



Inspiration
Policy decisions move markets long before the real numbers show up. A Fed rate hike, a tariff announcement, or a minimum wage bill can affect people for months while politicians are still debating it.
We were inspired by Park et al. (Stanford, 2024), which showed that LLM agents grounded in real biographical data could predict human survey responses with 86% accuracy, beating demographic baselines by 12 points.
That made us ask a bigger question: if AI agents can simulate individual human behavior this well, what happens when you put a whole population of them inside a city and hit them with a policy change?
What it does
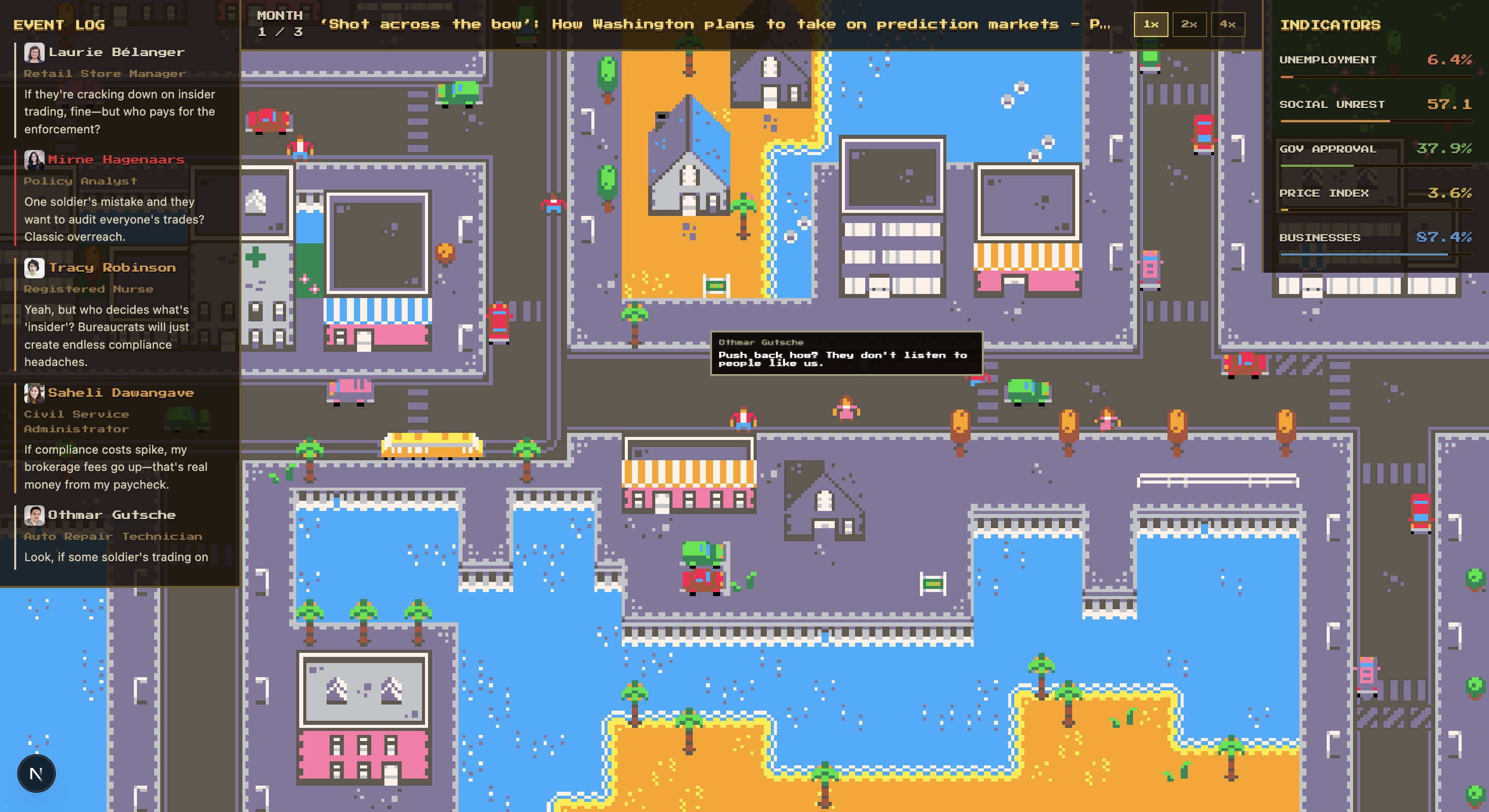
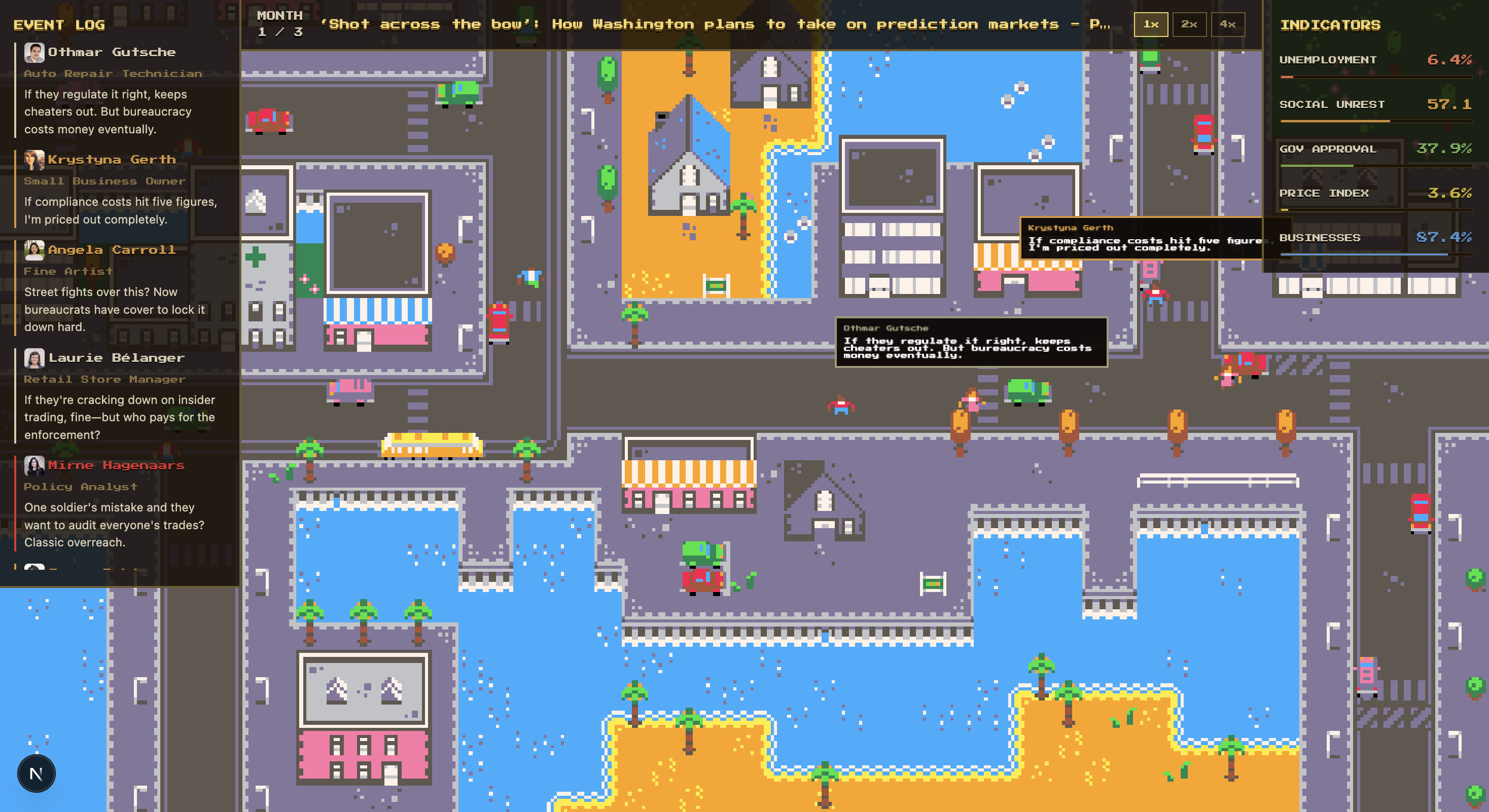
Feed Replicarria any real policy headline or PDF document.
N AI citizens, each with a real randomuser.me identity, a different economic role, and their own political leaning, react to that policy over simulated months while five economic indicators update in real time:
- Government approval
- Social unrest
- Unemployment
- Price index
- Business survival rate
Agents talk to each other, argue, and change their opinions through live LLM-generated conversations.
The biggest difference is cross-simulation memory.
You can run a tariff shock first, then run a healthcare bill on the same city. Because agents remember what happened before, their reaction to the healthcare bill changes based on the tariff experience, just like real economies where past events shape future decisions.
How we built it
Each agent runs a four-step LangGraph loop every simulated month:
- Retrieve
- Perceive
- Reflect
- Plan
Memory retrieval is scored using:
$$ \text{score} = 0.4 \cdot \text{recency} + 0.4 \cdot \text{importance} + 0.2 \cdot \text{keyword_relevance} $$
This helps agents pull the most relevant memories before forming an opinion.
When the total unreflected importance passes 25, the agent summarizes its last 15 memories into higher-level beliefs through a reflection node.
After each round, every pair of agents runs the Deffuant bounded confidence model:
$$ x_i \leftarrow x_i + \mu(x_j - x_i) \quad \text{if } |x_i - x_j| < \varepsilon $$
Where:
$$ \varepsilon = 0.45 $$
$$ \mu = 0.25 $$
If two agents are close enough ideologically, they move closer together. If they are too far apart, they ignore each other. This creates realistic political polarization without us manually forcing it.
When two NPCs get close to each other on the Phaser 3 city map, Claude Haiku generates a live 4-line conversation between them. That conversation updates both agents’ mood, stance, and memory, which directly affects the next simulation round.
We also wanted the personas to feel real.
randomuser.me handles identity like name, photo, nationality, and age, while the LLM only assigns occupation and political beliefs. This avoids the problem where fully AI-generated personas all start sounding the same.
We also created five weighted political archetypes with different voice styles so every simulation has real ideological variety.
The full stack uses:
- FastAPI
- Socket.IO
- LangGraph
- Next.js
- Claude Haiku 4.5
Challenges we ran into
At first, all N agents kept agreeing with each other, and somehow several of them were named Marcus.
The problem was that separate LLM calls with similar prompts kept producing the same default personalities.
We fixed this by separating identity generation from belief generation and adding hard political diversity constraints.
Another issue was our economic index formulas. They had hidden round-based drift, which meant every simulation slowly became worse no matter what the agents actually believed.
We rebuilt all five indices so they depend only on actual stance and mood distribution instead of artificial round progression.
Also, getting async agent orchestration, LangGraph checkpoints, and Socket.IO real-time streaming to work together inside FastAPI was honestly painful.
Accomplishments that we're proud of
Cross-simulation memory actually works.
Agents in their second simulation react faster, become more polarized, and reference previous events without us scripting any of it. The LangGraph memory system and Deffuant opinion model handle that naturally.
We also got real ideological disagreement.
A right-leaning small business owner and a left-leaning factory worker can react to the same tariff in completely opposite ways, talk to each other, influence each other a little, and still not fully agree. That is exactly the behavior we wanted.
What we learned
Grounding LLM agents in structured biographical data makes a huge difference compared to prompting from scratch. It creates much more believable behavior and matched the core finding from the Stanford paper.
We also learned that opinion dynamics models from computational social science work surprisingly well with LLM agents.
The same math used to describe how real political groups form also works when the people are AI agents.
What's next for Replicarria
- Validate Replicarria using real historical policy events and compare our predicted index changes to what actually happened
- Scale from few agents to 50-100+ agents using parallel processing for better population realism
- Build a version for think tanks, policy researchers, and central banks to test legislation before it passes
- Add sector-specific chain reactions where a tariff affects manufacturers first, then retailers, then service workers over time
Built With
- claude-haiku-4.5-(anthropic-api)
- fastapi
- langgraph
- newsapi
- next.js
- pdfplumber
- phaser-3
- python
- randomuser.me-api
- react
- socket.io
- typescript



Log in or sign up for Devpost to join the conversation.