrieval-augmented layer over code, commits, docs, and team threads so users can ask natural-language questions and get grounded, source-linked answers. Multilingual experience: Provide full i18n/l10n (UI + model prompts + output) to support global teams, including glossary/term consistency across languages. Lastly, we could add other programming language support in later versions.



Log in or sign up for Devpost to join the conversation.