-
-

-
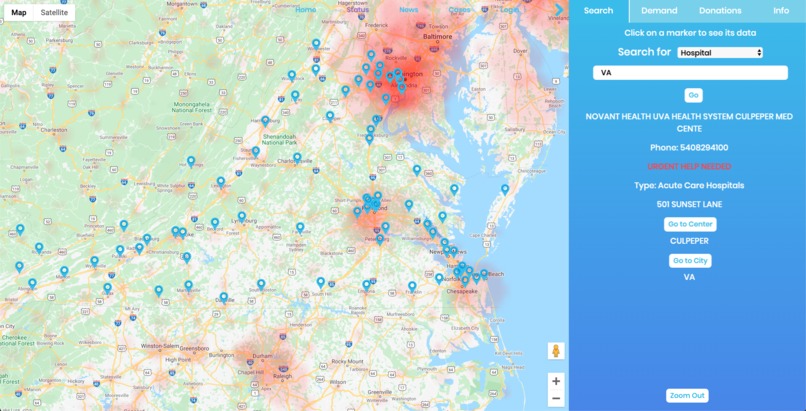
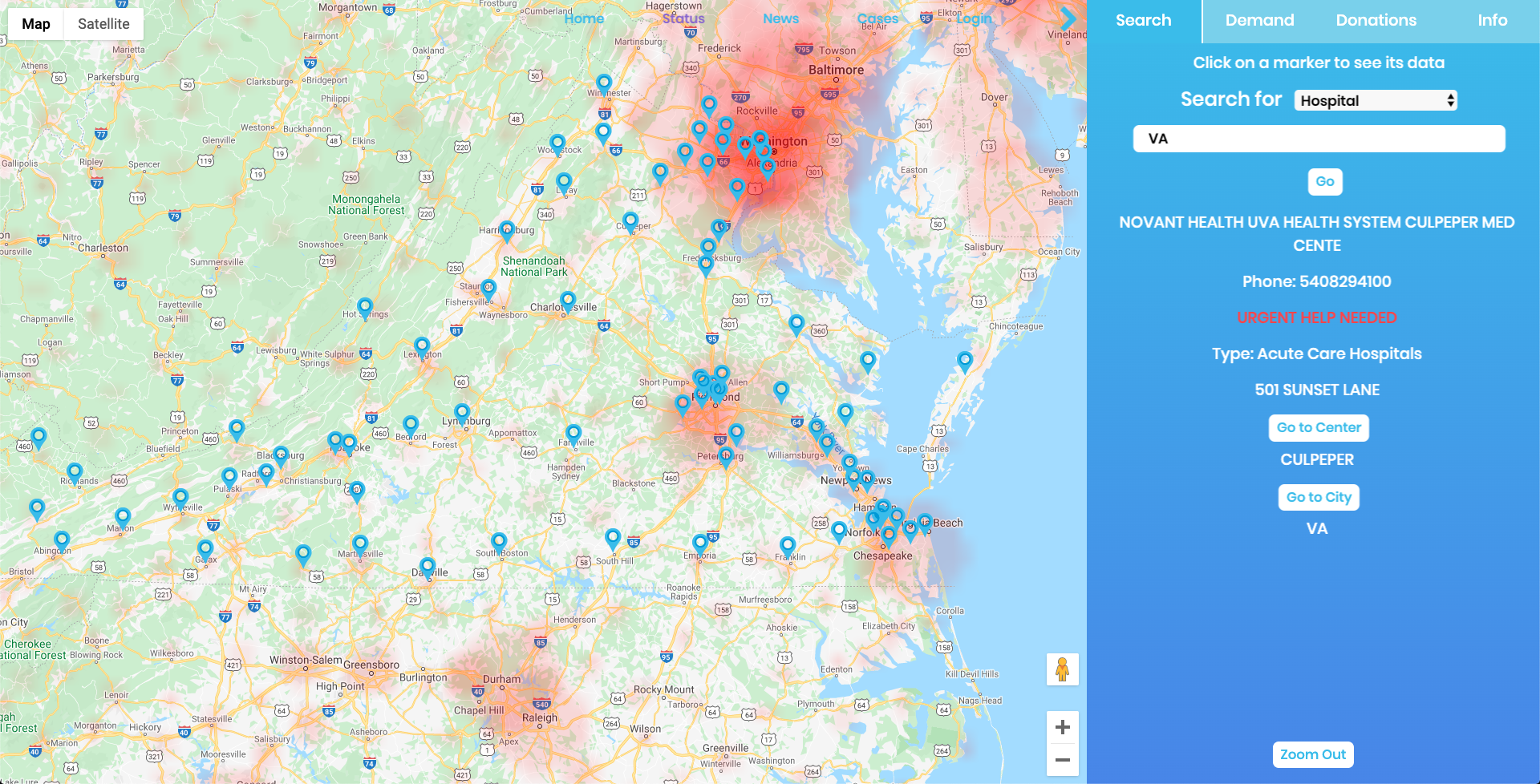
Search relief centers and testing centers and click on the marker to see their info. Current cases are also on the map to give perspective.
-
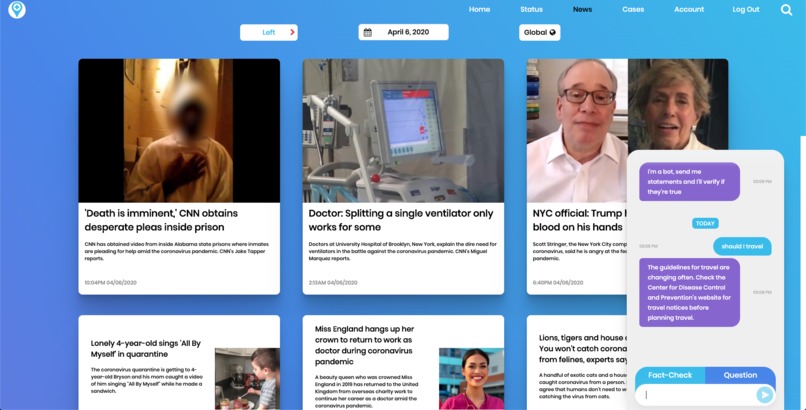
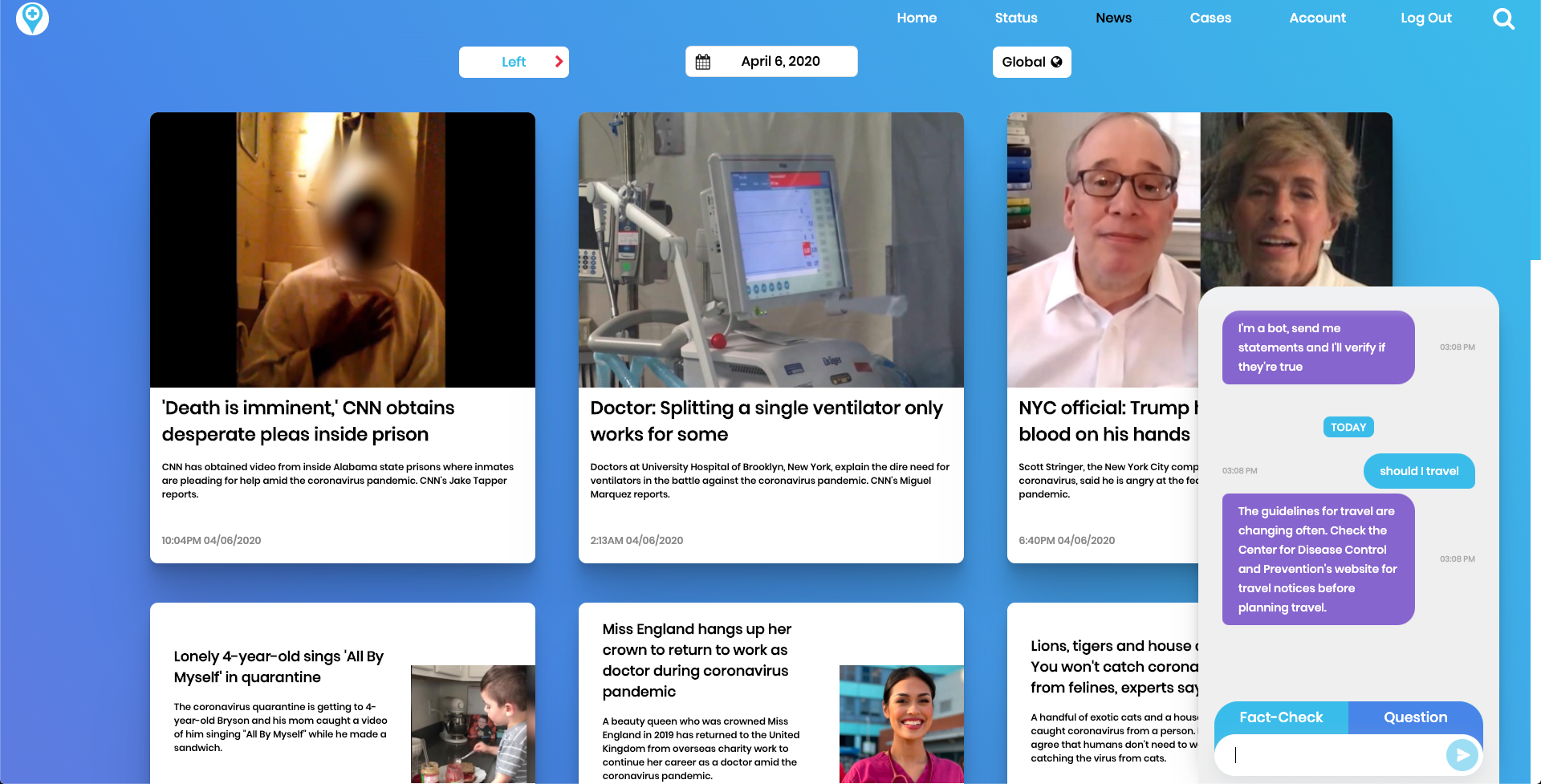
See news articles from different political leanings and a chat bot capable of fact checking and answering general Covid-19 questions.
-
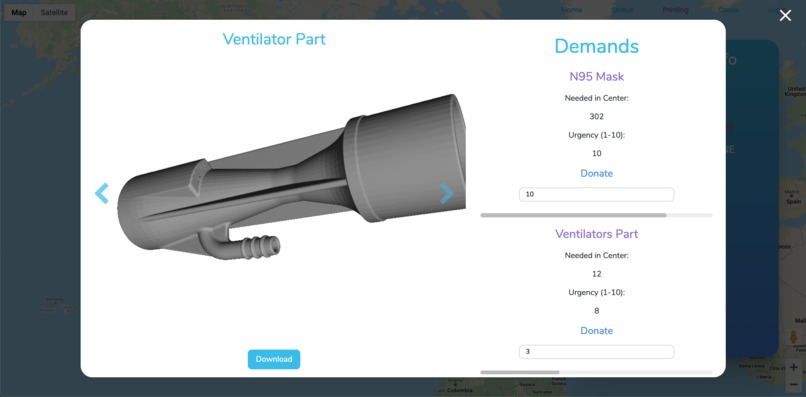
We integrated a system for those with 3D printers to actively contribute to medical facilities who are running short on supplies.
-
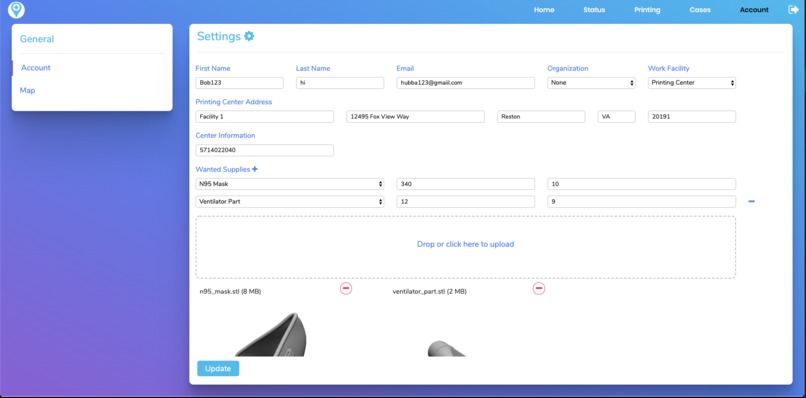
User account pane, an area where hospitals can update the items they need, so people with those supplies can donate to the right hospital.



Inspiration
The very world we know and love is changing by the second due to the spread of COVID-19. Though we may think that this pandemic is bound to end soon, we are just at the beginning of this dangerous event. After witnessing in the recent news, pictures of an exhausted medical staff, we started to set our complaints about social distancing aside, and started to focus on the issue at hand. These workers are currently working day and night to fight this disease risking their lives. At the forefront of this pandemic, relief centers are suffering from a severe lack of supplies. Shortages have gotten so bad, that staff and support facilities have had to reuse supplies such as surgical masks, inducing severe health hazards. Seeing all this unfold before us we wanted to do something about the situation especially if it could be solved by developing a way to rally community support.
What it does
CoronaConnect is a system that allows the public, which includes communities and organizations, to see the current resources, demands, and specific deliveries at a hospital or food bank. Using this system, people and organizations with extra supplies can find the right centers to donate to and assist the community. We also want to make sure that our user’s have the most valid and recent news that they can get, and so we have a new pane which has options for stance, date, global/local, and questions. We have also included a Fact-Checking bot that uses a both a recurrent LSTM and a couple Google API’s to validate user’s claims.
This system helps communities and organizations to better manage supplying these support facilities, such as hospitals and soup kitchens.
How I built it
We used a Keras based recurrent LSTM model and Google API’s for the fact checking bot. This model was incorporated into our backend Firebase and Flask application, to dynamically update user’s profiles in real time. This backend system was integrated into our dynamic front-end interface, which used JQuery and other front-end software. For example, on the status page, we are able to read changes a user makes to their account and transfer that on to the map using flask and jquery.
Challenges I ran into
Some challenges we ran into when developing the website was finding a way to host our website. Previously, when creating websites, we only worked on the front-end so hosting on GitHub pages was plausible. However, because we incorporated Flask and other backend techniques, we required a server. So, we looked into cost-free alternatives to host our backend system. One solution we found was a free platform called Heroku. The problem with Heroku was that it was unable to host our application because our TensorFlow model required more memory than Heroku allocated for us.
Another problem we ran into was implementing the TensorFlow Recurrent LSTM model. Our TensorFlow backend scraps all web articles with all keywords relating to the claim using Google API’s, and then determines the validity of all the articles in that list using the model. However, we faced troubles with Google API because the API did not always produce the right web scraping results, often returning articles with no relevance to the keywords supplied.
Accomplishments that I'm proud of
Being able to integrate our account system with firebase and updating information on our maps in real-time. We were also able to effectively integrate a machine learning model that fact checks claims, with a chatbot as the frontend.
Another major breakthrough was being able to use actual relief center locations on the status page. Being able to host it after trying out heroku and pythonanywhere, we were finally able to host our website on an Amazon EC2 instance.
What I learned
We learned how to effectively integrate back-end techniques, such as Flask, Firebase, and Keras, into a dynamic front-end that is based on real-time user data and input.
What's next for CoronaConnect
We will continue to expand our library of hospitals and food banks and improve our news and fact-checking algorithms.
For our Fact-Checking algorithm, we want to implement an Azure Web Scraper that returns better results for our algorithm.



Log in or sign up for Devpost to join the conversation.