-
-
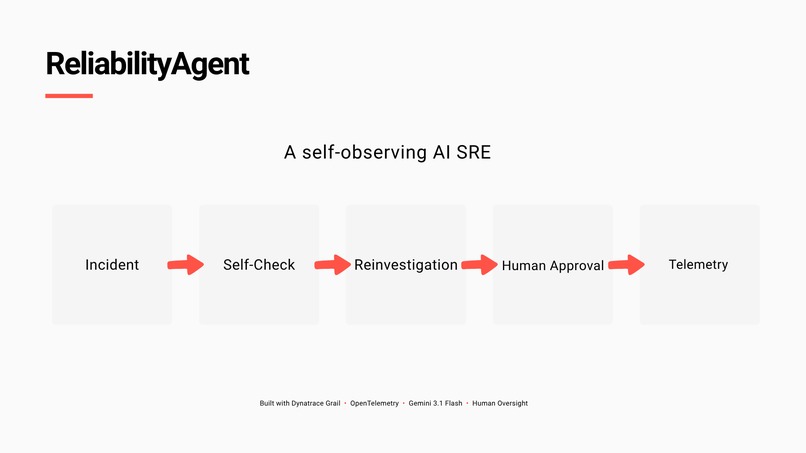
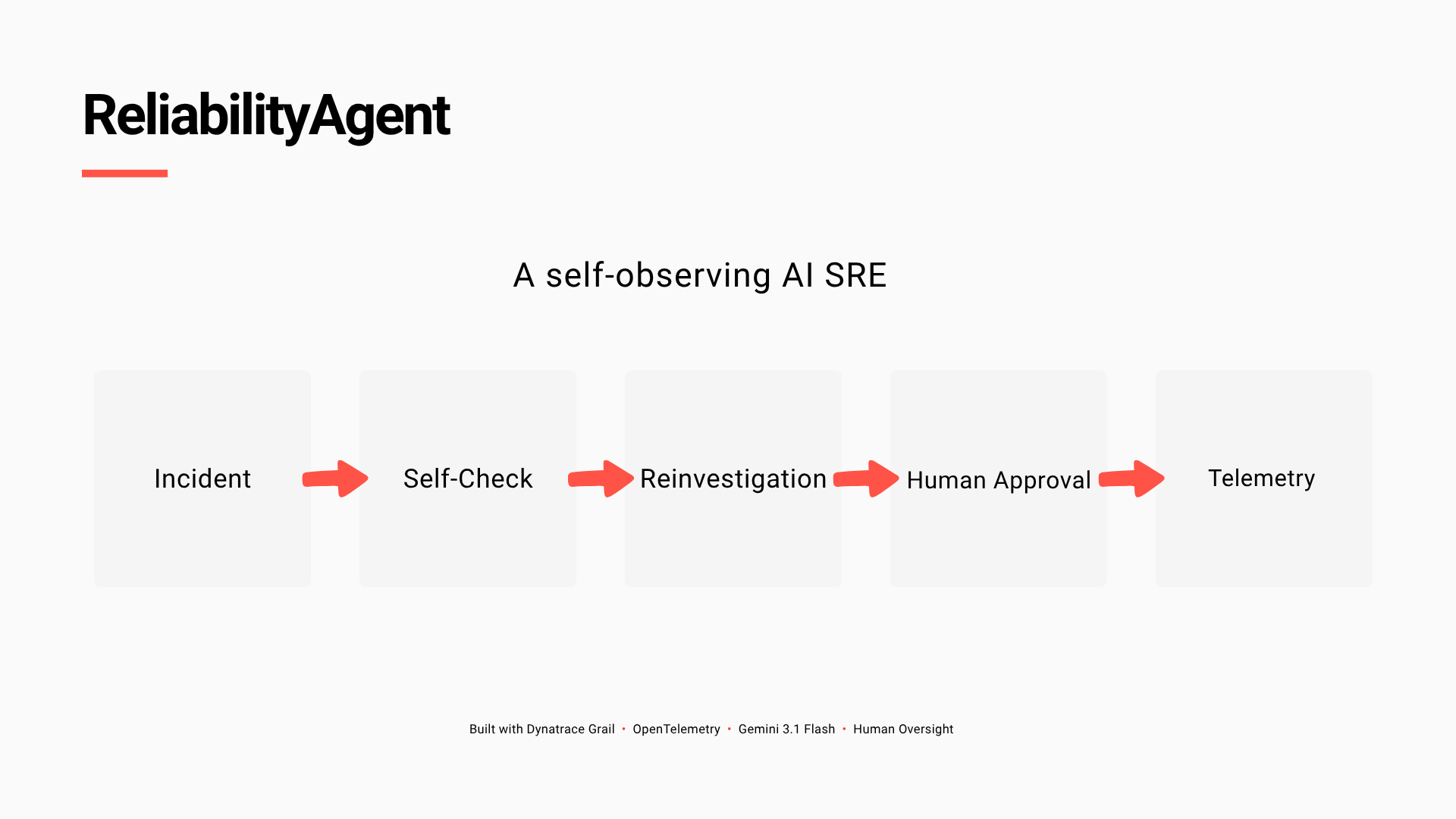
ReliabilityAgent: Incident → Self-Check → Reinvestigation → Human Approval → Telemetry
-
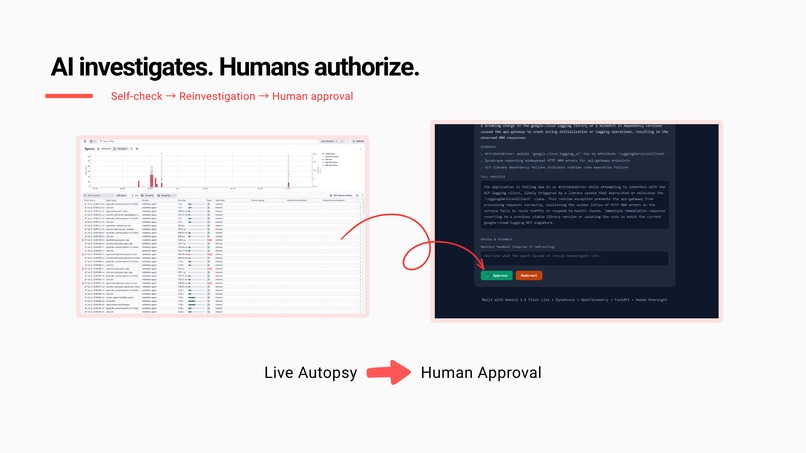
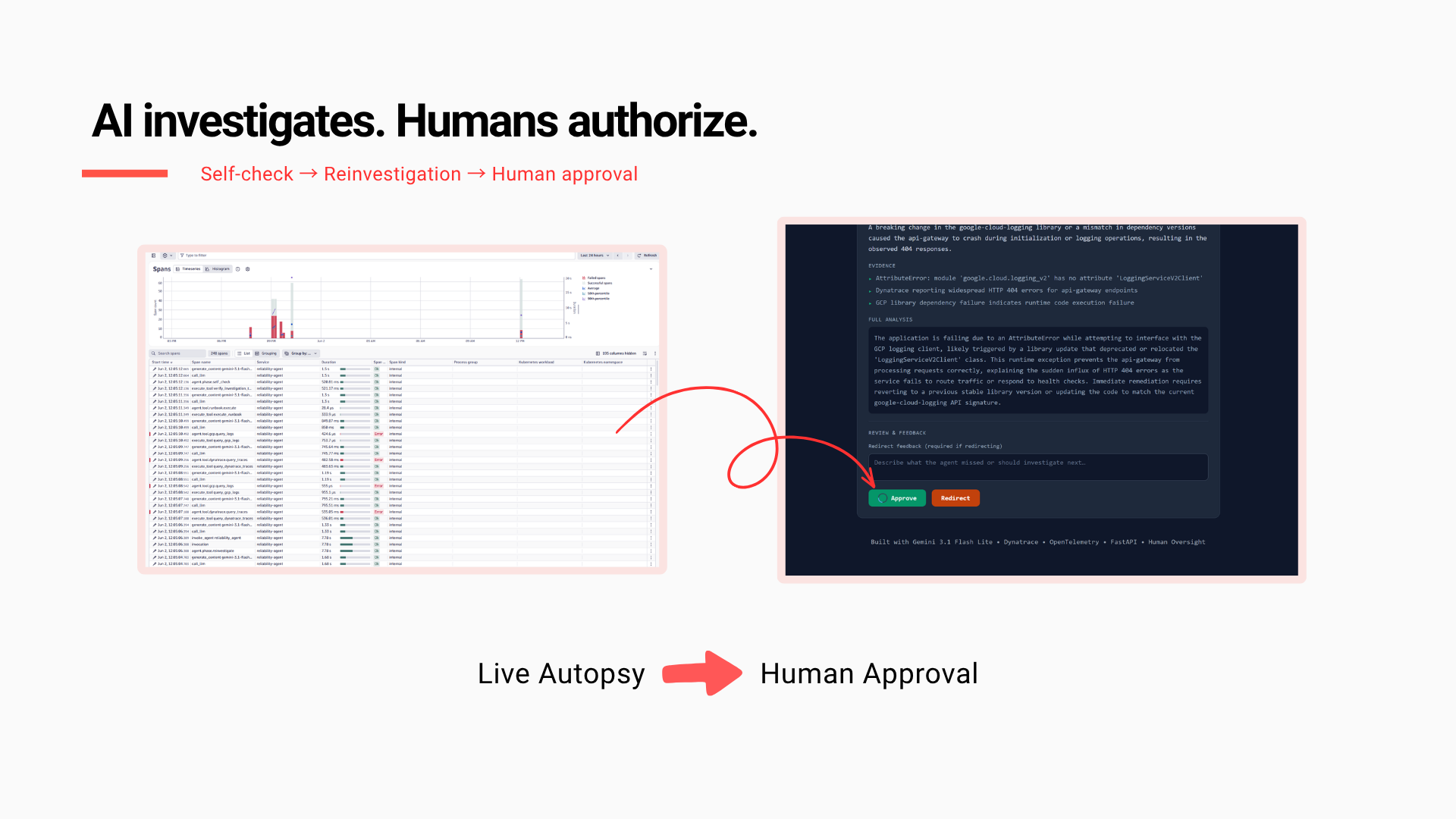
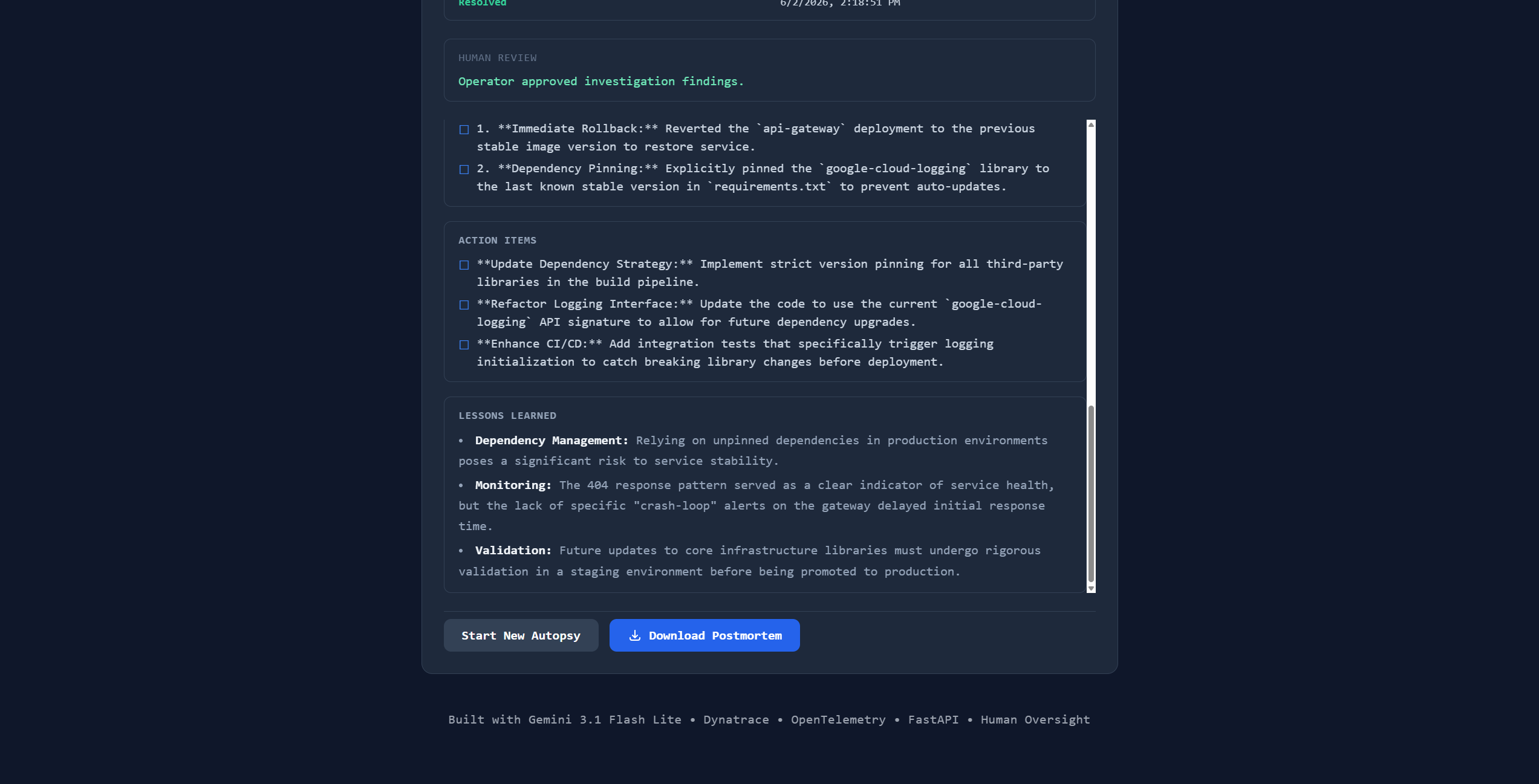
AI investigates. Humans authorize. Every finding is reviewed before action is taken.
-
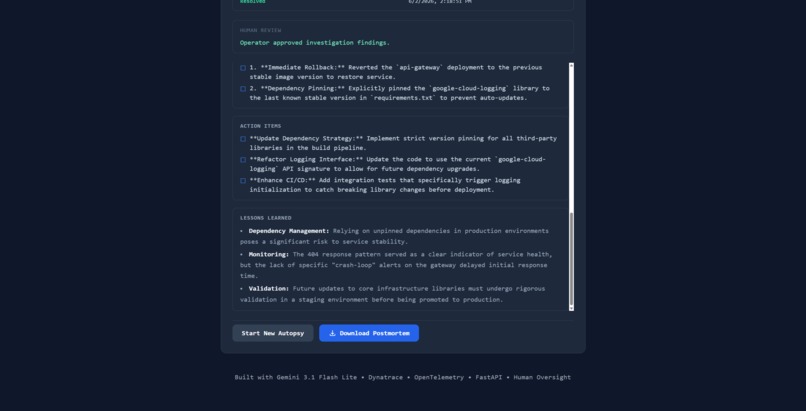
From incident to downloadable postmortem in seconds with root cause and remediation.
-
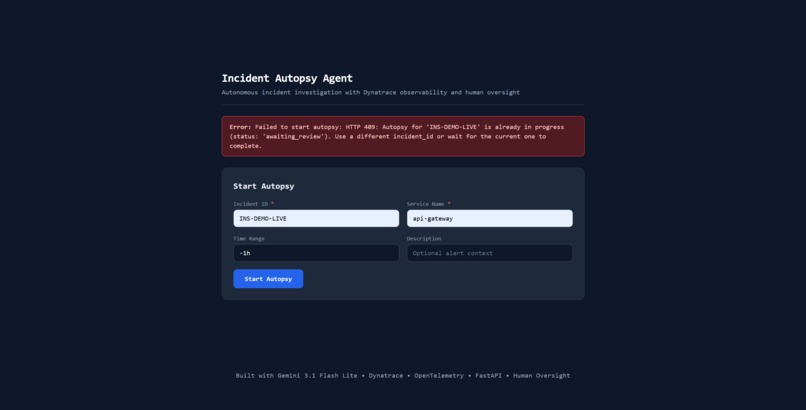
Launch a live incident autopsy powered by Gemini, Dynatrace Grail, and OpenTelemetry.
-
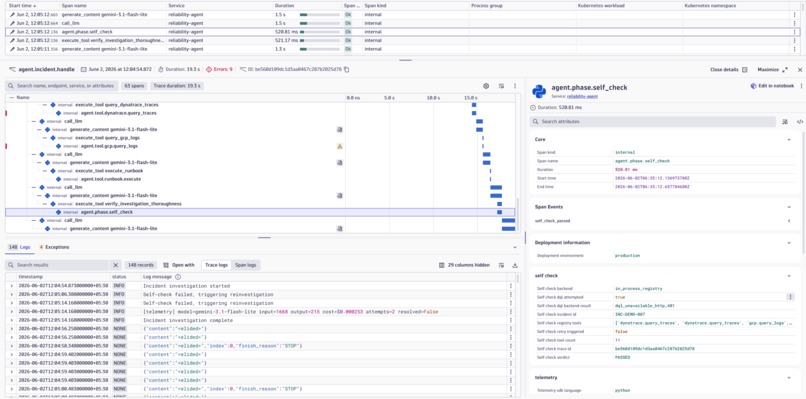
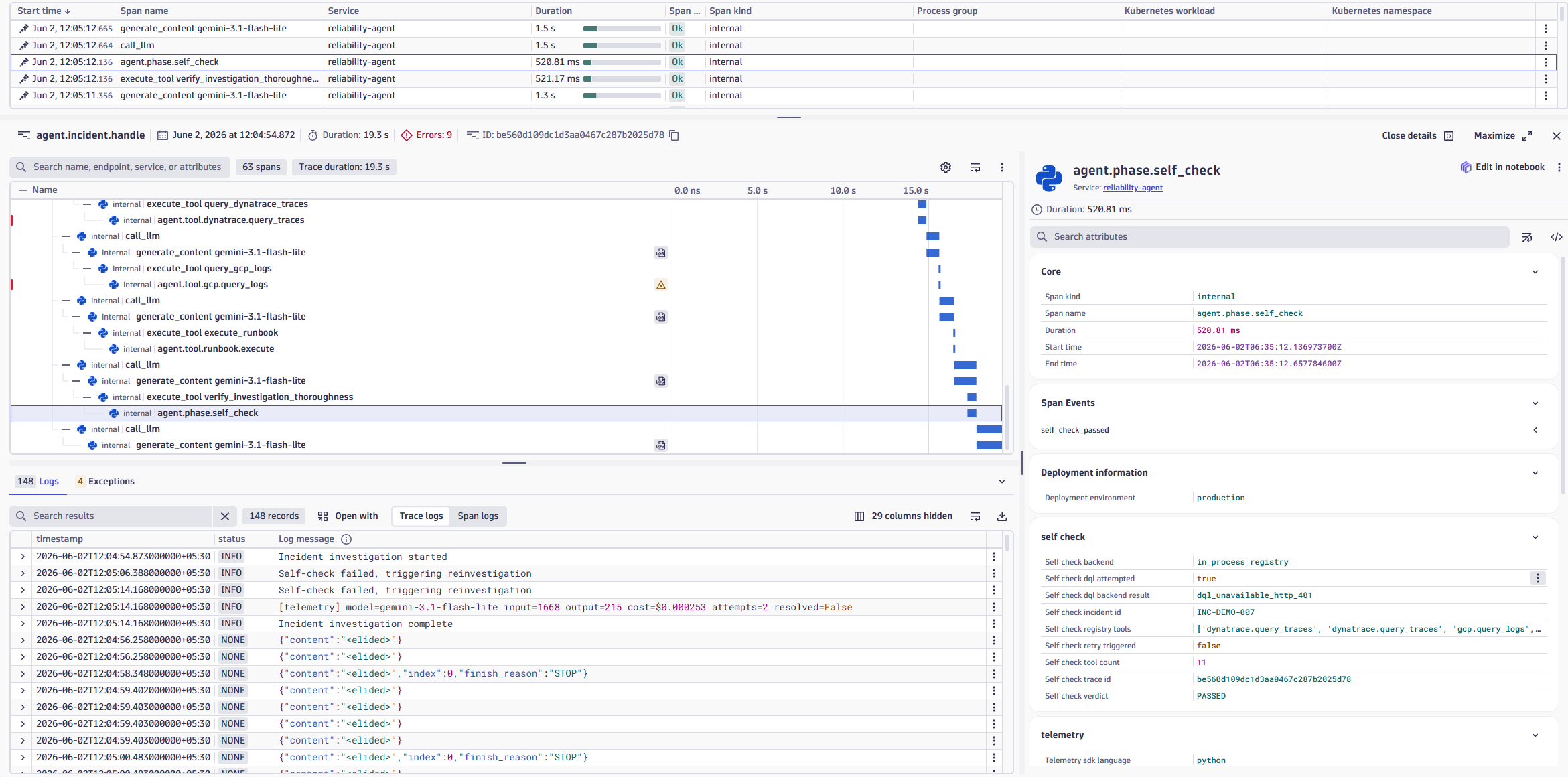
The agent audits its own investigation and records the verdict as Dynatrace telemetry.
-
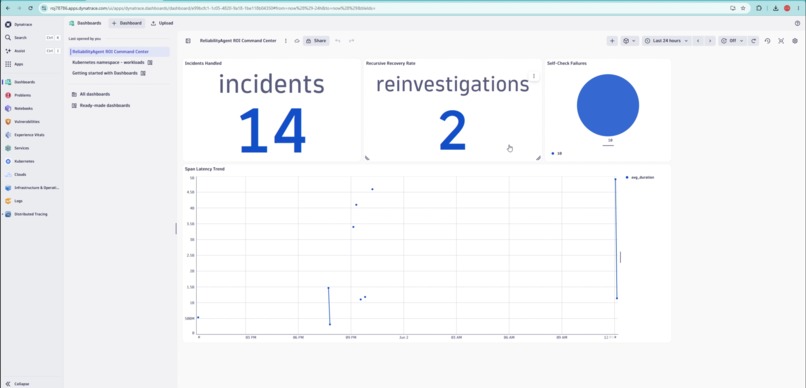
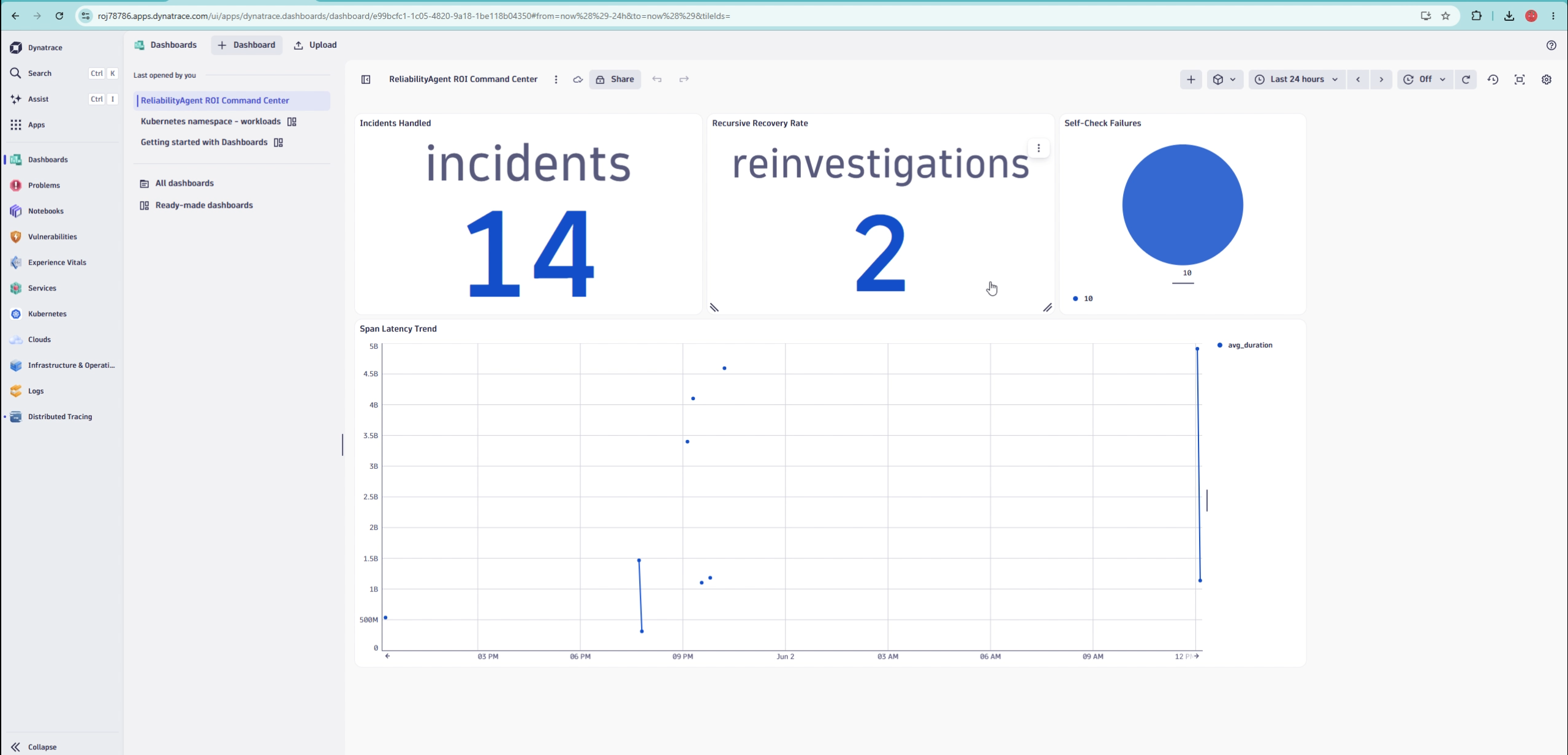
(Dashboard) Not just AI observability. Observability of the AI itself.
Inspiration
Most AI incident-response agents are black boxes. They investigate an incident, return an answer, and ask humans to trust their reasoning. We wanted to build something different. ReliabilityAgent is an AI SRE that makes its own reasoning observable. Every trace query, log query, LLM call, self-check, reinvestigation, and approval is recorded as OpenTelemetry telemetry in Dynatrace Grail.
Our inspiration came from a simple question: What if Dynatrace could monitor the AI agent that is using Dynatrace?
What it does
ReliabilityAgent autonomously investigates production incidents while continuously auditing its own investigation quality.
Workflow : Self-Check → Reinvestigation → Human Approval → Telemetry.
Every trace query, log query, LLM call, self-check, and reinvestigation is recorded as an OpenTelemetry span in Dynatrace Grail.
The agent: Queries Dynatrace traces and logs Collects deployment and operational evidence Uses Gemini 2.5 Flash/3.1 Flash lite to generate hypotheses Performs a deterministic self-check on its own investigation Triggers recursive reinvestigation when evidence is insufficient Requires human approval before generating a post-mortem Records every action as OpenTelemetry spans in Dynatrace Grail
Key results: 248+ real spans recorded 14 investigations completed 2 autonomous reinvestigations triggered Downloadable incident post-mortems Full observability of AI reasoning
Incident
│
▼
Investigation
(query_dynatrace_traces · query_gcp_logs · execute_runbook)
│
▼
Self-Check
(reads own tool-call registry → verdict: PASSED / FAILED)
│
├── PASSED ──────────────────────────┐
│ │
└── FAILED → Reinvestigation │
(corrective prompt + │
new tool calls) │
│ │
└────────────────► ▼
Human Approval
(/autopsy/{id}/feedback)
│
▼
Postmortem
(Gemini-generated, structured)
│
▼
Dynatrace Grail Telemetry
(every span queryable via DQL in real time)
Features
| # | Feature | Why It Matters |
|---|---|---|
| 1 | Recursive self-observability loop | After investigation, the agent queries its own Dynatrace trace to verify it called ≥ 3 distinct tools. Insufficient coverage triggers a full reinvestigation — automatically. |
| 2 | Dynatrace as a cognitive feedback signal | The agent doesn't just emit telemetry to Dynatrace — it reads back from it to govern its own next action. Observability becomes part of the control plane. |
| 3 | Zero mock data, zero fake verdicts | Every tool returns real API responses or honest error structs. self_check.verdict is driven by actual recorded tool calls in an in-process registry — not a counter, flag, or modulo. |
| 4 | Human-in-the-loop autopsy API | /autopsy/start → Gemini gathers evidence → structured hypothesis with confidence score → operator approves or redirects → Gemini writes the postmortem. Every step is an auditable state machine. |
| 5 | Full OTel span hierarchy, importable dashboard | 7 span types, 20+ typed attributes, cost accounting (llm.cost.usd), phase durations, verdict distribution — all queryable via Grail DQL. Dashboard ships as an importable JSON. |
| 6 | Production-grade observability stack | TracerProvider + MeterProvider + LoggerProvider all wired to Dynatrace via OTLP HTTP. Structured logs carry trace_id correlation. Token cost computed per-model and recorded as a span attribute and OTel metric. |
| 7 | Docker + Cloud Run ready | Dockerfile and deploy/gcloud/deploy.sh included. One command deploys to GCP Cloud Run with correct memory, CPU, and timeout settings. |
How we built it
ReliabilityAgent was built using:
Google ADK, Gemini 2.5 Flash/3.1 Flash lite, Dynatrace Grail DQL, OpenTelemetry, FastAPI, MCP Server, Google Cloud Run, Google Secret Manager The most unique component is the self-check engine. Instead of asking another LLM to evaluate the investigation, ReliabilityAgent performs a deterministic audit: Counts investigation tool calls Verifies evidence thresholds Records verdicts as span attributes Triggers reinvestigation when necessary Example span attributes: self_check.verdict = PASSED self_check.tool_count = 11 self_check.backend = in_process_registry self_check.dql_attempted = true These become permanently queryable in Dynatrace Grail.
Challenges we ran into
Real self-checks instead of simulated ones : Early prototypes used synthetic pass/fail logic. We replaced it with real telemetry-driven verification using Dynatrace data and deterministic validation.
Dynatrace observability integration : Getting OpenTelemetry traces, logs, and metrics flowing correctly into Dynatrace Grail required careful configuration and tuning.
Human oversight design : We wanted approval to be meaningful rather than a checkbox. The final Approve/Redirect workflow ensures humans remain accountable for production decisions.
Accomplishments that we're proud of
Our biggest accomplishment is making AI reasoning observable. A judge can open Dynatrace, click a self-check span, and see: Investigation verdict Tool count Verification backend Reinvestigation status Self-check telemetry in real time. ReliabilityAgent doesn't just generate telemetry.
ReliabilityAgent generates telemetry about its own reasoning. We also successfully demonstrated autonomous reinvestigation, where the agent detected weak analysis, restarted its investigation, and produced a stronger result before a human reviewed it.
What we learned
The biggest lesson was that observability should not be added after the AI agent is built. Observability must be part of the architecture from day one.
We also learned that: Human oversight creates trust Graceful degradation is better than hidden failures Deterministic self-checks are more reliable than LLMs grading LLMs Telemetry can become an agent's memory and audit trail
What's next for ReliabilityAgent : AI That Audits Itself
Future versions will include: Native Grail-powered self-verification Confidence scoring as OpenTelemetry metrics Historical incident memory using Dynatrace DQL Expanded MCP integrations Multi-service root cause correlation Autonomous reliability optimization recommendations
Our long-term vision is simple: ReliabilityAgent should not only investigate incidents. It should continuously observe, audit, and improve its own reasoning. ReliabilityAgent - Incident → Self-Check → Reinvestigation → Human Approval → Telemetry.
Built With
- dynatrace-dashboards
- dynatrace-distributed-tracing
- dynatrace-dql
- dynatrace-grail
- fastapi
- gemini-2.5-flash
- gemini-api
- google-adk
- google-cloud-run
- google-secret-manager
- mcp-server
- opentelemetry
- otlp-telemetry-pipeline
- python
- rest-apis

Log in or sign up for Devpost to join the conversation.