-
-

front
-

Pilot
-

Problem And Solution
-

Sonar API Usage
-
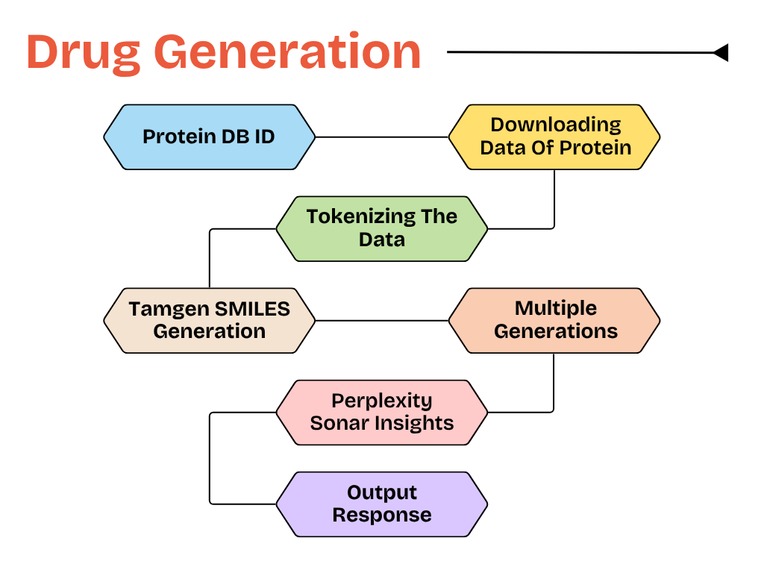
Drug Generation Work Flow
-
Home Page
-
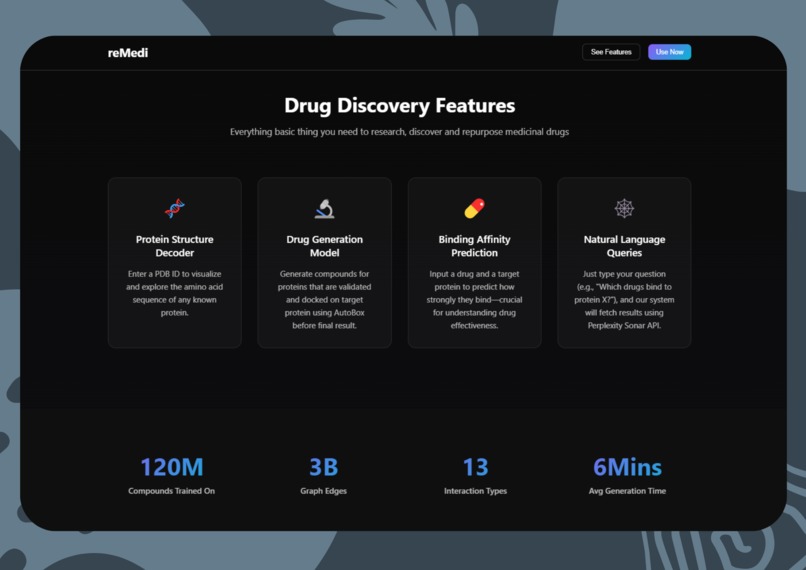
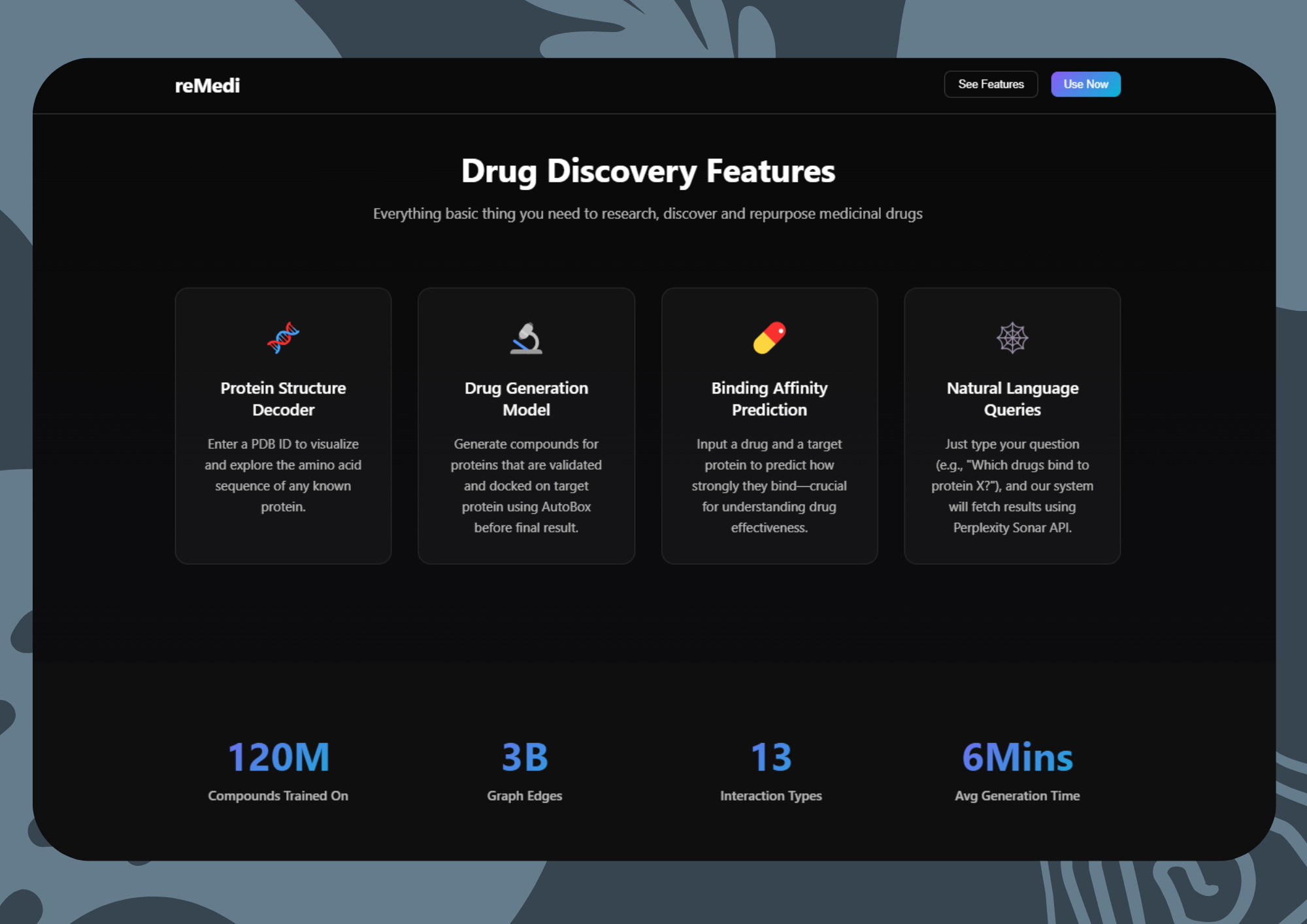
Some Features






In a sea of quick answers and chatbots, reMedi chose the hard path — tackling one of the most complex, expensive, and uncertain stages in healthcare: early-stage drug discovery.
We didn’t just build a demo. We built an AI-powered pipeline that takes you from a disease target to real compound generation and explainable evaluation — all in one platform. Using models like TamGen, chemBERTa, and DeepPurpose, and tying them together with Perplexity Sonar and LangChain, we made scientific discovery searchable, explainable, and actionable.
This isn’t just about tech — it’s about saving years of research, millions in cost, and potentially giving hope to patients who currently have no cure.
reMedi is a beginner-friendly toolkit for drug discovery that uses some of the most advanced AI models for designing new compounds, like TamGen, chemBERTa, and DeepPurpose. It also includes smart tools for searching with graphs to find relations between existing entities (genes, proteins etc), understanding molecule structures, and using Perplexity Sonar API to proovide more context to the generated results making it more human interpretable and accelerating research
reMedi streamlines the most resource-heavy and uncertain stages of early drug discovery — from identifying a viable target to generating and evaluating candidate compounds. This drastically reduces time, cost, and cognitive overhead for researchers, bridging gaps between silos and boosting the chances of clinical success.
Drug discovery takes around 10-15 years [Source: DiMasi, J. A., Grabowski, H. G., & Hansen, R. W. (2016). Innovation in the pharmaceutical industry: New estimates of R&D costs. Journal of Health Economics, 47, 20–33.] reMedi accelerates drug discovery by unifying the entire pipeline — from molecule creation to deep biological insight — into a single, intuitive system. It’s not just faster — it’s smarter, more connected, and built for the urgency of real-world healthcare, saving 3-5 years of development time and plans to save more in future iterations
Use the example of 2qwo (a protein related to DnaK protein, In pancreatic cancer, the protein DNAJA1 (which interacts with DnaK) has been found to be overexpressed, potentially impacting cancer cell survival and migration. The .cif files from the RCSB PDB database have been already added making generation much faster. Other protein’s compound generation may take 15minutes
Source for relation of 2qwo with pancreatic cancer
Installation On Local Computer
NOTE: This project was built and compiled on wsl, please use a linux machine to run this otherwise you may run into os errors (servers use linux anyways :P). Most of the packages are listed in requirements.txt a few packages to be installed from github has been left out.
packages not in requirements (install them inside conda environment after installing everything in requirements.txt): -git+https://github.com/bp-kelley/descriptastorus@9a190343bcd3cfd35142d378d952613bcac40797 -git+https://github.com/SigmaGenX/TamGen@9459b3f0290ea7b79061d9e81eae284f93891a82#egg=fairseq > this is a tricky package to install, your python environment must be 3.11 not higher and your pip must be "pip<24.1" -pyvis (just pip install this) -torch-cluster (just pip install this) -flask (just pip install this) -flask-cors (just pip install this)
If anything still goes wrong, please feel free to message me or drop an issue here and I would guide you through it
Local Enviroment - Setting up
Requirements:
- Linux or MacOS
- Docker
- Conda
Git clone and navigate to project repo
Setup Docker: Type in terminal - This will install and run an image of ArangoDB with password=perplexity
docker compose up -d
Create a conda environment
conda create --n remedi python=3.11
conda activate remedi
Install requirements and the listed above requirements
pip install -r requirements.txt
inside main.py (server) on line 295 replace the text with your perplexity api key, not the best approach but this whole project was made in between my final exams hence tried to save time here and there, you may make your .env file
running it:
Run the cells in resourceGather.ipynb after that create the database using databaseCreation.ipynb
after this your database would be created, but i also hosted the database on gcp, incase you cannot then ask me for the credentials and i would mail you
update the db.py with your database credentials
then run main.py
python3 main.py
this will start the flask server which has all the endpoints
/generate-compound has the endpoints to generate compound pdb id of protein
it gives 3 results, none if the protein does not have ligands, only a refernce compound to start researching with if it cannot create compounds for the protein and a set of generated compounds when everything is doable
it usually takes 5-10 minutes to generate on my computer due to low memory and not powerful enough cpu. Make sure you have atleast 16-32gb of ram to avoid the server from freezing or crashing altogether. If you use gunicorn and it eats up a lot of memory, shift to running it using python3 main.py
curl -X POST http://localhost:5000/generate-compounds -H "Content-Type: application/json" -d "{\"pdb_id\":\"2qwo\"}"
/pdb-sequence for getting the amino acid sequence from pdb id of protein
curl -X GET "http://127.0.0.1:5000/pdb-sequence?pdb_id=2qwo"
/predict-binding-affinity to predict the binding affinity between a compound (in SMILES representation) and sequence of proteins
curl -X POST http://127.0.0.1:5000/predict-binding-affinity -H "Content-Type: application/json" -d "{\"smile\":\"Nc1ncnc2c1ncn2[C@@H]1O[C@H](CO)[C@@H](OP(=O)(O)OP(=O)(O)O)[C@H]1O\", \"target_sequence\":\"MKVLYNLV...\"}"
/text-to-aql for converting text to graph queries using perplexity so researchers can easily find relations
curl -X POST http://127.0.0.1:5000/text-to-aql -H "Content-Type: application/json" -d "{\"query\": \"Which drugs bind to EGFR?\"}"
NOTE: The backend is already hosted on google cloud platform as a vm, at the external ip- http://35.193.196.5:5000 , you may query from it, if it is not running (may get shutdown as its on free tier) contact me i'll turn it on.
Frontend:
The front end is built on React+Vite, install react-router-dom and everything would be fine, on research.jsx page search for authorization and add your perplexity API key in it, it would appear 3 time, i could had made an env variable or an actual variable but in rush i didnt think much about it. I would refactor the code after hackathon
the endpoints are setup just change the parent url according to your server ip (localhost or my gcp server),
Architecture
reMedi is designed as a modular, multi-model system that brings together powerful tools for end-to-end drug discovery. Its flexible setup allows researchers to easily expand or customize the toolkit, as all core components and data connections are built in from the start.
- Core Modules
- TamGen: A transformer-based generative model trained on over 120 million SMILES strings of bioactive compounds. It generates novel molecules, which are automatically validated and docked to target proteins.
- DeepPurpose: A versatile deep learning framework that predicts the binding affinity between drugs and target proteins. It complements TamGen by analyzing and refining already-docked compounds for better accuracy.
- chemBERTa: A transformer model also trained on 120+ million SMILES sequences. It creates rich vector embeddings for molecules, enabling advanced analysis and repurposing of both FDA-approved and newly generated compounds.
- Knowledge Graph & Retrieval Modules
- ArangoDB: A multi-model database that organizes relationships between genes, proteins, diseases, drugs, and molecules in a structured, connected way.
- Graph-based querying Allows smart retrieval of molecular data—linking known drug-target interactions to newly generated compounds for comparison or discovery..
GraphRAG & Biomedical Reasoning
- GraphRAG framework Augments traditional RAG (Retrieval-Augmented Generation) methods by incorporating graph-based reasoning for biomedical data
- Ontological mapping: Integrates structured biomedical ontologies (e.g., DrugBank, ChEMBL) to enhance retrieval and inference.
Perplexity Natural Language Interface
- **Perplexity Sonar Integration**
Allows researchers to ask natural language questions (e.g., “What compounds bind to the EGFR T790M mutation?”), which are translated into structured AQL (ArangoDB Query Language) queries using the Perplexity Sonar API.
it also provides context and insights to the result that help towards research in front end
- **LangChain Bridge**
reMedi connects Perplexity to the rest of the system via LangChain, enabling fluent conversion from plain English to executable queries over molecular, protein, or disease graphs.
Use Cases
Aids with deep research with proper citations
Convert natural language to graph queries
Provide more insights and context on results from backend to give the researchers some idea about the entity
Note: Open the link in incognito mode if it doesn't open regularly, Browser security plays around with the website as it does not have a ssl


Log in or sign up for Devpost to join the conversation.