-
-

A Replay of our time at the Bitcamp table!
-
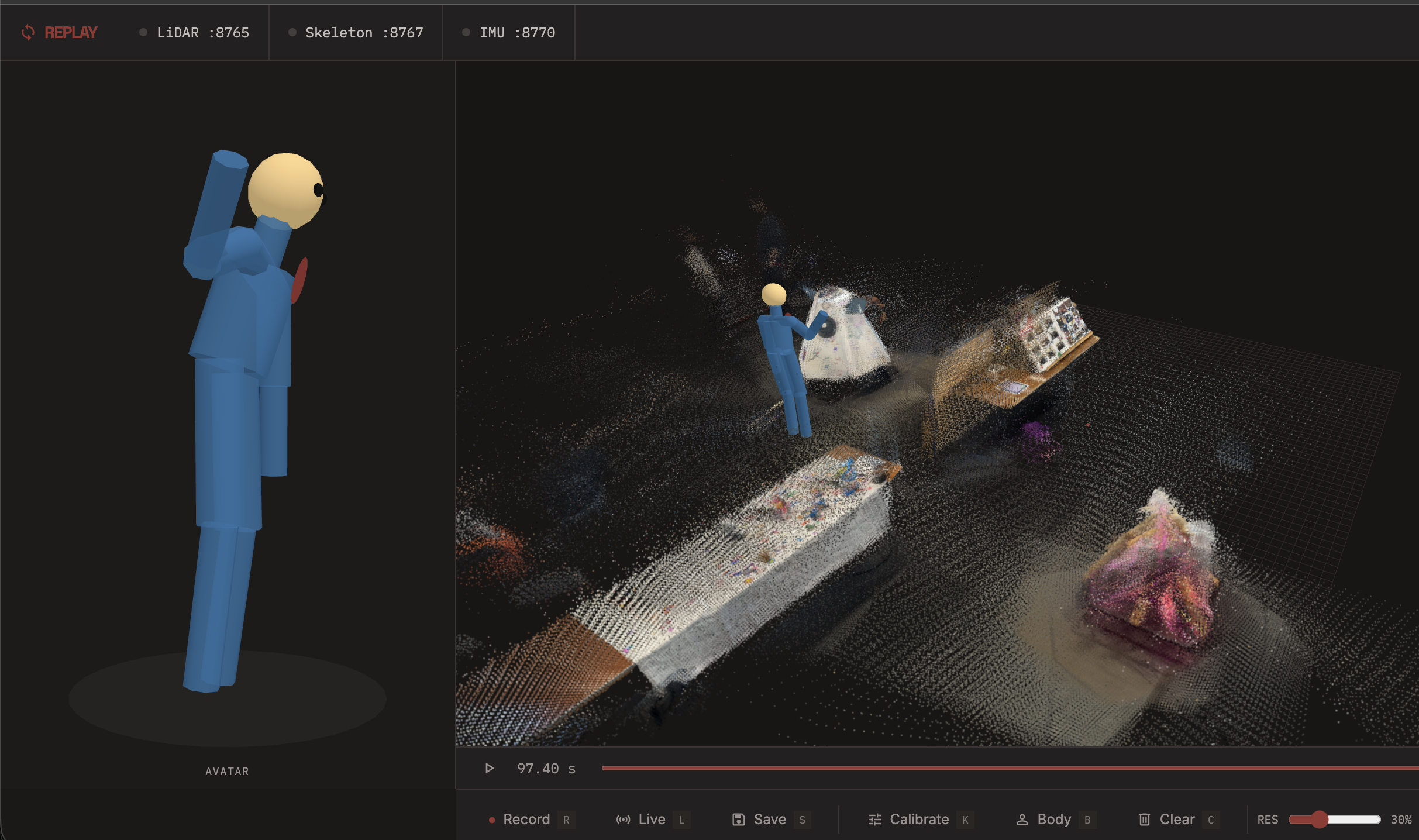
High fidelity view of the Bitcamp center stage
-
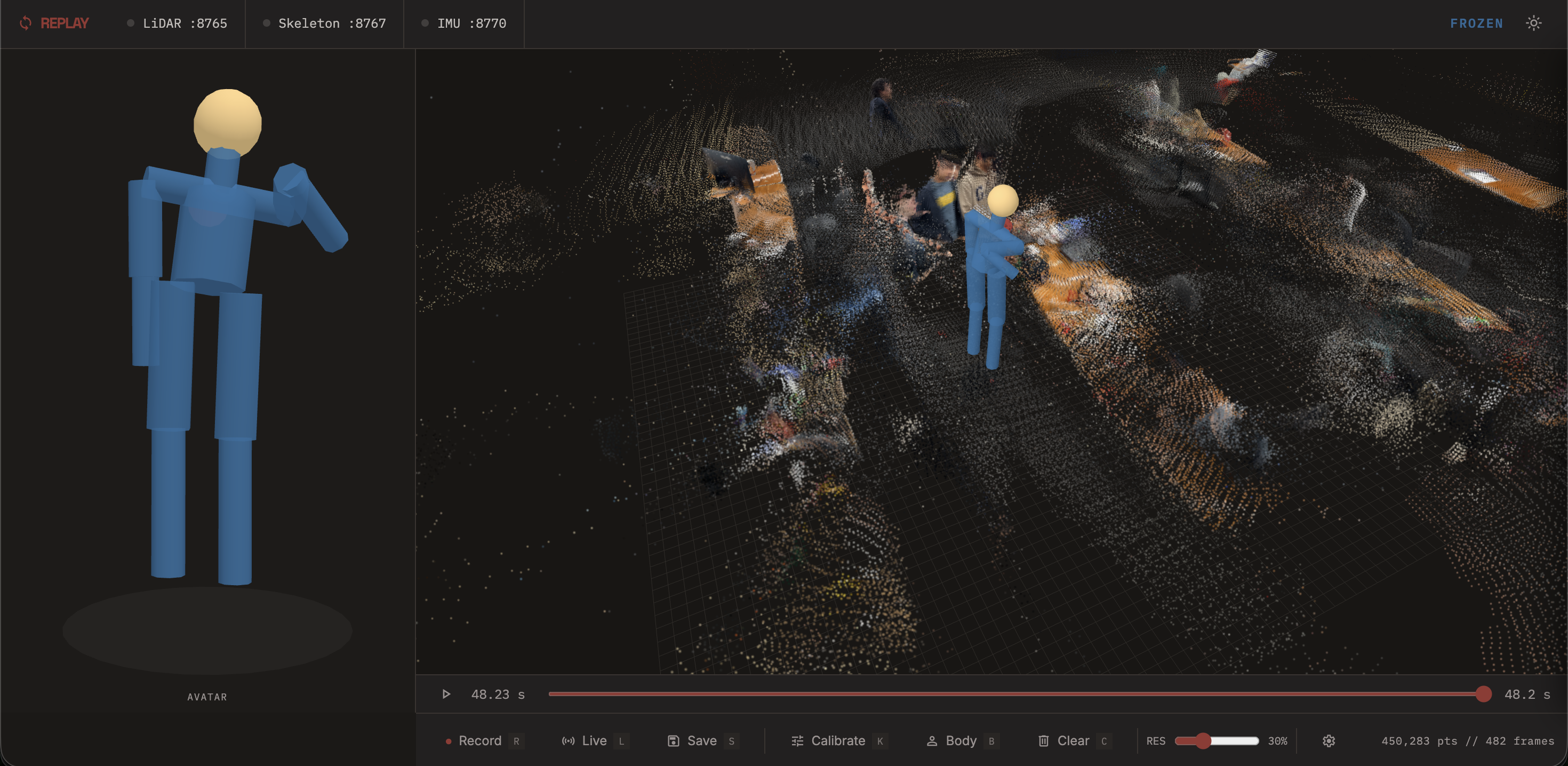
3D scene with point cloud example
-
Replay home screen
-
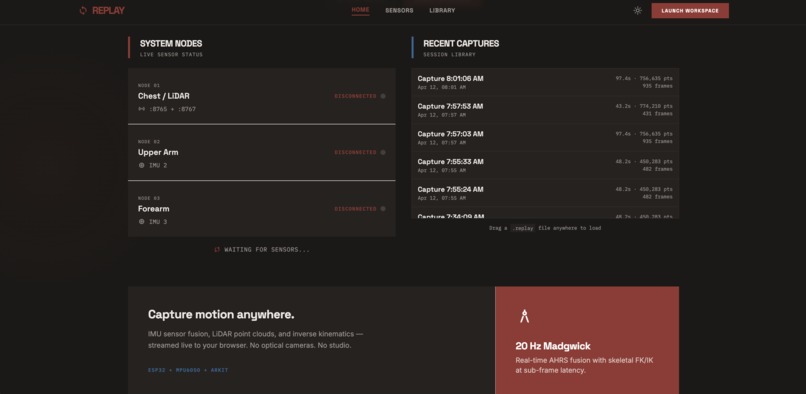
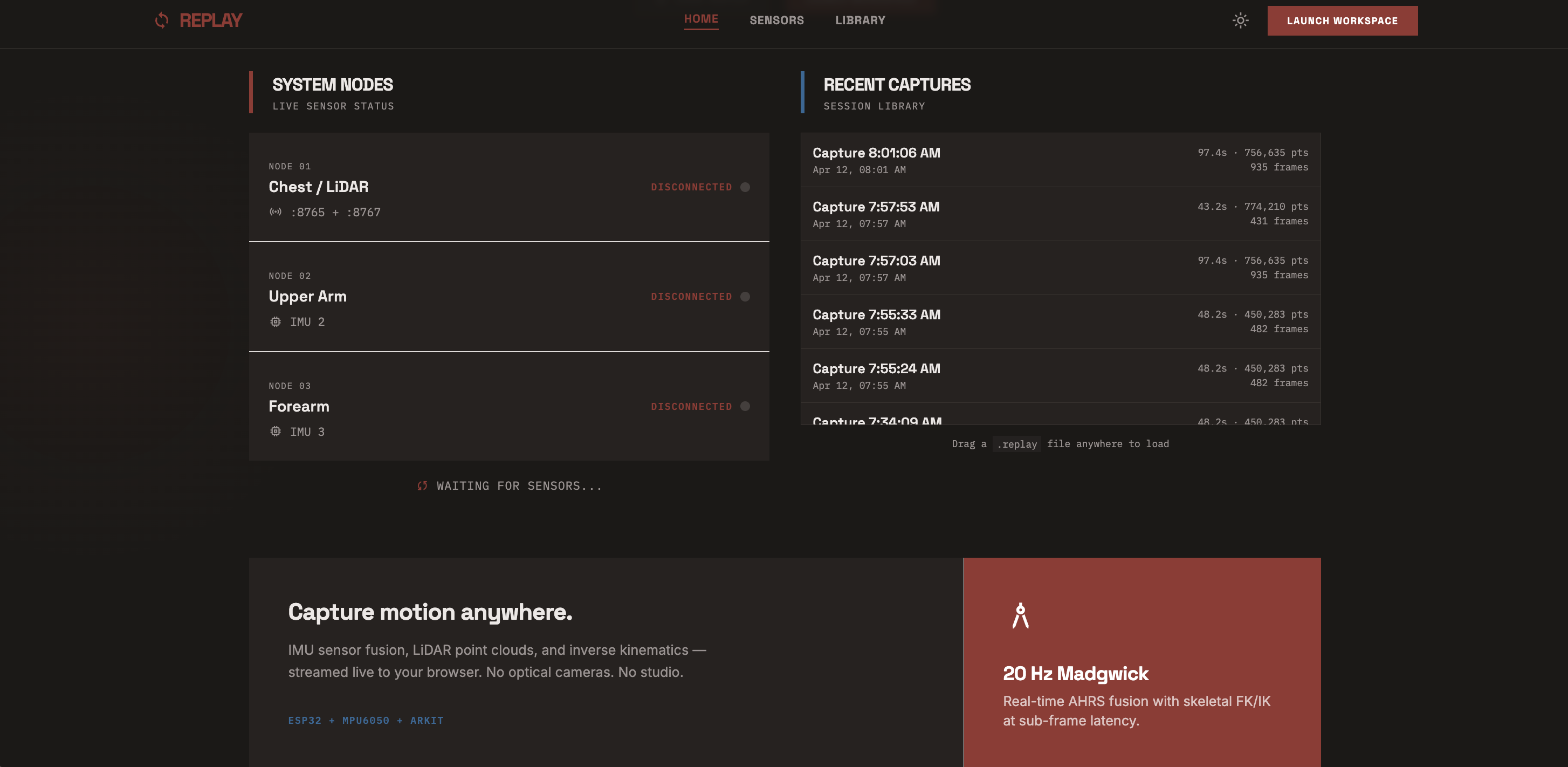
Replay dashboard
-

Replay Workspace + debug views

Inspiration
Everyone who's played Minecraft knows Replay Mod — you record a session, then scrub through time and fly a free camera around the 3D world to relive it from any angle. We asked: what if we could do that with real life? Record a physical space and the people moving through it, then replay the moment in an interactive 3D viewer where you can pause, rewind, and orbit freely. No volumetric video studio, no professional mocap suit — just an iPhone, two ESP32s, and a laptop.
What It Does
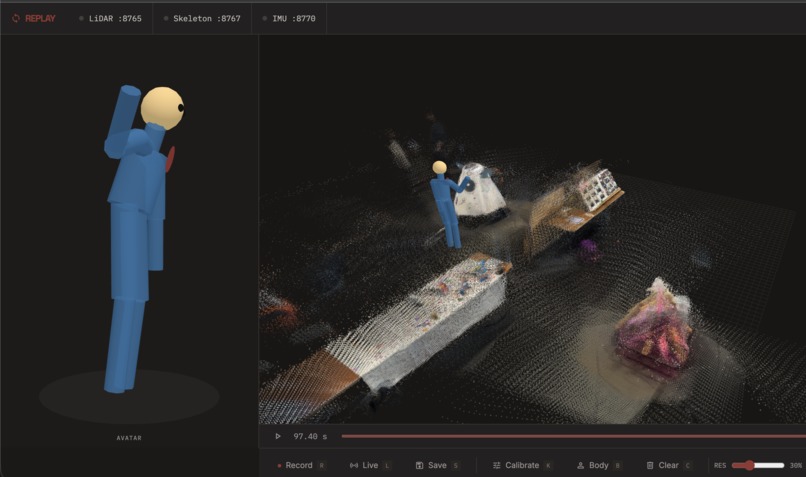
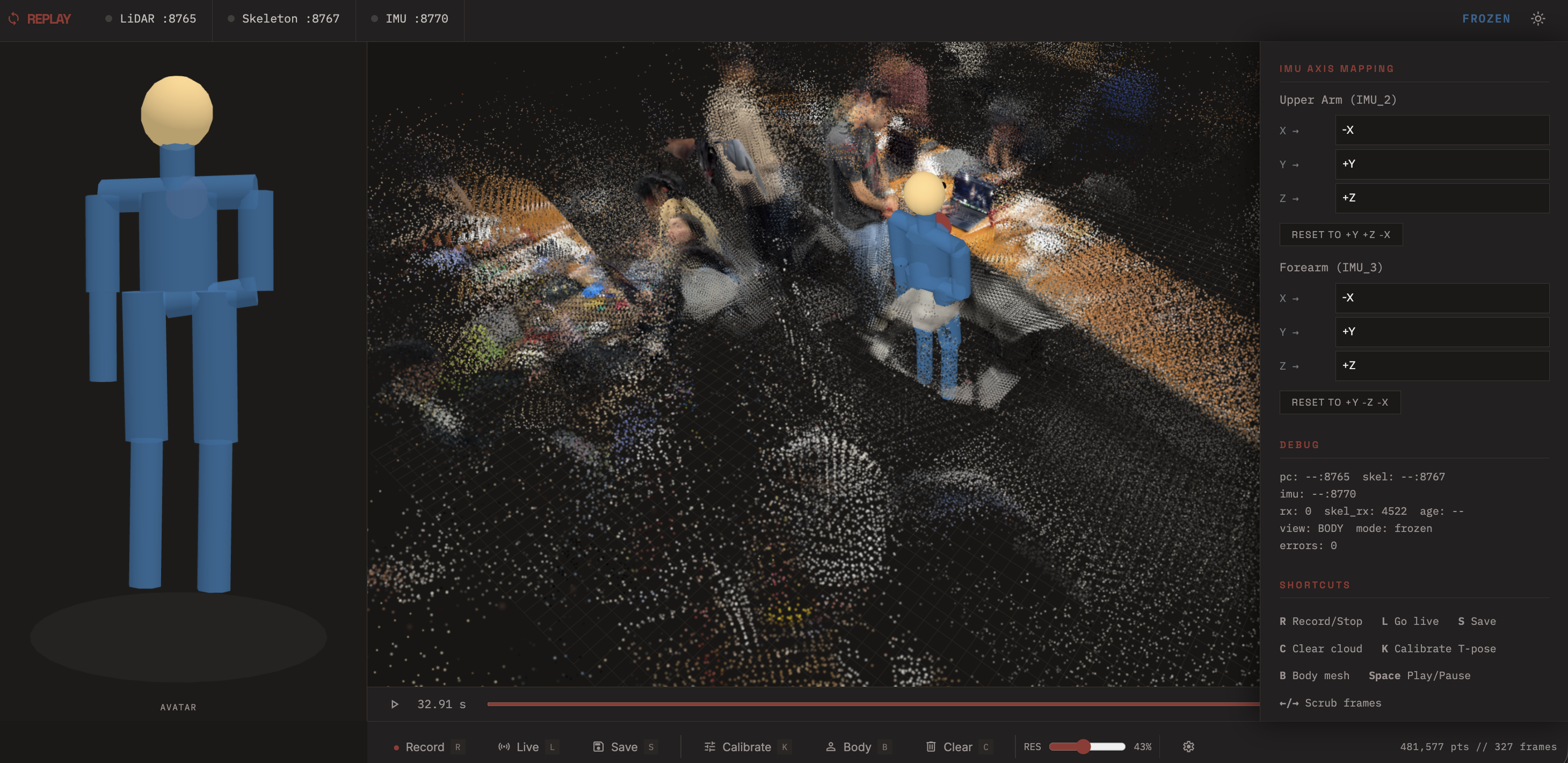
Replay captures a real-world 3D environment and human body motion in real time, then lets you replay it as an interactive 3D scene.
An iPhone 13 Pro with LiDAR streams an ARKit point cloud of the surroundings, tracks its own position via VIO/SLAM, and provides chest IMU quaternions. Two ESP32 + MPU6050 boards, strapped to the upper arm and forearm, stream orientation data to capture dominant arm pose. All of this fuses together on a Mac, which runs Madgwick filtering, forward kinematics, and predictive physics modeling to produce a live 3D skeleton overlaid on the accumulated point cloud.
The key: forward kinematics deterministically constructs the torso and dominant arm from direct sensor data, while predictive ragdoll physics and inverse kinematics infer the remaining limbs (off-arm and legs) with high general accuracy and realism. Three sensors reconstruct an entire body.
The Three.js frontend renders everything in real time — and sessions can be recorded, saved as .replay files, and played back frame-by-frame with full camera freedom.
How We Built It
Capture hardware: An iPhone 13 Pro runs a custom Swift/ARKit app that streams LiDAR point cloud frames, VIO/SLAM world position, and IMU quaternions over WebSocket via USB tether. Two ESP32 + MPU6050 boards read raw accelerometer/gyroscope data and fire bit-packed UDP packets at ~20 Hz — the ESP loops were designed to be as fast as possible to maximize precision and minimize IMU drift.
Networking: One ESP32 acts as the WiFi access point. Everything else — the second ESP, the Mac, the iPhone — connects through it. The hackathon's WiFi network didn't allow easy peer-to-peer connections, so we had to stand up our own network and manually configure hostnames, IPs, and connection protocols across LAN WiFi, WebSockets, TCP, UDP, and earlier BLE attempts with Arduino 101s before landing on the final architecture.
Sensor fusion & kinematics (Mac): Terminal 1 runs the IMU fusion server — ingesting raw ESP32 UDP packets, running Madgwick filtering to produce clean quaternions, and building the skeleton via forward kinematics. Terminal 2 takes that skeleton data and combines it with iPhone VIO to position the body correctly in 3D space within the point cloud. Predictive physics modeling (ragdoll assumptions) and inverse kinematics infer the non-instrumented limbs. VIO and accelerometer data are cross-referenced to compensate for and correct sensor drift.
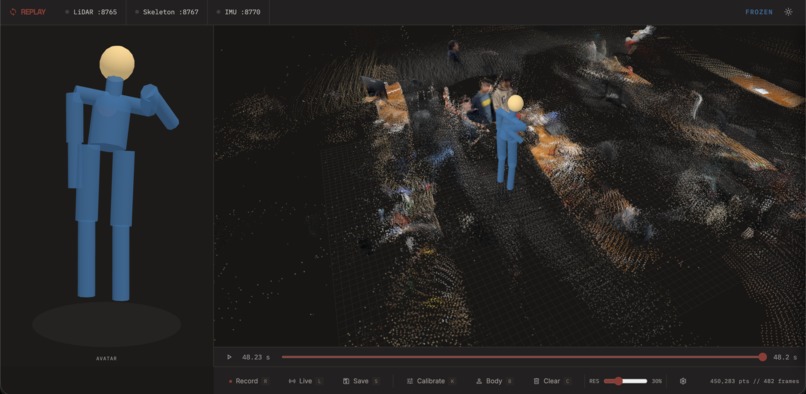
Frontend (Three.js): A browser-based 3D viewer renders the accumulated point cloud, skeleton, and body mesh. We deliberately avoided Gaussian splatting — it requires extra training, processing time, and isn't truly real-time — and instead used a custom Three.js shader to add realism to the raw point cloud. The result preserves remarkable detail: clear environmental features, distinct objects, and even legible printed text from the scan. The viewer supports live mode, recording, frame-by-frame playback with a timeline scrubber, free camera orbit, T-pose calibration, and save/load of .replay session files.
Challenges We Ran Into
Synchronizing and orienting independent data streams was the hardest problem — especially relating the ESP32 IMU data to the iPhone's VIO coordinate frame. Each device has its own clock and its own spatial reference. Getting them to agree on where the body is in the point cloud required careful timestamp interpolation and coordinate alignment.
Reducing sensor drift was a constant battle. IMU sensors accumulate error over time, and at 20 Hz over WiFi with packet loss, small errors compound fast. We used VIO position data and accelerometer readings to compensate and correct, cross-referencing multiple data sources to keep the skeleton stable.
Networking all the devices together was a huge pain. We went through LAN WiFi, WebSockets, TCP, UDP, and earlier BLE attempts with Arduino 101s before landing on the final architecture. The hackathon WiFi didn't support easy P2P connections, so we had to set up our own network through the ESP32 access point and manually configure every hostname, IP, and connection protocol to make everything work.
Accomplishments We're Proud Of
The fidelity-to-sensor ratio. A phone and two small sensor modules give us a full 3D scene and a high-accuracy skeletal render capturing a user's movements and interactions — with predictive physics filling in the limbs we aren't directly measuring. No depth camera array, no optical markers, no cloud compute.
The fact that the entire pipeline works end-to-end, built from scratch in 36 hours: custom ESP32 firmware, a custom iPhone ARKit app, Madgwick filtering, forward kinematics with swing-twist decomposition, inverse kinematics, ragdoll physics inference, real-time multi-device networking, and an interactive Three.js viewer with recording and playback. No pre-built mocap libraries, no cloud APIs, no ML models.
The visual fidelity and clarity of the point cloud. We're proud of the detail we're able to capture through raw point cloud renders with our custom shader — you can make out clear features, environmental objects, and even printed text in the scans. Avoiding Gaussian splatting kept everything real-time while still looking great.
What We Learned
Quaternion math is humbling. We went from "how hard can rotation be" to implementing swing-twist decomposition and Madgwick filters from papers. The gap between understanding rotation conceptually and making three independent sensor streams produce a coherent human skeleton is enormous.
We also learned a lot about real-time distributed systems — coordinating six networked services across multiple physical devices with different protocols forces you to think about latency, synchronization, and graceful degradation when packets get lost.
What's Next for Replay
Adding more IMU nodes for full-body tracking while maintaining our sensor-to-output ratio. Using optimized pretrained Gaussian splats running on Metal shaders for photorealistic scene reconstruction without significant additional time overhead. And multi-person capture.
Beyond the core platform, we're excited by how broadly the system generalizes. The same capture-and-replay pipeline could enable remote movement monitoring for elderly patients — a caregiver could scrub through a replay to diagnose a fall or gait change after the fact. It could log construction site walkthroughs as explorable 3D records. Athletes could review training sessions from any angle. And on the personal side, it's a fundamentally new way to save and revisit memories — not as a flat photo or video, but as a full 4D moment (3D + time) you can step back into and explore freely!











Log in or sign up for Devpost to join the conversation.