
Inspiration
RentControl started from a specific technical and social gap: in New York City, the data renters need to protect themselves already exists, but it is fragmented across public systems that are difficult to query, normalize, and interpret in real time.
Landlords increasingly have access to pricing software, internal market intelligence, and better operational data. Renters, by contrast, are often left with scattered public records from multiple New York City datasets, including building-level information, housing violations, complaint histories, registration records, and lease documents that are long, dense, and difficult to review under time pressure. The raw information exists, but the interface to it effectively does not.
That was the motivation for RentControl. We wanted to build an agentic system that could take a renter’s input, an address and optionally a lease PDF, resolve the relevant public records, compute grounded risk signals, use AI to interpret unstructured lease text, and then convert those findings into an action the renter could immediately use.
Instead of making another chatbot, we wanted to build an end-to-end renter intelligence pipeline: one that starts with public housing data and ends with a consent-based action on the user’s behalf.
What it does
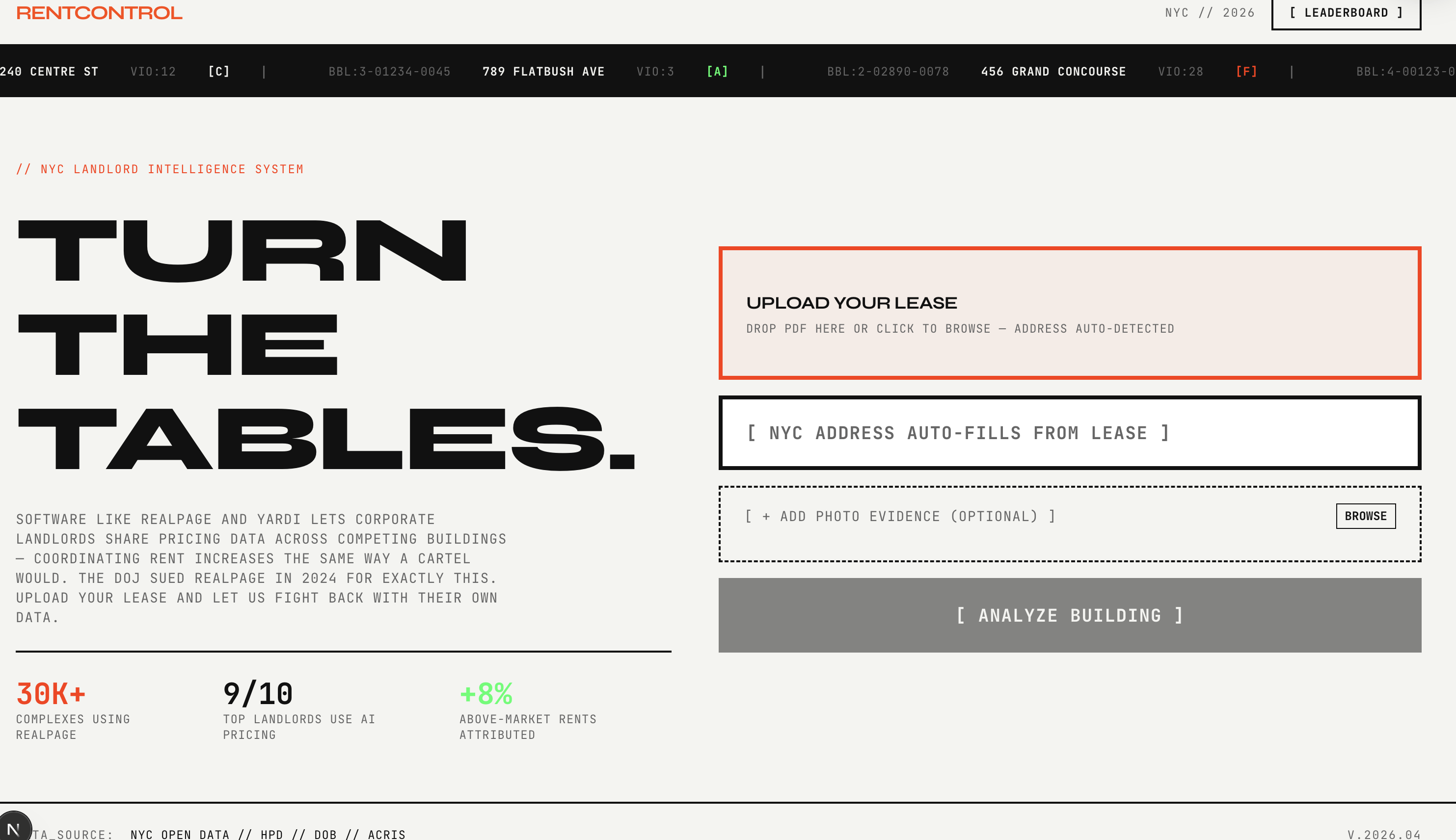
RentControl is an AI agent for NYC renters that investigates a property before the renter signs and can automatically contact the landlord once the renter approves the action.
The user enters an address and can optionally upload a lease PDF. From that point, the system runs a multi-stage pipeline:
- normalizes the address and resolves it to a BBL using NYC Planning Labs GeoSearch
- pulls building-level data from PLUTO
- queries HPD violations
- queries DOB complaints
- resolves landlord and ownership information from HPD registration and contact data
- analyzes the lease using AI
- synthesizes all structured and unstructured outputs into a renter-facing report
- automatically drafts and sends a personalized landlord email with the renter’s consent
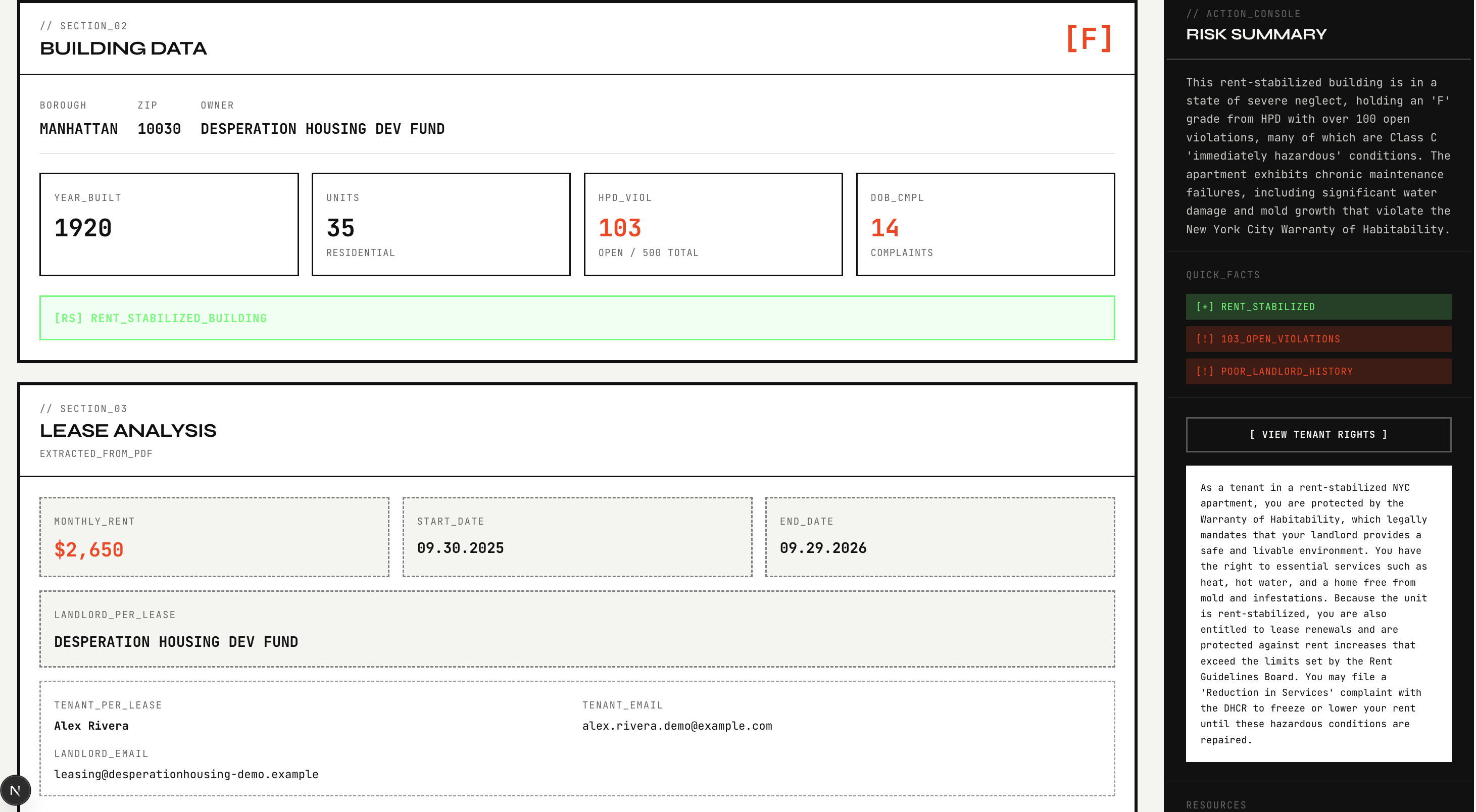
The final report includes:
- a building score and grade
- violation and complaint context
- landlord portfolio signals
- extracted lease terms such as rent, dates, and names
- lease red flags and potentially concerning clauses
- tenant-rights guidance
- an automatically generated landlord email grounded in the facts the system found
A key design decision was that RentControl does not let the language model invent the risk profile of a building or landlord. Those scores come from deterministic logic over public data. The model is used for lease extraction, synthesis, explanation, automatic email generation, and agentic action.
How we built it
We built RentControl as a full-stack application with a Next.js frontend and a FastAPI backend, with persistence handled through SQLite by default.
Frontend
The frontend is built in Next.js App Router and is responsible for the renter-facing workflow. We designed the interface around a simple input-to-report flow:
- home page for address entry and optional lease upload
- visible analysis pipeline so the user can see what the system is doing
- report page that displays building, landlord, and lease cards
- AI-generated narrative sections for summary, red flags, tenant rights, and email output
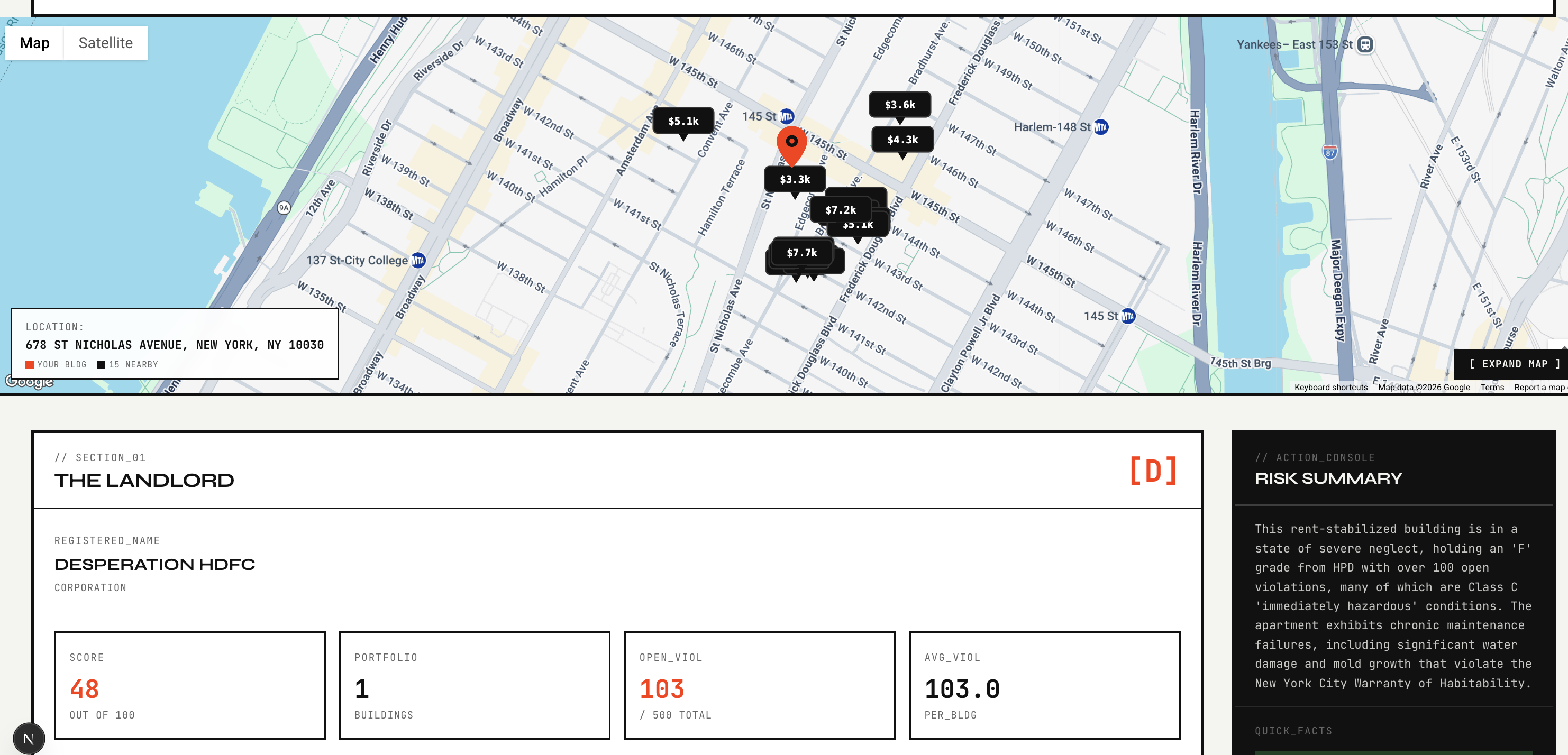
- map view for the target building, nearby comparables, and landlord portfolio pins
The frontend also contains typed client-side models and an API wrapper so the UI can consistently consume structured backend responses.
Backend architecture
The backend is built in FastAPI with SQLAlchemy, httpx, and pypdf.
At a high level, the backend is organized around a sequence of API routes:
POST /api/buildingPOST /api/landlordPOST /api/leasePOST /api/analyzeGET /api/report/{id}- supporting endpoints such as nearby building comparisons and leaderboard workflows
1. Address normalization and geospatial resolution
The first technical problem we had to solve was reliable address resolution. User-provided addresses are often noisy, especially when they include apartment or unit strings. We strip unit-level tokens, normalize the address, and send it through NYC Planning Labs GeoSearch to retrieve coordinates and the associated BBL.
The BBL becomes the stable identifier for the rest of the data pipeline.
2. Building data aggregation
Once we have the BBL, we query PLUTO and other city datasets to build a structured building profile. PLUTO provides fields such as:
- tax-lot-level ownership name
- year built
- unit counts
- building class and related characteristics
We then augment that with:
- HPD violations
- DOB complaints
DOB complaint matching required more care because those records are often joined through address components such as house number and street name rather than a direct BBL lookup. That meant we had to reconcile the user input with PLUTO-derived addressing to get more reliable matches.
3. Deterministic scoring
One of the strongest technical choices in the project was separating risk computation from language generation.
Building and landlord scores are computed through deterministic formulas in scoring.py, rather than through model-generated judgment. For example, building-level risk incorporates features such as:
- violations per unit
- severity-weighted violation classes
- complaint volume
- resolution ratio
Landlord-level scoring focuses on open violations across the resolved portfolio and related normalized building counts.
This mattered for trust. We wanted the model to explain and act on the facts, not fabricate them.
4. Landlord resolution and portfolio analysis
Landlord analysis was one of the hardest backend pieces because ownership is not always represented cleanly across datasets.
We use HPD registration and contact data to resolve a landlord or owner identity. If the owner appears to be a corporation, the backend attempts to identify additional BBLs associated with that same owner, up to a capped portfolio size for performance and relevance. We then aggregate cross-building violation signals and compute a landlord score over that broader footprint.
We also resolve latitude and longitude for portfolio properties through PLUTO so the frontend can visualize landlord-related buildings on the map.
5. Lease analysis pipeline
If the renter uploads a lease, the file is sent to POST /api/lease.
We support a provider fallback stack:
- Featherless API using Gemma when
FEATHERLESS_API_KEYis configured - Gemini when available
- regex and rule-based extraction as a fallback
We use pypdf for text extraction when needed, then pass lease content into the model with a structured prompt to extract:
- rent
- lease dates
- landlord name
- key clauses
- red flags
- other notable terms
This allowed us to use AI where it is strongest, handling semi-structured and unstructured text, while still falling back gracefully if a model provider is unavailable.
6. Analysis and synthesis
After the structured building and landlord JSON and the lease terms are assembled, we call POST /api/analyze.
This stage again uses a provider hierarchy:
- Featherless / Gemma
- Gemini
- rule-based fallback generation
The analysis prompt is explicitly grounded in the structured objects we pass in. The model is instructed to produce:
- a summary
- red flags
- a tenant-rights paragraph
- a negotiation or inquiry email
We deliberately constrained the model to work from supplied facts so the output would remain anchored to actual housing data and extracted lease terms.
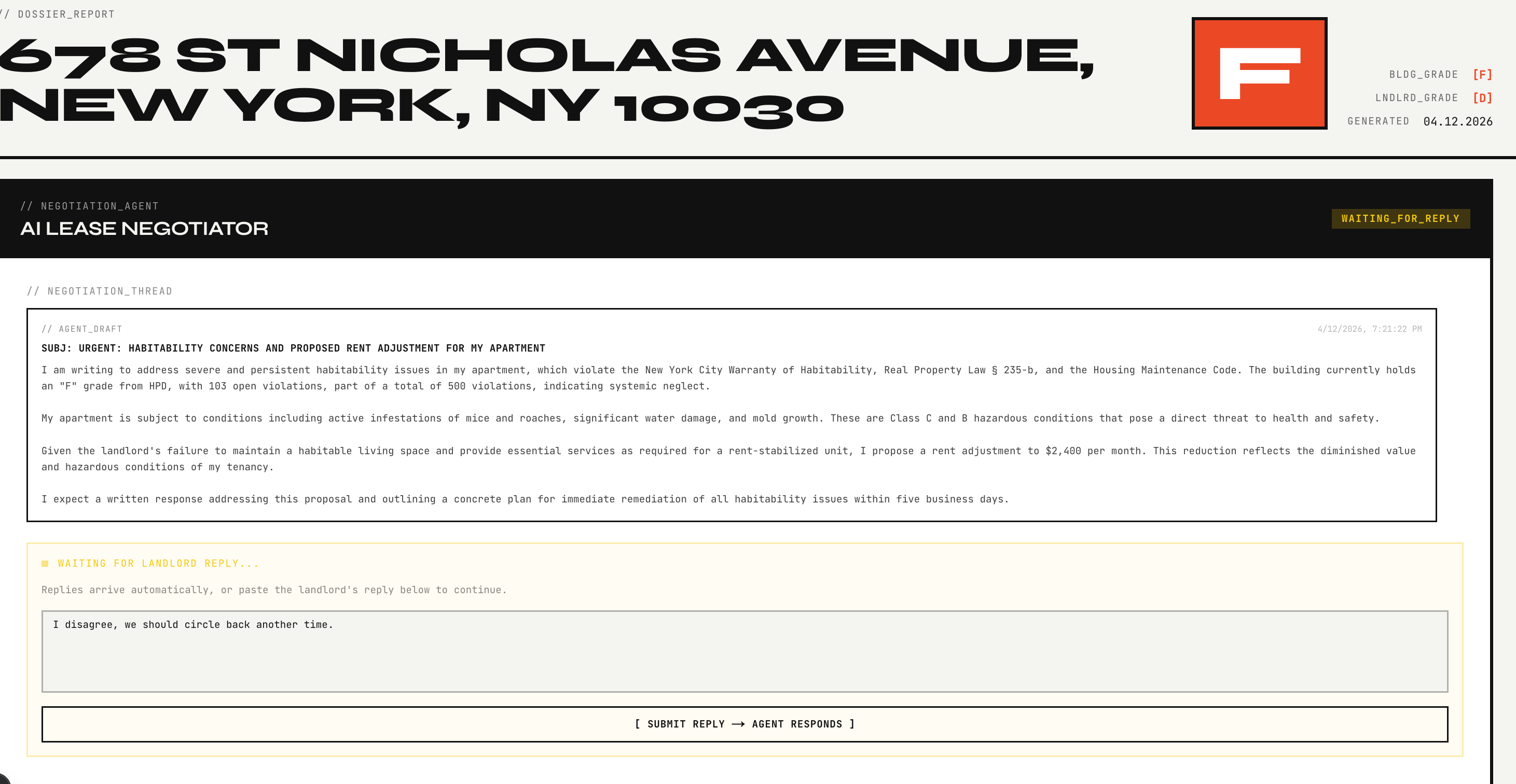
7. Agentic email action and automatic outreach
The last step is what makes RentControl agentic rather than just informative.
Instead of stopping at “here is a report,” the system automatically generates a targeted landlord email from the findings and sends it once the renter gives approval. That means the report is not the terminal output. It is an intermediate artifact that drives a real-world action.
This was a core design goal for the project. We did not want the model to behave like a passive assistant that only summarizes information. We wanted an agent that could investigate the rental, reason over structured and unstructured evidence, produce the right communication for the situation, and then complete that step on the user’s behalf with consent.
That action loop is central to the project. The app investigates, explains, and then acts.
8. Persistence and caching
We use SQLite-backed persistence for several reasons: fast local development, reproducibility during the hackathon, and the ability to cache repeated lookups.
We store data in tables such as:
cached_buildingscached_landlordsreports
cached_buildings stores one row per BBL with serialized building-derived outputs and sample violation data. cached_landlords stores landlord or portfolio-level aggregates, optional verdict text, and seeded metadata for ranking workflows. reports stores a snapshot of the building, landlord, and lease objects along with generated outputs such as summary, red flags, tenant-rights text, and negotiation email content.
This let us avoid redundant upstream fetches and made repeated demos much faster and more stable.
Model and platform choices
We considered the broader Google ecosystem and the spirit of the Agentic AI track. While the hackathon encouraged tools such as Vertex AI Agent Builder, our implementation centered on a custom FastAPI orchestration layer because we needed tight control over the public-data ingestion pipeline, fallback logic, deterministic scoring, and report persistence.
That choice gave us finer control over:
- address normalization
- multi-source public data joins
- custom scoring logic
- provider fallback between Featherless, Gemini, and rules
- explicit consent-based action flow
In other words, we chose direct orchestration over a more abstract agent platform because our bottleneck was not generic tool use, it was trustworthy data plumbing.
Challenges we ran into
1. Public data integration is messy
The biggest technical challenge was not model prompting. It was data integration.
New York City housing data is spread across multiple systems with different conventions, different identifiers, and different assumptions about how a user will query them. Some records are naturally keyed by BBL. Others are easier to access by address. Some ownership information is represented as a tax-lot owner name, while other records rely on registration contacts. Complaint data and violation data are not always normalized in the same way.
That forced us to spend a large amount of time on:
- address cleaning
- identifier reconciliation
- owner-name normalization
- matching complaint records to the correct building
- deciding when to trust one dataset over another
2. Trust and grounding
A second major challenge was making the AI useful without making it unreliable.
In a domain like renting, a polished but inaccurate answer is dangerous. We could not let the LLM operate as the source of truth. That is why we split the system into two layers:
- deterministic computation for objective risk signals
- model-based interpretation for lease extraction, explanation, and communication
This architecture took more effort than simply asking an LLM to “evaluate this property,” but it produced a system we trusted much more.
3. Actionability
Another challenge was getting from information to action in a way that still felt safe and user-controlled.
It is easy to generate summaries. It is harder to generate landlord outreach that feels specific, useful, and grounded in the actual findings of the report. It is even harder to move from a drafted message to an automatic send flow without making the experience feel reckless. We had to think carefully about tone, prompt structure, user approval, and what information should be included before an email is sent. The workflow needed to feel genuinely agentic while still keeping the renter in control.
4. Performance and demo stability
Because this was built in a hackathon setting, performance and reliability mattered a lot. Pulling multiple upstream datasets, resolving ownership, analyzing a lease, and generating a report can become slow if every request is fully cold. Caching and persistence were essential for keeping the product responsive enough for repeated testing and demo use.
Accomplishments that we're proud of
We are proud that RentControl is not just a surface-level AI wrapper. It is a real pipeline that combines:
- geospatial address resolution
- public-data aggregation
- deterministic risk scoring
- lease extraction
- grounded report generation
- consent-based automatic email outreach
We are also proud of the architectural discipline behind the project. In many hackathon projects, the model becomes the center of everything. In RentControl, we were intentional about using AI only where it meaningfully improved the system. The result is a product that is both more credible and more useful.
Another accomplishment we are proud of is that the app feels coherent from the user’s perspective. A renter does not have to understand BBLs, HPD datasets, or ownership reconciliation logic. They just see one place to enter an address, one report that makes sense, and one action they can take.
Finally, we are proud that the project addresses a real imbalance. It gives renters access to structured information and automated support that more closely matches the kind of leverage landlords already have.
What we learned
We learned that the hardest part of building an AI product is often not the AI.
In this project, the most important work involved data modeling, identifier resolution, fallback logic, scoring design, and deciding what the language model should and should not be allowed to do. The model became much more useful once we surrounded it with structure.
We also learned that grounding beats fluency in high-stakes domains. A less flashy answer tied to real public records is more valuable than a highly polished answer that cannot be traced back to data.
We learned that agentic systems become compelling when they close the loop. The moment RentControl could move from “here is what we found” to “here is the email we will automatically send once you approve it,” the product became much more than a reporting dashboard.
And we learned that technical specificity matters for trust. Users do not need every implementation detail, but the product itself benefits when the system actually knows where its conclusions came from.
What's next for RentControl
The next step for RentControl is to deepen both the data layer and the action layer.
On the data side, we want to expand coverage and improve quality by:
- adding richer rent-stabilization signals
- improving ownership and entity resolution
- building stronger nearby comparable logic
- tracking longitudinal changes in violations and complaints
- surfacing clearer timelines for building risk
On the agent side, we want the product to move beyond one-shot email generation toward a more persistent renter workflow. That includes:
- follow-up email chains
- smarter landlord-response handling
- negotiation-aware message generation
- reminders and monitoring for building-level changes
- a more continuous renter advocacy experience
We are also interested in exploring a future version that integrates more deeply with hosted agent platforms such as Vertex AI Agent Builder where it makes sense, especially for orchestration around multi-step communication workflows. But the core principle will stay the same: public facts first, AI reasoning second, user consent always.
RentControl began as a way to make buried housing data usable. It is becoming a system that turns that data into leverage.
Built With
- fastapi
- featherless.ai
- gemini-api
- gemma
- google-cloud
- next.js
- nyc-open-data
- python
- tailwindcss
- typescript
- v0
- vertexai


Log in or sign up for Devpost to join the conversation.