-
-
-

-

Remi Connects to the Redis MCP Server for Memory Observability


Inspiration
We are seeing a rapid rise in vertical AI agents being embedded into modern software products to personalize user experiences. But how do these agents actually remember, adapt, and build continuity with users over time? A major bottleneck in the AI-native Software Development Lifecycle (SDLC) is making that transition from a stateless proof-of-concept to a stateful, production-ready AI system that can remember users, context, and past interactions. Implementing reliable long-term memory for AI agents requires designing memory patterns, managing session context, setting up scalable storage infrastructure, and ensuring secure production deployment. As a result, many developers spend significant effort and toil configuring databases, retrieval layers, and observability pipelines before their agents are ready to deliver truly personalized experiences.
To address this challenge, we built Remi – a Redis Memory Infrastructure Expert and custom GitLab Duo Agent powered by Anthropic’s Claude Haiku 4.5. Remi helps developers productionize AI agents with secure, production-grade memory systems based on Redis Memory Management. Redis is an in-memory data store widely used for low-latency applications, caching, and real-time data processing. Remi leverages the Redis Agent Memory Server to help configure structured memory storage for AI agents and integrates Redis MCP tooling for memory observability. Our goal is to help GitLab developers move faster from experimental AI agents to stateful systems with robust long-term memory.
What it does
Remi is a Redis Memory Infrastructure Expert agent that helps developers turn a stateless AI agent prototype into a stateful, production-ready AI system with secure persistent memory, all within their GitLab development workflow.
For example, a team might build a domain-specific AI agent for customer support, travel planning, internal knowledge assistance, or personal productivity. The agent may perform well in isolated test sessions, but once it is deployed into a real product, it needs to retain user preferences, recall relevant prior interactions, and preserve context across conversations in a scalable and reliable way. That jump from a stateless demo to a memory-aware production system is where many teams run into architectural and infrastructure challenges.
Remi helps close that gap by acting as an AI memory infrastructure teammate. Developers can work with the agent directly from their IDE, and from there Remi examines the repository context – including dependencies, agent logic, config files, and surrounding infrastructure – to infer the agent’s domain, runtime setup, and memory needs. With that context, Remi helps configure a production-grade memory architecture, guiding developers through the setup instead of leaving them to manually piece together memory systems on their own.
Memory Architecture Expertise & Deployment Pipeline
Remi writes code to implement a two-tier memory architecture that enables agents to maintain context across interactions. The first layer is working memory, which is session-scoped and stored with a time-to-live (TTL), allowing the agent to track recent conversation history and compress older messages to maintain efficiency. The second layer is long-term memory, which is user-scoped and persistent, storing facts, preferences, and semantically searchable embeddings. These memories are managed through the Agent Memory Server, which interfaces with Redis and RedisSearch to support both structured key-value storage and vector-based retrieval. By isolating memory namespaces per user and agent type, the system ensures scalable personalization while maintaining strong separation of context across sessions and applications.
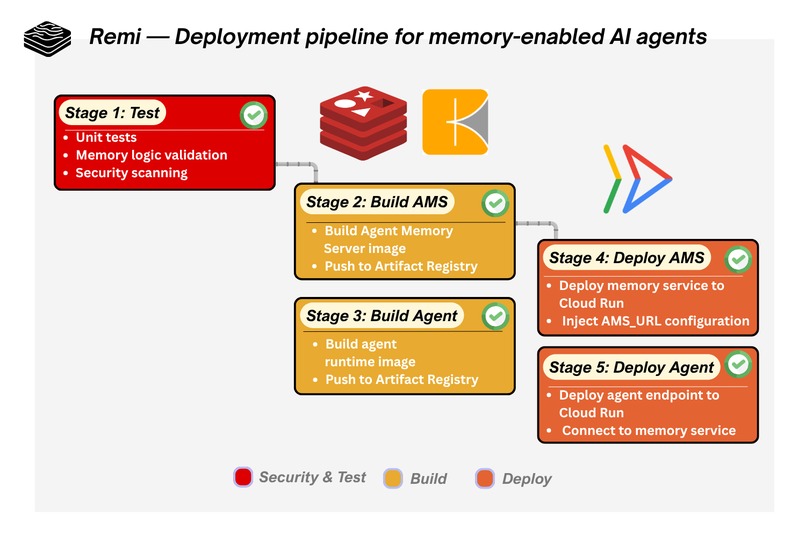
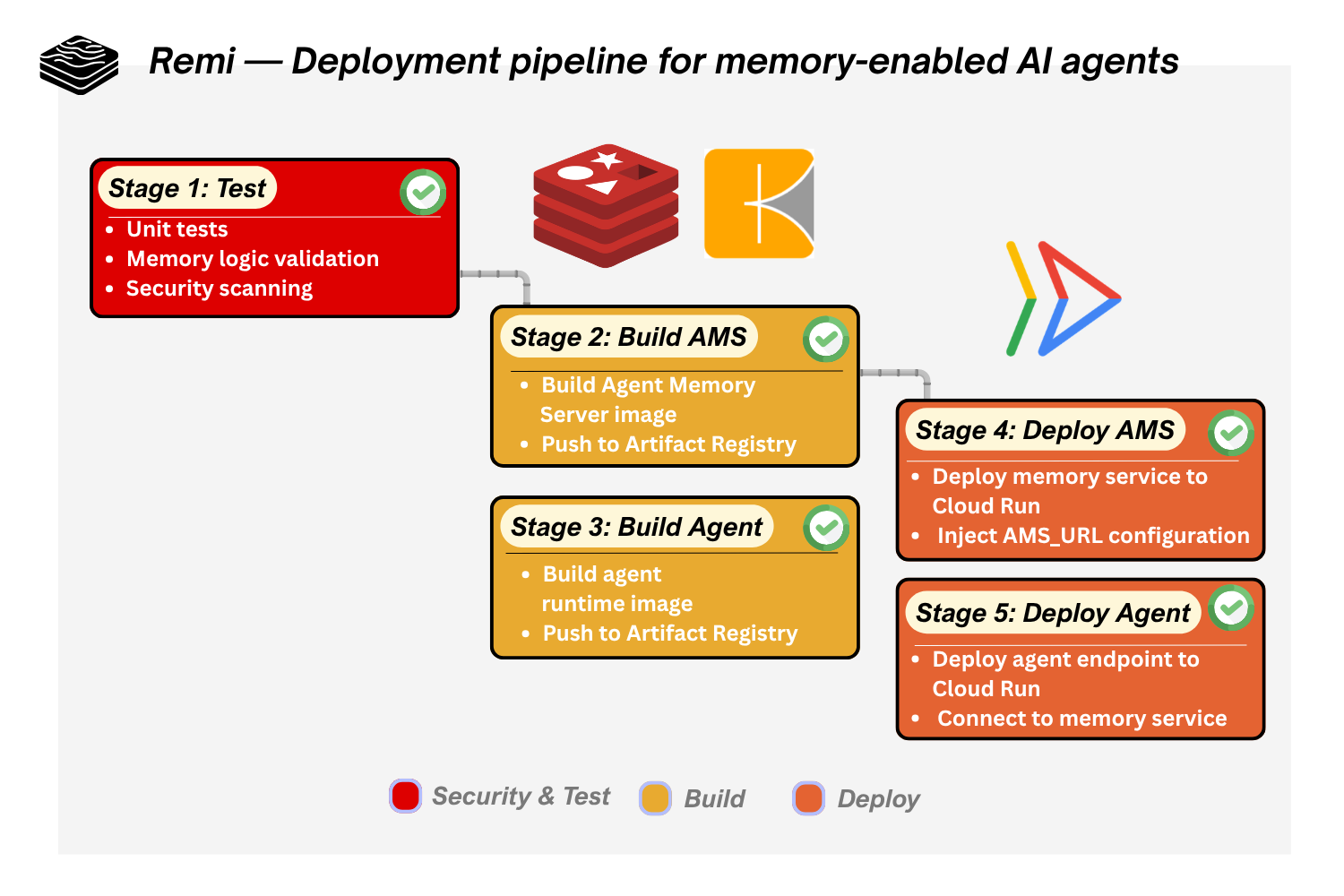
To productionize stateful AI agents, Remi configures a 5-stage CI/CD pipeline that automates the journey from a simple code push to a fully deployed memory-enabled agent service.
| Stage | Pipeline Step | What Happens in This Stage |
|---|---|---|
| Stage 1 | Test – Unit & Memory Validation | When code is pushed, the pipeline runs unit tests and memory-specific validation checks to ensure that memory storage, retrieval logic, and session handling behave correctly before any build or deployment begins. |
| Stage 2 | Build – Agent Memory Server (AMS) | The pipeline builds a container image for the Agent Memory Server, which manages working and long-term memory operations. Kaniko is used for secure container builds, and the image is pushed to an artifact/container registry. |
| Stage 3 | Build – AI Agent Runtime | A second container image is built for the AI agent runtime, packaging the agent logic, memory integration modules, and dependencies. This image is also versioned and pushed to the registry for deployment. |
| Stage 4 | Deploy – Memory Service (AMS) | The AMS container is deployed to a Cloud Run service, creating a scalable memory backend endpoint. Secure environment variables such as AMS_URL and Redis connection credentials are injected so the agent can connect to its memory infrastructure. |
| Stage 5 | Deploy – Live Agent Endpoint | Finally, the agent runtime is deployed to Cloud Run as a live inference endpoint, now connected to the deployed memory service. This enables the AI agent to store and retrieve context across sessions in a production environment. |

Figure 1. Remi — Deployment pipeline for memory-enabled AI agents.
Using Redis MCP (Model Context Protocol) to Validate Stored Memories
To make memory behavior easier to inspect and validate, Remi also integrates Redis MCP tooling for validation and observability. This gives developers a way to inspect stored memories, confirm that important user context is actually being persisted, and understand how retrieval affects downstream agent responses over time, all without leaving their IDE. We added this functionality to make it easier for developers to evaluate whether the agent is remembering the right things in practice.
After Remi helps configure your domain agent’s memory infrastructure and deployment pipeline, developers can ask Remi requests like:
“Can you use the Redis MCP tools to inspect my database?
- List all keys matching
Paul*- Retrieve the contents of working memory for our customer support agent for user 'Sam', Session 3
- Check whether any long-term memories exist for user
Bob- Show me what memories are currently stored.”
To carry out this request, Remi can use Redis MCP tools such as mcp__redis-memory__scan_keys to enumerate matching keys, mcp__redis-memory__json_get to inspect JSON-backed working memory objects, mcp__redis-memory__type to determine how memory entries are stored, and mcp__redis-memory__hgetall to inspect hash-based long-term memory index entries such as memory_idx:*. This allows developers to directly validate working memory records, persistent user memories, namespace structure, and stored retrieval data inside Redis.
🔗 You can find the Remi agent configuration and MCP setup instructions here:
Remi GitLab Repository
What we learned
Working on Remi made us realize that building useful AI agents is no longer just about model quality – it is increasingly about how agents manage memory and context over time. Designing memory systems that are scalable, secure, and aligned with real product requirements is crucial, and decisions around user isolation, retrieval strategies & persistence layers can significantly influence how personalized and reliable an agent feels in practice.
We also realized that AI agents can provide valuable stack-specific expertise for AI development workflows. Agents like Remi can help developers implement memory infrastructure patterns such as persistent memory, semantic retrieval, and observability, pointing toward a future where specialized expert agents help teams build better AI systems.
What's next for Remi
Looking ahead, we plan to extend Remi to support a wider ecosystem of AI memory architectures and agent frameworks for more complex multi-agent applications. Currently, Remi’s strongest expertise is in LangChain-based memory patterns and Redis-backed memory infrastructure, but over time we want to give developers more flexibility in choosing their memory stack, including support for Google ADK, Vertex AI Memory Bank, hybrid vector databases, and other orchestration frameworks.
Our goal is for Remi to evolve into a more adaptable memory infrastructure expert that can help teams design and deploy stateful AI systems using the tools and cloud ecosystems that best fit their production needs. We hope to evolve Remi into a more comprehensive AI development companion*, supporting developers as they build the **next generation of personalized AI software!
Built With
- agent-memory-server
- anthropic-haiku
- ci/cd
- cloud-run
- gitlab-duo
- kaniko
- langchain
- model-context-protocol
- redis
- redis-cloud-database
- redis-mcp-server




Log in or sign up for Devpost to join the conversation.