-
-
ReliefX Disaster Autonomous response system
💡 Inspiration
In the critical hours after a disaster, response teams are in a race against time. The current process—manually analyzing satellite imagery, assessing damage, and creating logistics plans—is slow, taking days. We were inspired to build an autonomous system that shrinks this entire workflow from days to seconds, delivering actionable intelligence when it's needed most.
⚙️ What it does
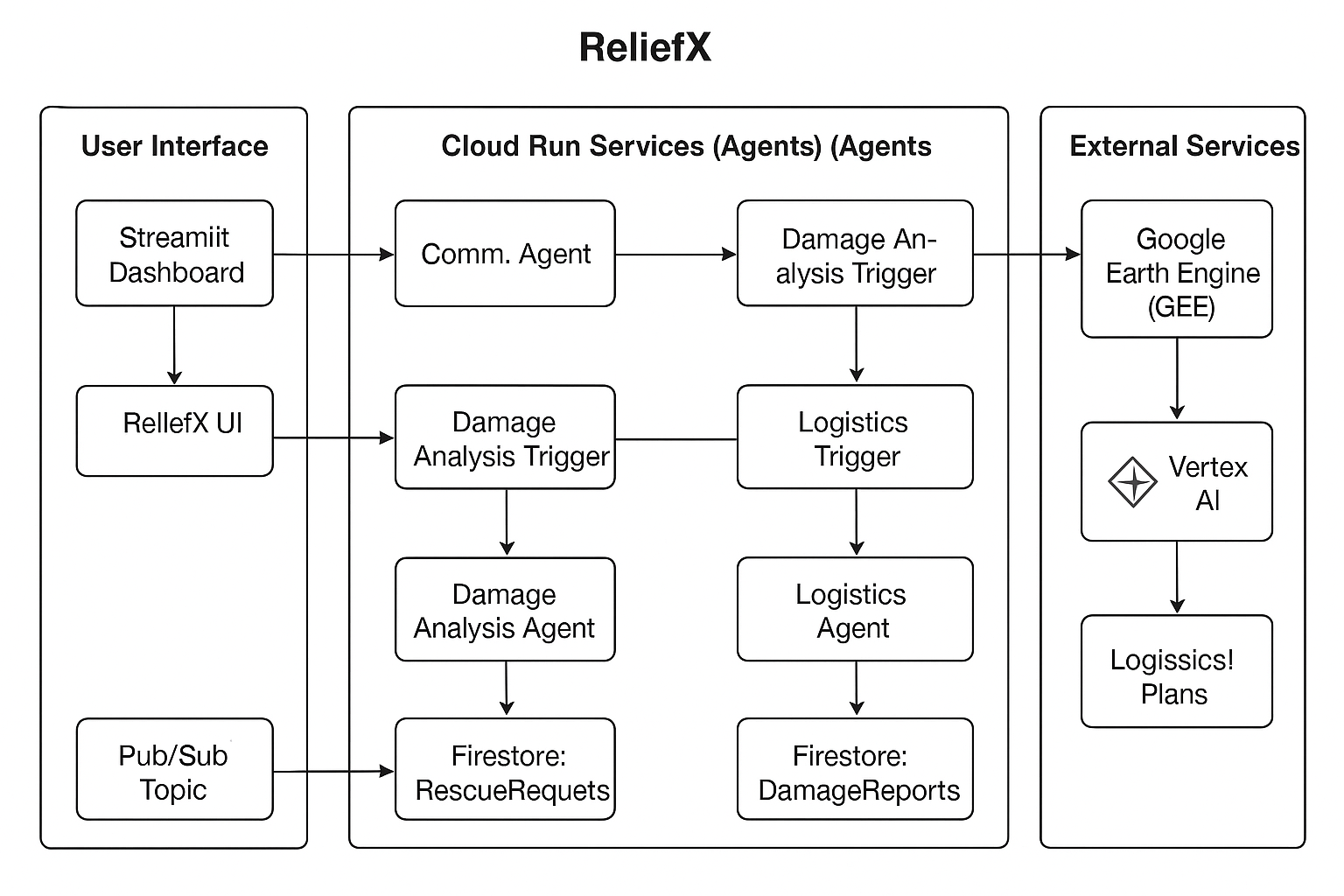
ReliefX is an autonomous, multi-agent system for end-to-end disaster response.
A user selects a disaster event on our Streamlit dashboard.
This triggers our Comm Agent (Cloud Run), which fires a Pub/Sub message.
The Damage Analysis Agent (Cloud Run) wakes, queries Google Earth Engine (GEE) for GeoJSON data (like flood plains and road cuts), and uses Gemini 2.5 Flash to synthesize this data into a structured JSON DamageReport.
This report is saved to Firestore, which triggers our Logistics Agent (Cloud Run).
This final agent reads the report, analyzes it with Gemini, and generates a complete LogisticsPlan—including resource allocation and priority zones.
The dashboard updates in real-time, showing all three reports and the final map overlays, completing the entire workflow in under 30 seconds.
🏗️ How we built it
We built ReliefX on a 100% serverless, event-driven Google Cloud stack.
Compute: Three independent Python agents (Comm, Damage, Logistics) and the UI are deployed as containerized Google Cloud Run services. This provides infinite scalability with a zero-cost-when-idle benefit.
Orchestration: Google Pub/Sub acts as the system's nervous system, passing messages between agents asynchronously. This decouples our services, making the system highly resilient.
Database: Google Firestore serves as the system's "memory." It stores all structured reports (RescueRequest, DamageReport, LogisticsPlan) and allows the Streamlit dashboard to listen for real-time updates.
AI & Data:
Google Earth Engine (GEE): Provides summarized geospatial GeoJSON data, a critical pivot from raw images.
Vertex AI (Gemini 2.5 Flash): Used for its powerful reasoning and, most importantly, its native structured JSON output, which we validate directly against our Pydantic models.
UI: A unified Streamlit dashboard provides the single-pane-of-glass for initiating the request and viewing the final plan.
🏃 Challenges we ran into
Our biggest challenge was a strategic pivot. Our initial plan to use a multi-modal LLM to analyze raw GeoTIFF satellite images would have required expensive, slow-to-provision L4 GPUs.
We realized this was the wrong approach. The solution was to simplify the data before it hit the LLM.
We pivoted to querying GEE for summarized GeoJSON data (text and coordinates) instead. This transformed the problem from complex visual analysis to simple, fast text-reasoning. This change eliminated the need for GPUs entirely, slashed our costs, and dramatically improved latency.
✨ Accomplishments that we're proud of
The 30-Second-Pipeline: Successfully executing a full-stack workflow—from user request to geospatial data query, to two separate LLM reasoning steps, to a final logistics plan—in under 30 seconds.
The GPU-less Architecture: Our strategic pivot away from GeoTIFFs to GeoJSON. This was the key decision that made the project fast, scalable, and cost-effective for a hackathon.
Autonomous Agents: Building a truly asynchronous, event-driven multi-agent system on Cloud Run and Pub/Sub that "just works."
AI-Generated JSON: Using Gemini's structured output to reliably generate JSON that perfectly matches our Pydantic schemas, making the entire data pipeline robust and error-free.
📚 What we learned
Don't make the LLM do all the work. Our biggest takeaway was to use the right tool for the job. By letting Google Earth Engine do the heavy lifting of geospatial processing, we freed the LLM to do what it does best: reason, summarize, and plan.
We also learned the sheer power and speed of a serverless, event-driven stack (Cloud Run + Pub/Sub). We built a complex, resilient, and massively scalable system in a fraction of the time it would have taken with traditional VMs.
Open issues we are working on
- No use of NVIDIA L4 GPU since our quota request is not yet approved.
- Still some bugs are there like GEE processing is being mocked which will be solved in coming days.
🚀 What's next for ReliefX
Richer Data Inputs: Integrate real-time data APIs for weather (NOAA) and traffic (Google Maps) to make the LogisticsPlan even more dynamic and accurate.
Live Resource Management: Replace the mocked resource inventory with a live database of available assets (personnel, vehicles, supplies) for the Logistics Agent to allocate.
Human-in-the-Loop: Add a "review and approve" step for a human operator, who can edit the AI-generated plan before dispatching it.
Proactive Analysis: Use a Cloud Scheduler to automatically run the Damage Analysis Agent on high-risk regions before a disaster is even reported.

Log in or sign up for Devpost to join the conversation.