-
-
UPLOAD PAGE
-
-
Inspiration
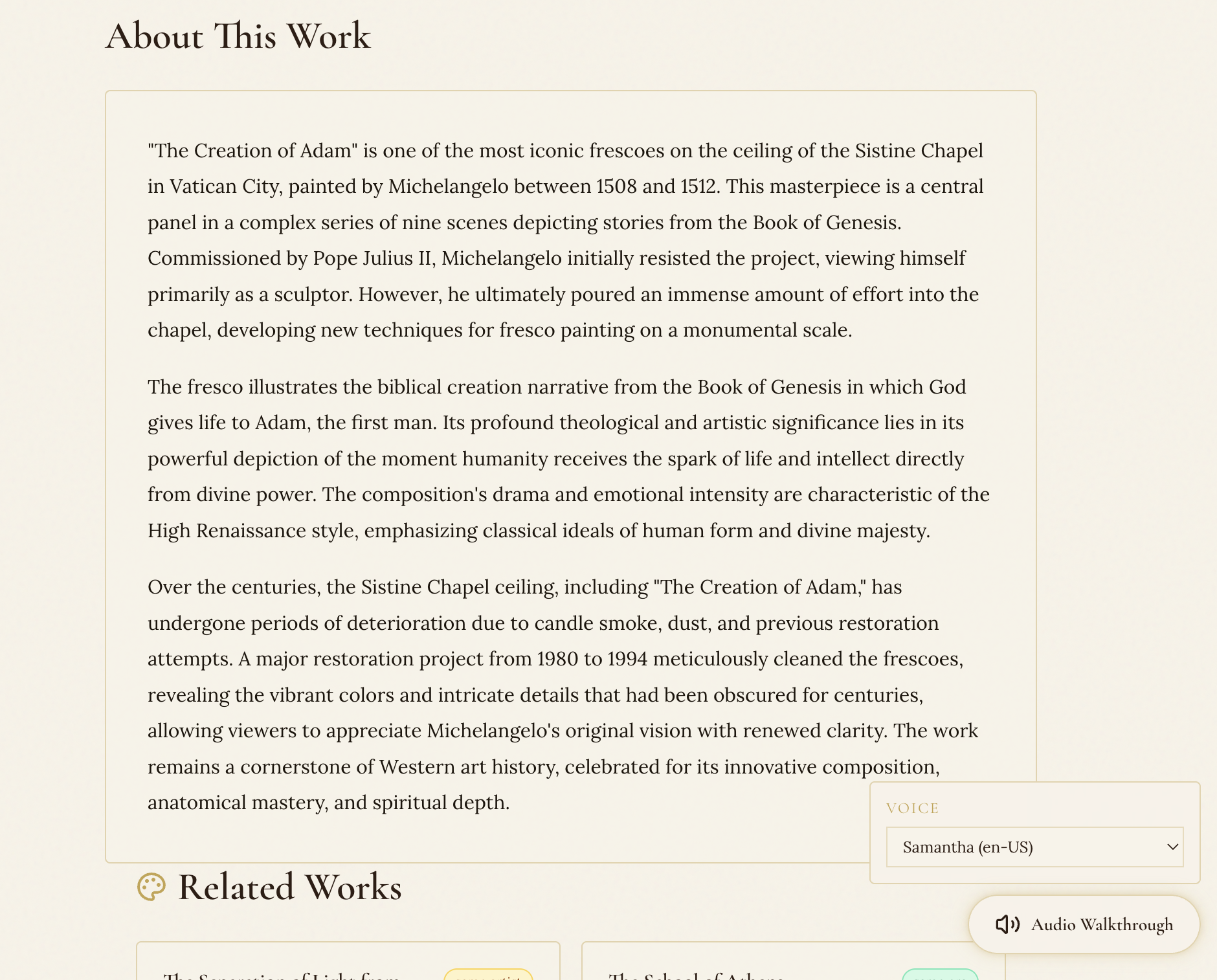
My friend is a Christian. He is very fascinated by Renaissance era paintings like The Last Supper, The Creation of Adam, and other masterworks — but he could never be satiated by his experience of analysing and understanding the pictures. Museum plaques give you a sentence or two. Wikipedia gives you dry facts. Neither lets you ask questions. So we created an agent that analyzes pictures and allows you to revisit the past through conversation with the AI and listen to all the fascinating stories behind every figure, every brushstroke, every hidden symbol.
What it does
Renaissance Revelations is an AI-powered painting analysis tool that brings classical art to life:
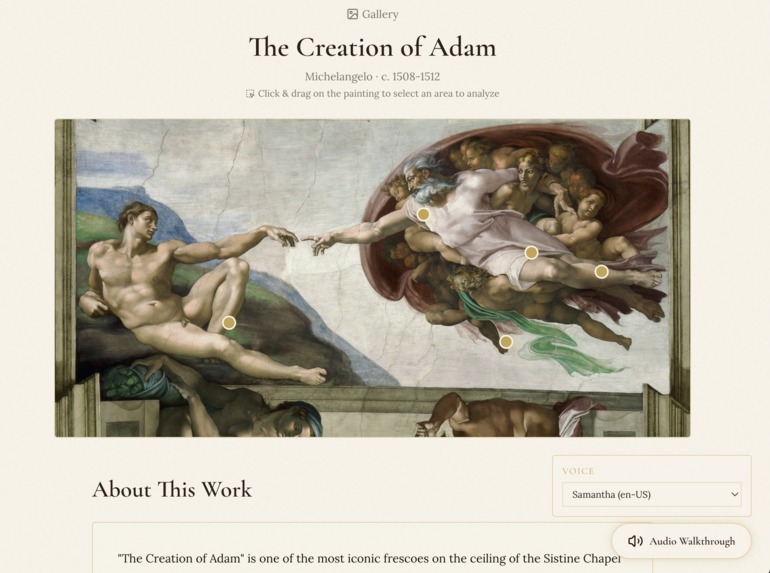
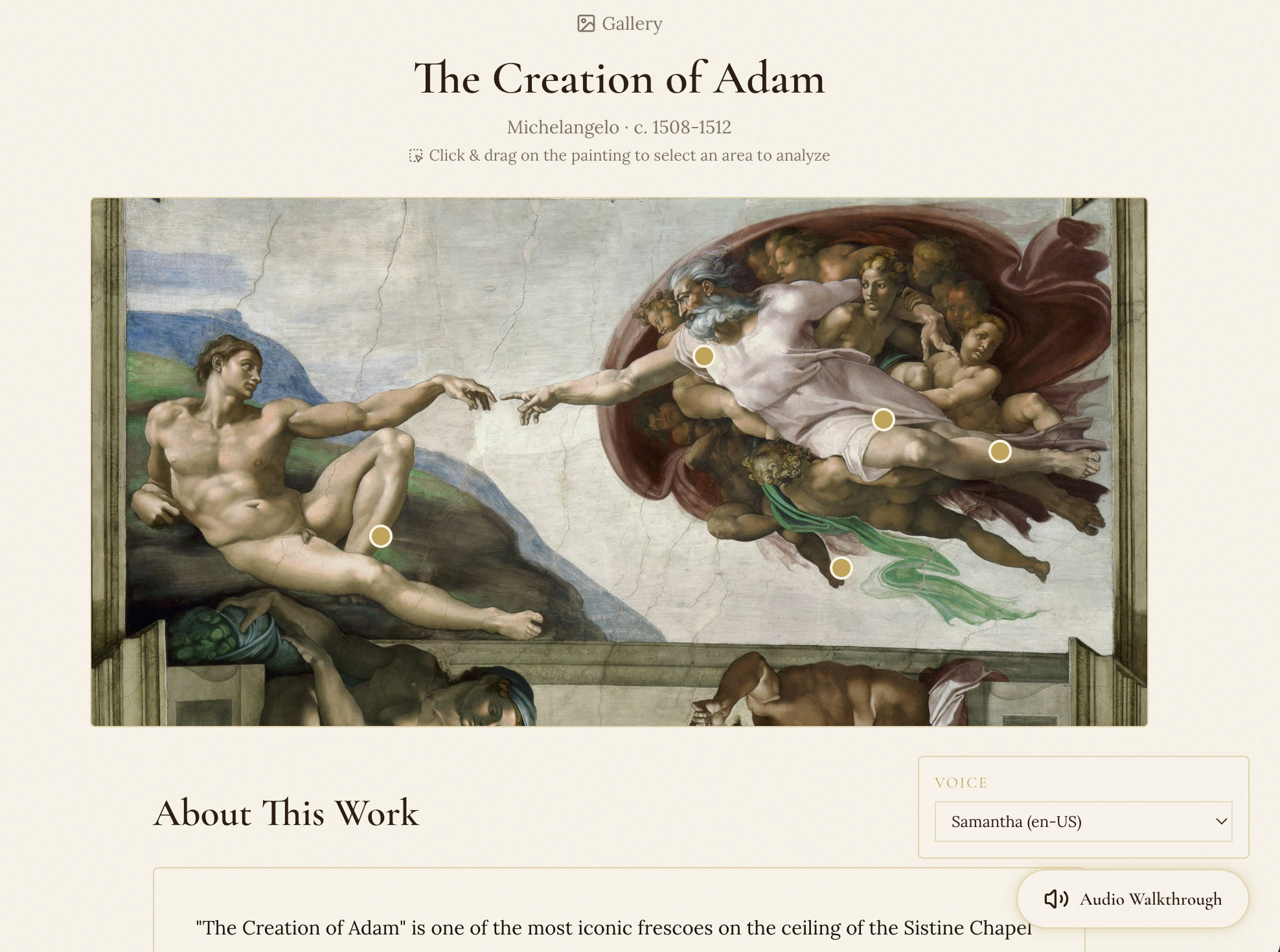
- Figure Recognition — Upload any Renaissance painting and the AI automatically identifies key figures (Jesus, apostles, saints, allegorical characters), marking them with interactive gold dots on the canvas.
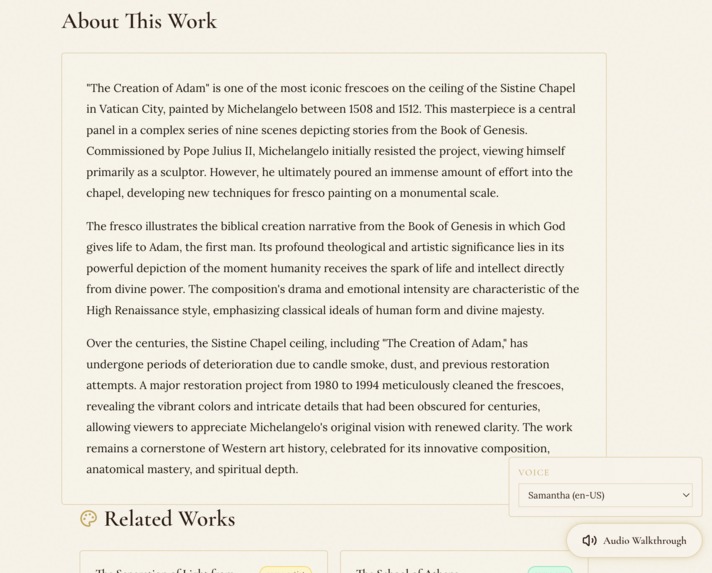
- Conversational Scholar — Click any figure and a side panel opens with a rich narrative about who they are, their role in the painting, and their historical biography. Then you can ask follow-up questions — "Why is Judas reaching for the bread?" "What was Peter's relationship with John?" — and get scholarly, streaming responses.
- Region Selection — Drag to select any area of the painting — a hand gesture, a background detail, a symbolic object — and the AI analyzes that specific crop, telling you what it means in context.
- Audio Walkthrough — A full text-to-speech guided tour walks you through every figure with browser-native voices, like having a private museum docent.
- Related Works Discovery — After analysis, the AI suggests 4-6 famous connected paintings — same artist, same era, same subject matter, or artistic influences — building a web of art-historical connections.
- Personal Gallery — Every painting you analyze is saved. Revisit your collection anytime and build your own digital Renaissance museum.
How we built it
We built Renaissance Revelations entirely on Lovable, an AI-powered full-stack development platform that let us go from idea to working product rapidly.
Frontend: React + TypeScript + Tailwind CSS, styled with a custom parchment-and-gold design system to evoke the feeling of handling an illuminated manuscript.
AI Brain — Google DeepMind (Gemini models): The core intelligence runs on Google's Gemini family, accessed through Lovable's AI Gateway:
- Gemini 2.5 Flash powers the initial painting analysis — we send the full image and it returns structured data: title, artist, date, overview, and identified figures with bounding positions, biographies, and historical context. We chose Flash for its strong multimodal (vision + text) capabilities with fast response times.
- Gemini 3 Flash Preview powers the interactive Q&A chat. When you ask a follow-up question about a figure, this model streams a scholarly response with the full conversation history as context. We chose the newer model here for its improved reasoning and conversational quality.
- Gemini 3 Flash Preview also powers the region analysis (analyzing user-selected crops) and the related works suggestion engine (generating art-historical connections via structured tool calling).
Conversational UX — Assistant UI: The figure chat panel is built with @assistant-ui/react, an open-source library that gives us ChatGPT-grade conversational UX out of the box. We use its Thread, ThreadMessages, AssistantMessage, and Composer primitives to render a streaming chat interface. The key architectural choice: on panel open, the figure's full story appears as an initial assistant message (no drip-feed), then the composer activates for free-form Q&A. We customized Assistant UI's components via its components prop (not CSS hacks) to match our parchment theme — gold-bordered message bubbles, quill-icon avatars, and warm typography.
Backend — Lovable Cloud (Supabase): Four serverless edge functions handle the AI orchestration:
analyze-painting— Vision analysis of uploaded imagesfigure-chat— Streaming conversational Q&A per figureanalyze-region— User-selected crop analysissuggest-related— Art-historical connection discovery
Lovable Cloud also provides the database (paintings table with JSONB figures storage), file storage (painting images in a public bucket), and automatic deployment — no DevOps needed.
Audio — Web Speech API: Browser-native text-to-speech with voice selection, giving users a guided audio tour through each figure's story.
Challenges we ran into
- Region analysis accuracy — Early versions sent the click coordinates to the AI, which often misidentified figures. We solved this by actually cropping the selected region from the image canvas and sending only that crop to the vision model, dramatically improving accuracy.
- Assistant UI integration — We initially tried a drip-feed approach (sending figure details as separate messages), but it felt unnatural. We pivoted to presenting the full narrative as one rich assistant message, then enabling free-form Q&A — which required careful state management between the initial story and the streaming chat adapter.
- Streaming SSE parsing — Getting token-by-token streaming right required handling partial JSON chunks, CRLF line endings, and buffer flushing edge cases.
- Image cross-origin cropping — Canvas-based image cropping for region analysis required proper CORS handling to avoid tainted canvas errors.
Accomplishments that we're proud of
- The experience genuinely feels like talking to a Renaissance scholar — our Christian friend spent 45 minutes asking questions about The Last Supper and kept saying "I never knew that."
- The drag-to-select region analysis works intuitively — you can explore details no pre-built tool would think to highlight.
- The audio walkthrough turns passive viewing into an immersive guided tour.
- The related works feature creates a beautiful web of connections — upload The Last Supper and discover Andrea del Castagno's version, Tintoretto's interpretation, and the artistic lineage.
- We built the entire full-stack application — AI pipeline, database, storage, streaming chat, audio — without writing a single line of backend infrastructure code manually, thanks to Lovable.
What we learned
- Multimodal AI is ready for art analysis — Google DeepMind's Gemini models can identify specific historical figures in paintings, understand iconographic symbolism, and generate genuinely insightful art-historical commentary.
- UX matters more than model power — Switching from raw text output to Assistant UI's conversational thread format transformed the experience from "reading a report" to "talking to an expert."
- Crop, don't coordinate — Sending a cropped image region to a vision model is far more reliable than sending coordinates with a full image.
- Lovable + Lovable Cloud eliminates the "last mile" problem — The gap between "AI demo" and "deployed product with persistence, storage, and real UX" is usually weeks of work. Lovable compressed that to hours.
What's next for Renaissance Revelations
- Multi-painting comparative analysis — Select two paintings side by side and ask the AI to compare techniques, themes, and historical context.
- Guided thematic tours — Curated paths like "The Life of Christ in Renaissance Art" or "Women in Baroque Painting" that connect your gallery paintings into a narrative journey.
- Community galleries — Share your analyzed collections with others and explore what other art enthusiasts have discovered.
- Museum integration — Partner with museums to offer this as a companion app — point your phone at a painting and get instant deep analysis.
- Expanded art periods — Baroque, Impressionism, Modern — every era has stories waiting to be told.
- Mobile-native experience — Touch-optimized region selection and swipe-based gallery navigation.
Verify everything works end-to-end Add sharing feature Add comparative analysis
Built With
- assistantui
- googledeepmind
- lovable

Log in or sign up for Devpost to join the conversation.