-
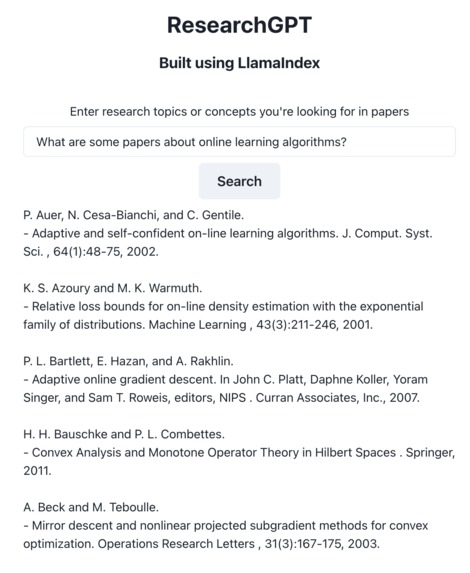
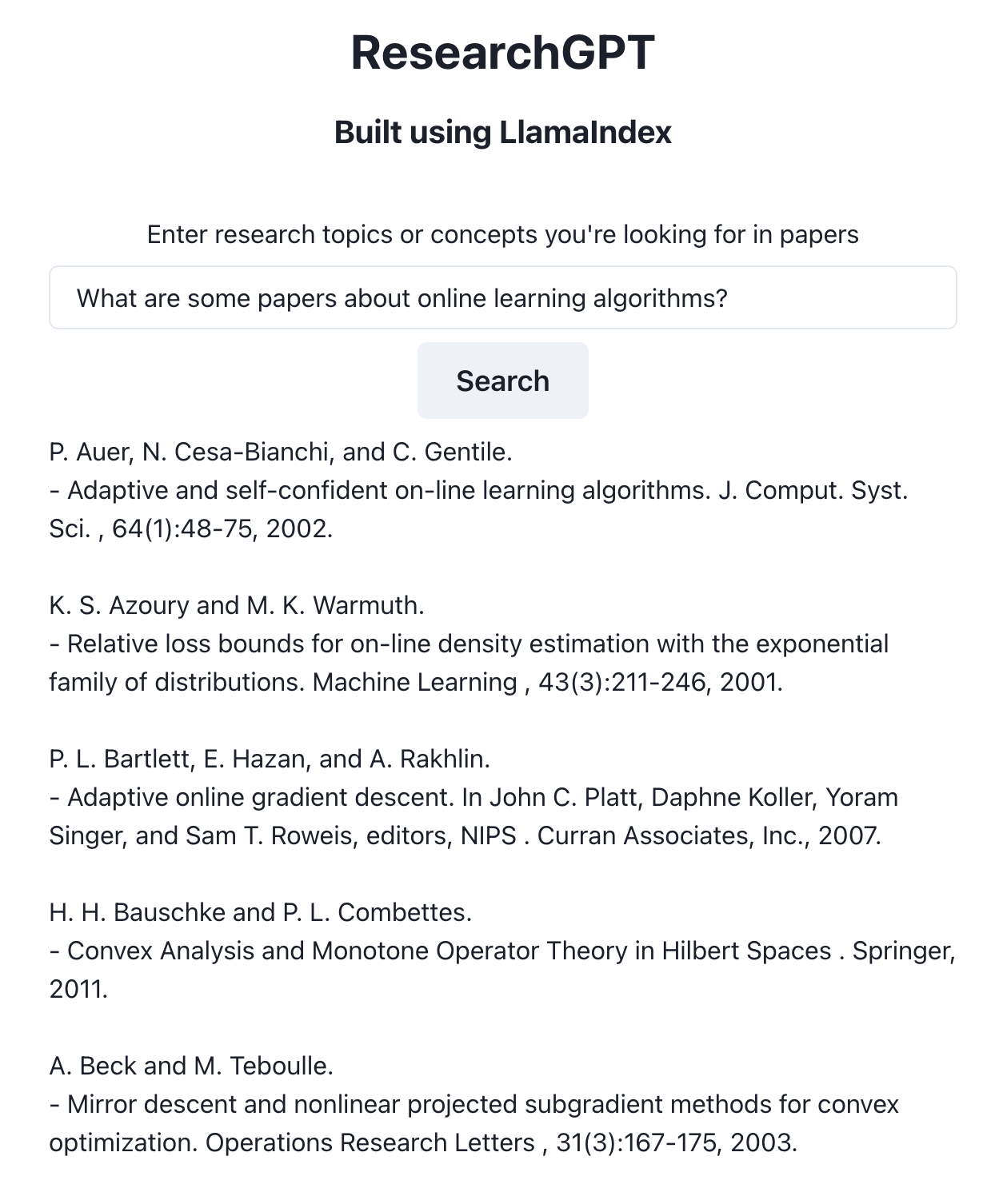
A query where we just want papers.
-

An example of getting information about a topic as well as related papers.
-

A query showing how our product is able to scan the context of papers instead of just keyword searching.


Inspiration
We were inspired by LlamaIndex's ability to efficiently navigate large quantities of texts and files and realized the potential it had in education. So many students and researchers have difficulty finding the appropriate resources to even begin to learn about topics, so we want to greatly simplify and speed-up the education process so more time can be spent learning and not searching.
What it does
Our product takes in any query about a field, such as "What are some papers that can help me understand how I can use reinforcement learning for music?" It then outputs relevant research papers using LlamaIndex and ChatGPT to tailor the papers exactly as per the query request. This would speed up a lot of unnecessary browsing that may pain students and researchers and also quickly finds what would be most helpful. A large problem is that some niche research papers that are brand new may not be found easily, so our product solves that efficiently and effectively for ease of use. ChatGPT currently only has access to data up until 2021 and also there may exist research papers it wasn't specifically trained on, so our model addresses these issues.
How we built it
We pre-downloaded about 1000 research papers from arxiv.org and utilized LlamaIndex to build an index on top of the files to access the most related information intelligently. By using vector embeddings and similarity scores, our model is able to compare hundreds of embeddings of research pdfs with the embedding of our query, reaching a similarity score in order to determine which papers are most relevant. We persisted the index for fast retrieval. Then, using the GPT model we were able to submit queries that would return which research papers were most related to the input. We developed an API to do this as well as a front-end side for users to access.
Challenges we ran into
The biggest challenge we had was the quantity of data that arxiv had and how much we would be able to index and download within a day. Since arxiv has roughly a total of 1.5 TB of research data we decided, for the sake of this prototype, to specify about 1000 important machine learning papers so that we would be able to locally download everything and run it. Ideally, we would spend time preprocessing a lot more data and more consistently to stay up-to-date and speed up any computing time. For the sake of time, we stuck with a smaller subset, but the same code can easily be applied to a much larger dataset by tweaking a few parameters.
Accomplishments that we're proud of
We are very proud of the fact that we were able to quickly pick up on the LlamaIndex library and also implement a solution that would address a big issue that researchers and students have across the globe. By utilizing GPT, the queries can be so precise and the papers we return can be so relevant that the entire process of research and inquiry can be streamlined to a point where browsing online aimlessly becomes obsolete. We made it much faster, more convenient, and more accurate than keyword searching, as our product utilizes large language models to "learn" the paper and address the query based on the content of the paper rather than the keywords of the query.
What we learned
We learned a lot about how the GPT model actually works as well as LLM's. Prior to this hackathon, we had no knowledge about how language models function, and by using LlamaIndex's intuitive library to index over a ton of documents, we figured out how to make our product work.
What's next for ResearchGPT?
We hope to be able to expand our dataset to incorporate more papers and fields from arxiv so that queries about any subject can be answered effectively with much more power and expansiveness. With more subjects, this product will be more useful than ever to researchers and students from any major and field.
Built With
- beautiful-soup
- chatgpt
- fastapi
- langchain
- llamaindex
- python
- react
- requests


Log in or sign up for Devpost to join the conversation.