-
-
Reputation badges are displayed in the timeline.
-
Reputation cards are displayed on profiles.
-
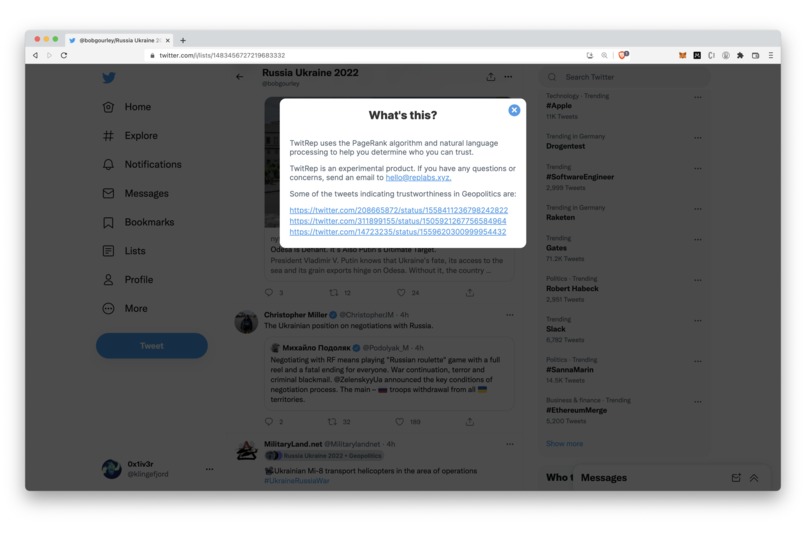
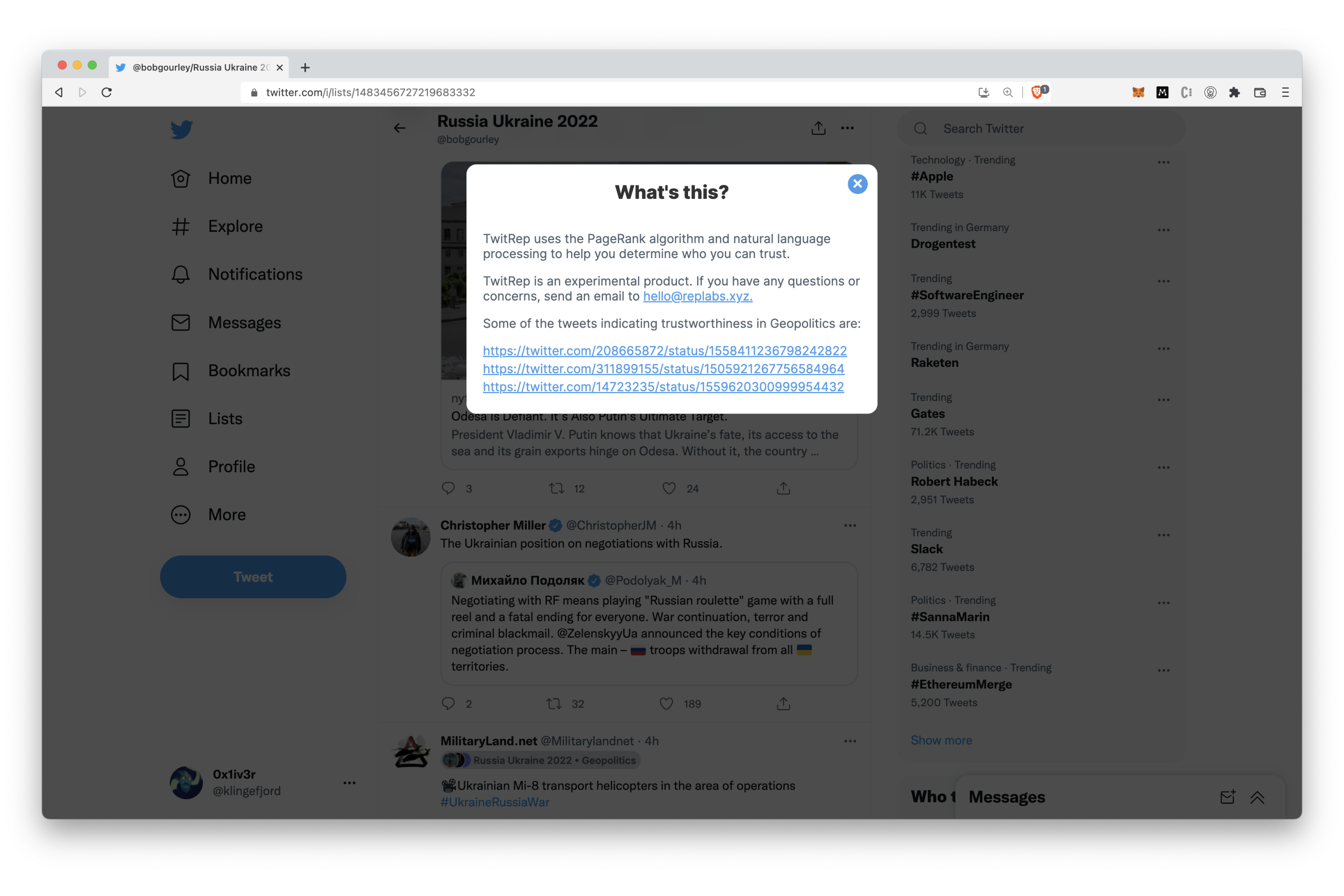
Information about the reputation calculation.

Inspiration
With the internet, and on Twitter especially, everyone is a producer. The amount of content we are interacting with is exploding. At the same time, old gatekeeping institutions, like universities, are not trusted to the same extent, which leads to a void of legitimacy that needs to be filled. How do we know who and what to trust in the ocean of information we're drowning in?
With this framing, I'm interested in exploring reputation systems that help us determine who we can trust in a certain context without relying on centralized judgement. Twitter is a perfect place to experiment with this due to the rich conversations that are had on the platform and the amount of text data that is available.
The TwitRep Chrome Extension is an experiment in multi-dimensional reputation systems – meaning, a reputation system that models reputation as vectors instead of scalars. Any universal reputation score inevitably become a social credit score, unless properly contextualized. With language models, we're able to move away from such uni-dimensional scores.
What it does
TwitRep displays reputation badges and cards on Twitter profiles and timelines in the browser through a Chrome Extension. These cards and badges help users determine who is trustworthy for what in which context.
In the background, reputation is calculated from historic tweets from lists that the user follows. These tweets are fed through an algorithm that combines PageRank and state-of-the-art language models.
How we built it
The core idea of TwitRep is to use conversations as assessments. A user replying positively to someone's tweet or tweet thread can be seen as a positive assessment of the other user's trustworthiness in that area. Using this assumption, TwitRep models reply tweets within the context of a list into a directed graph, where the nodes are users and edges are conversations.
When a user wants to know about a certain type of reputation (for instance: "Vaccines"), within the scope of a list, the graph for that list is weighted by comparing the embedding of the query ("Vaccines") against the embeddings of the tweets the reply tweets are replying to, and the sentiment of the replies themselves. After that, PageRank is run on this directed graph and the scores are sent to the front-end.
In the front-end, a badge is shown on reputable users next to their tweets and a card on their profile. This reputation signal can be used, in addition to the profile's bio, verification badge and follower statistics, to help determine if the account is trustworthy or not.
The Chrome Extension is built using TypeScript. It communicates with a Flask backend that houses the embedding and sentiment classifier language models.
A firebase function continuously downloads tweets for registered lists into a Firestore database. These tweets are then fed through the embedding and sentiment models, and once done, the lists are cached as graphs on the Flask server for quick inference.
When a user navigates to a twitter list or profile, results are fetched from the Flask server and cached in the chrome extension. These results are then used to inject badges and cards into the twitter UI.
Challenges we ran into
Oauth authorization is not straight-forward in chrome extensions due to the new rules introduced with Manifest Version 3, preventing developers from loading external code such as the Firebase package.
Fetching large amounts of tweets and feeding them through big machine learning models takes time. This is why I ended up moving the logic for fetching tweets to a background firebase function, and batch embedding calculations and firebase updates whenever possible.
The machine learning models proved too large to be included in the backend Docker file, so I had to move them into separate servers living on separate Docker containers.
Accomplishments that we're proud of
I am proud over the accuracy of the results, and have found TwitRep to be useful for myself in order to better assess the trustworthiness of accounts tweeting about the war in Ukraine.
What we learned
The algorithm produced valuable results despite the relative simplicity of the algorithm. This is encouraging, and even though there is a lot more work to do research-wise, I'm glad to see some validation already.
However, getting really good results requires fetching a lot of historic tweets, making it unfeasible to release TwitRep broadly with the projects current tweet cap.
What's next for Replabs
TwitRep is experimental and more research into algorithms is needed before wide adoption. I'm going to write a paper about the algorithm at RWOT (https://www.weboftrust.info/) and will continue researching and investigating language model-based reputation systems for social media. I would love to work closer with Twitter as our missions overlap. If this is something that you would be interested in pursuing you can reach me at oliverklingefjord@gmail.com.


Log in or sign up for Devpost to join the conversation.