-
-

Homepage
-
Prediction form
-
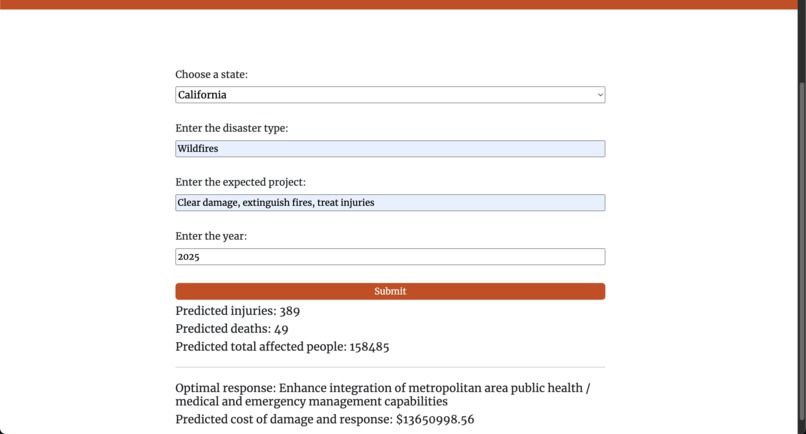
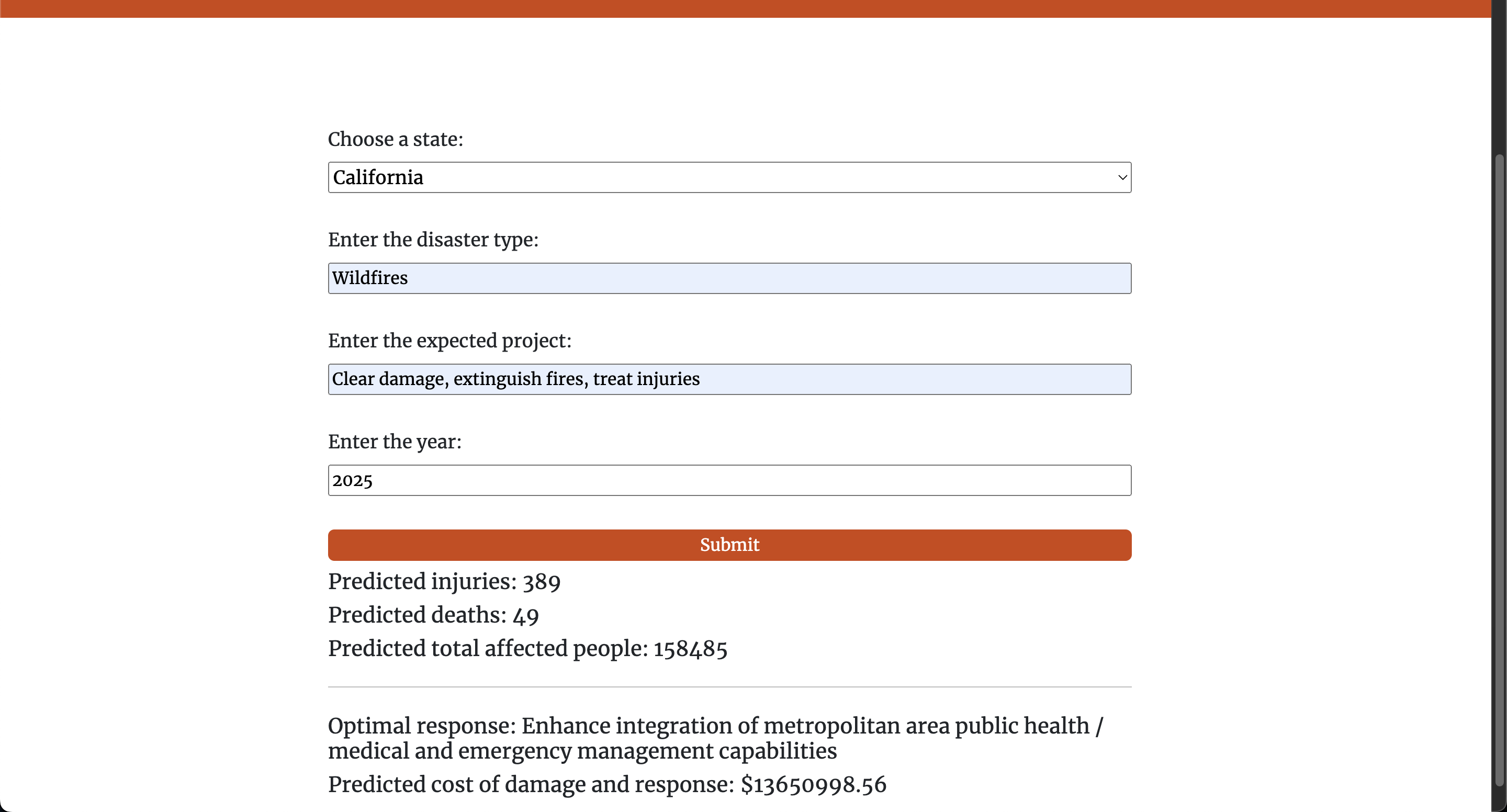
Prediction results

Inspiration
I was inspired by the current California wildfires. This is a major current event that is impacting a large population, and in line with the theme of social impact, ReliefRadar aims to minimize the impact of such events.
What it does
ReliefRadar allows professionals and individuals to see the predicted impacts of a disaster. This web application allows users to input parameters surrounding the disaster, and this is fed to the machine learning model. This model outputs its predictions on a variety of factors. The major ability of the model that has large potential is to predict the optimal course of action, which tells professionals and rescue workers the best way to perform their rescue efforts and mitigate the impacts of the disaster. In addition, it outputs the estimated cost of the disaster and the efforts to combat it, which aids resource allocation and planning. Finally, the model outputs its prediction for the impact on human life through the potential number of injuries and deaths, and the total number of people affected. This is then displayed to the user, who can use this information either for their personal use or to aid in the mitigation attempts.
How I built it
I used open-source datasets from the Federal Emergency Management Agency (FEMA) as well as a dataset from Kaggle. Using these datasets, I trained a machine learning regression model using Scikit-Learn. I used the random forest training method, which is an ensemble training method that uses decision trees for its training. I used the Flask python framework for the backend of the website, and HTML, CSS, and JavaScript for the frontend.
Challenges I ran into
The main issue was that the datasets and majority of input fields are text fields, while a regression model takes in numerical values. To solve this issue, I tokenized all the text of the datasets and the inputs of the users to convert this to numerical values. This allowed me to take in the input in text form, tokenize the text and convert it to numerical values to train and get the predictions of the model, and return the tokenized text to its original form to display to the user.
Accomplishments that I'm proud of
I am proud of the accuracy of my model. I was able to achieve a mean square error (MSE) value of 0.06.
What I learned
I learned about using the API and csv files of datasets to manipulate this data to optimally train a regression model.
What's next for ReliefRadar
In the future, I hope to be able to expand the reach of ReliefRadar to the entire world to predict disasters around the planet. In addition, I hope to implement natural language processing to allow the user to input a full description of the disaster, and for the model to use this information for increasingly accurate results.
Built With
- css3
- flask
- html5
- javascript
- machine-learning
- python
- random-forest
- regression
- scikit

Log in or sign up for Devpost to join the conversation.