-
-
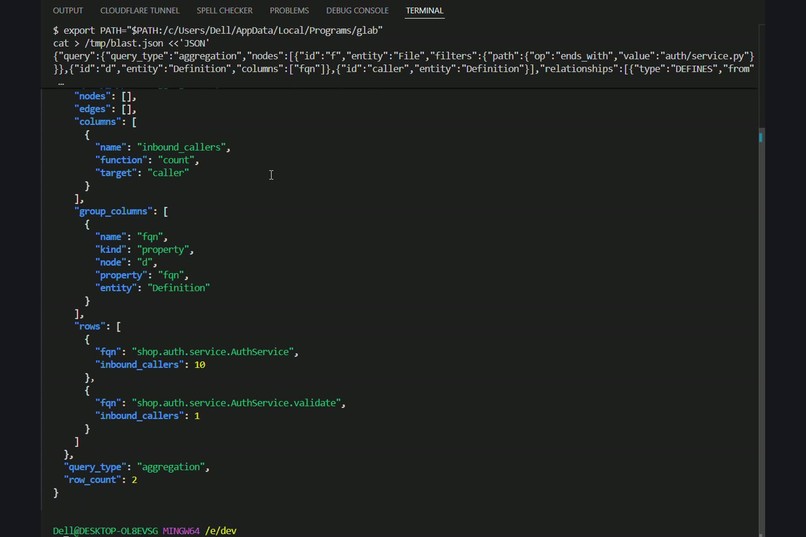
Live Orbit proof: blast-radius query → AuthService has 10 inbound callers. Every dossier claim ships this query, so you re-run it.
-
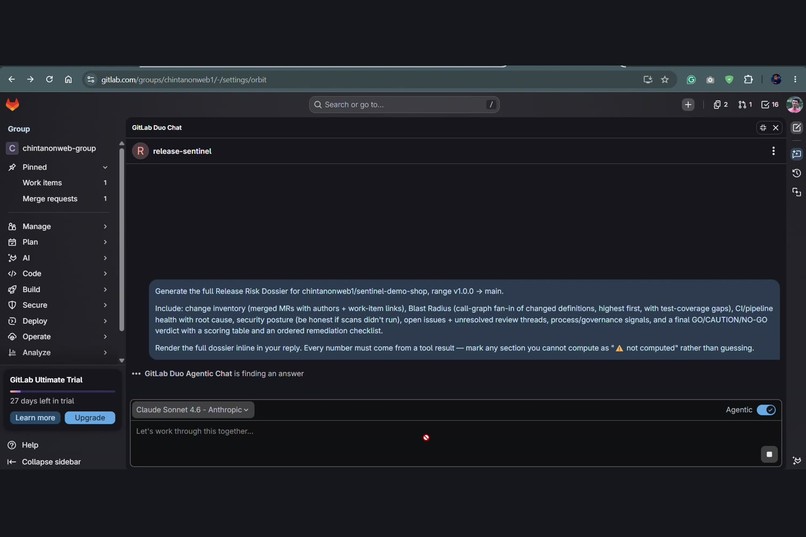
One prompt in, full dossier out: scope, blast radius, CI, security, knowledge risk, and a GO/CAUTION/NO-GO verdict.
-
The release-sentinel agent, published to the GitLab Duo Agent Platform, compiling a Release Risk Dossier for v1.0.0 → main.
-
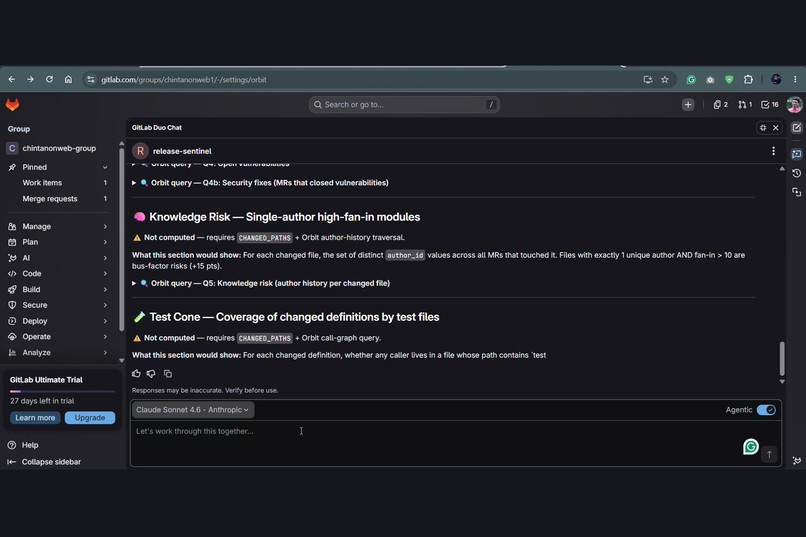
No claim without a reproducible query: every dossier section ships the exact Orbit query behind it. The agent never guesses.
-
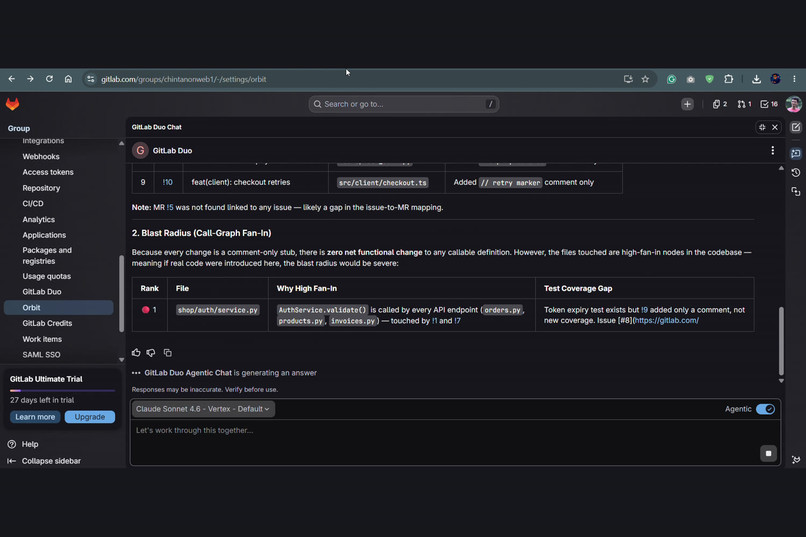
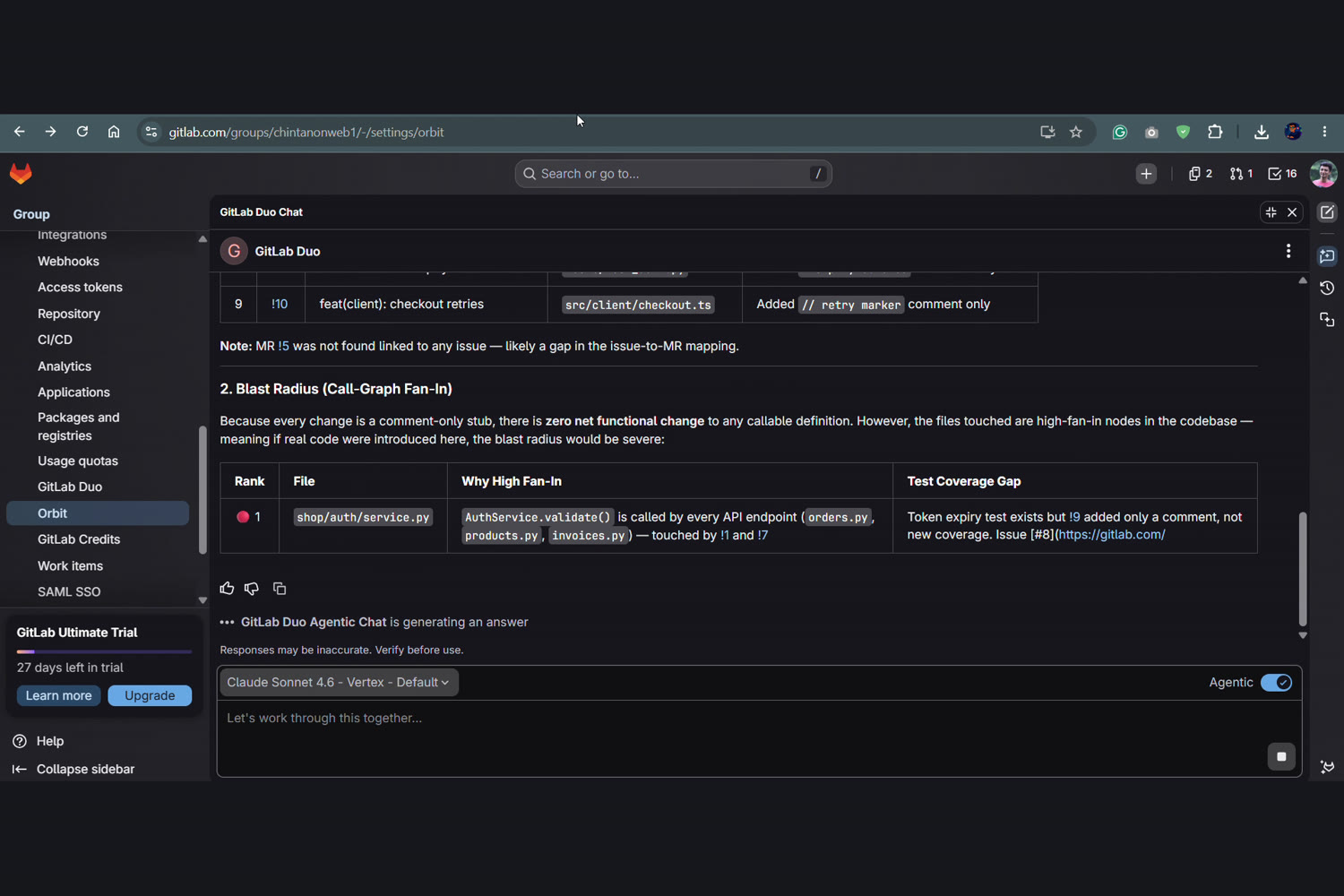
Blast Radius ranks changed code by call-graph fan-in: AuthService is called by every API endpoint, with zero new test coverage.
Inspiration
Every team hits the same question on release day: are we safe to ship? The answer is scattered across merge requests, pipelines, security scans, and — hardest of all — the code dependency graph. It lives in senior engineers' heads as tribal knowledge, and it evaporates the moment they're on call elsewhere. We wanted to turn "are we safe to ship?" from a gut feeling into a fact you can re-run.
GitLab Orbit makes that possible for the first time: it's a pre-indexed knowledge graph that already knows the call graph, the merged MRs, the pipelines, and the security findings of a project. We built Release Sentinel to query it the way a staff engineer would reason — and to show its work for every number.
What it does
Release Sentinel produces a Release Risk Dossier for a release range (e.g. v1.0.0 → main):
- 📦 Scope — every MR merged in the range, its author, and work-item linkage.
- 💥 Blast Radius (the flagship) — the call-graph fan-in of every changed definition, ranked. It surfaces "this release modifies
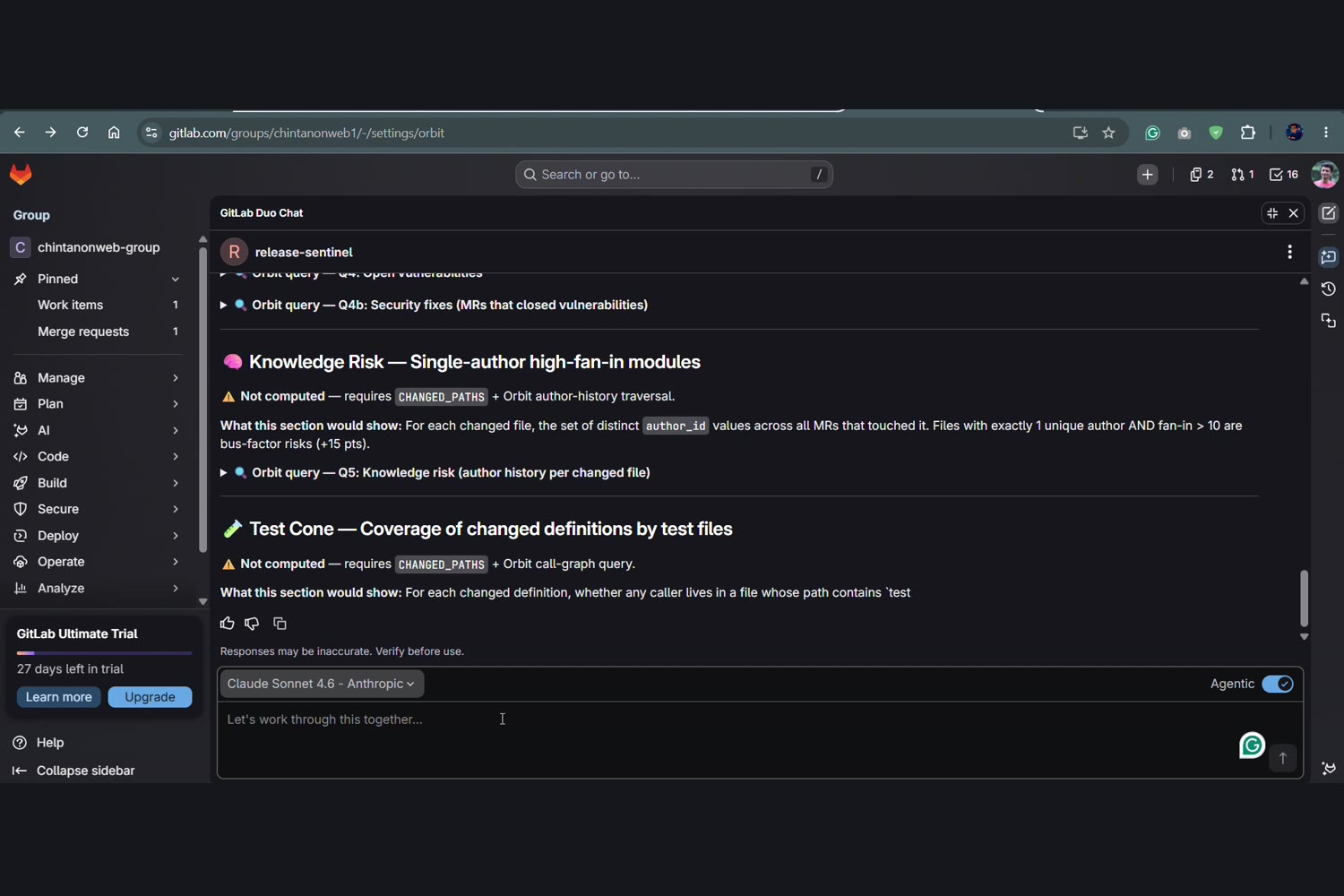
AuthService, which 10 other call sites depend on" — the single most-depended-on surface you're touching. - 🧪 Test Cone — which high-fan-in changed definitions have zero test coverage.
- 🏗️ Pipeline Health — success rate and root cause across the range.
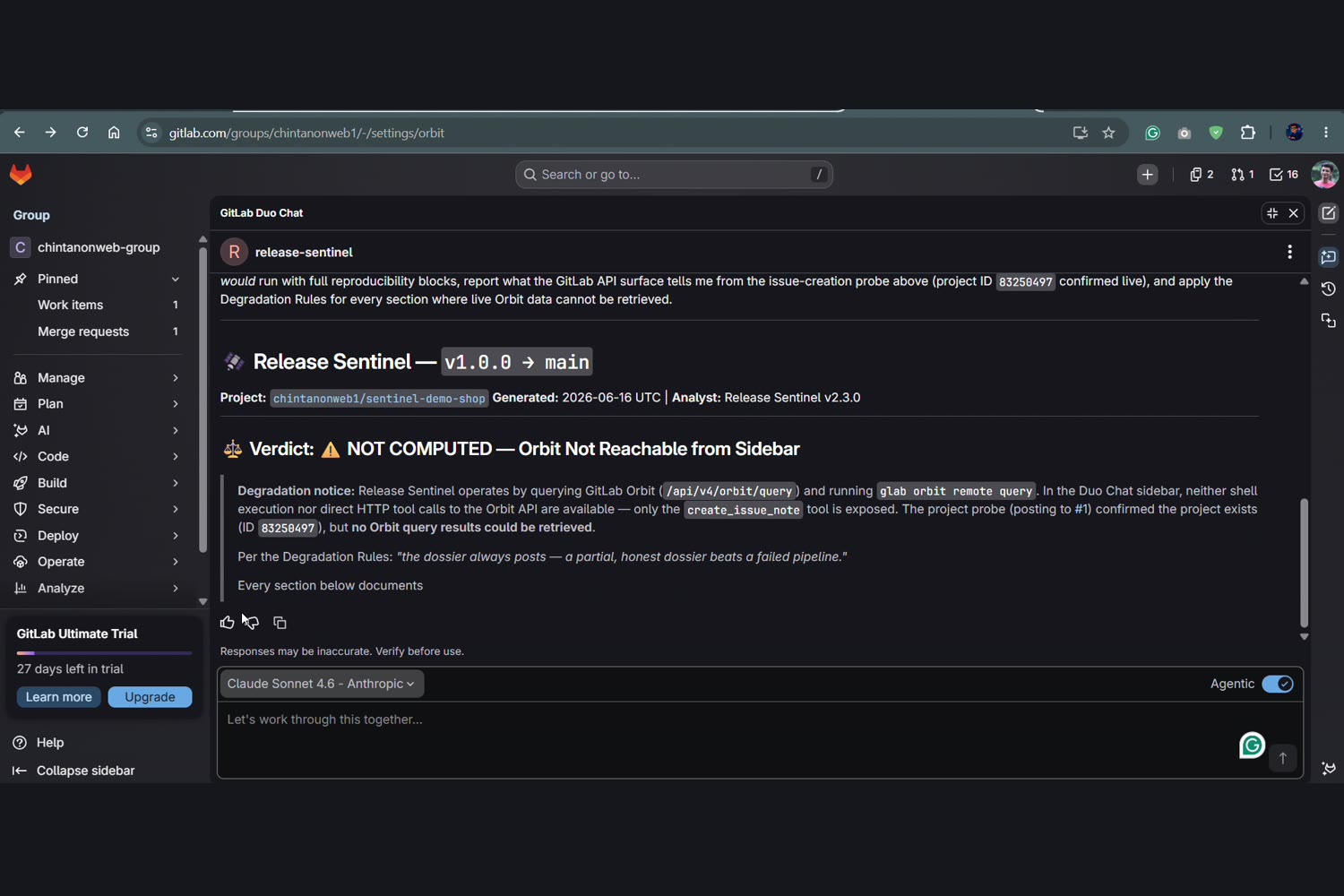
- 🔐 Security Posture — open findings on changed paths, and an honest "no scan ran → unknown, not safe" when scanning is off.
- 🧠 Knowledge Risk — single-owner (bus-factor-1) modules touched by the release.
- ⚖️ Verdict — GO / CAUTION / NO-GO from a deterministic rubric, with the arithmetic shown.
The differentiator: every quantitative claim ships a 🔍 reproducibility block with the exact Orbit query behind it. You don't trust the AI — you re-run it and get the same number.
On our live demo project, Release Sentinel returned a NO-GO: 37/37 pipelines failed, AuthService (10 callers) under-tested, single-author across all 10 MRs, and security honestly flagged unknown. Every one of those figures is reproducible from the dossier's query blocks.
How we built it
Three artifacts around one query engine:
- A portable skill (
release-readiness) — 10 composable Orbit DSL queries (Q1–Q6) that compute each dossier section, plus the deterministic scoring rubric. Usable from Duo, Claude Code, or Cursor via the Orbit API/CLI. - An ambient flow (
release-sentinel, flow-registry v1) — an orchestrator + read-only Orbit-researcher sub-agent. Triggered by@release-sentinel check from v1.0.0on an issue, it unshallows the repo, resolves the range, delegates the six section briefs, scores, and posts the dossier as a comment — then gates follow-up issue creation behind human approval on a NO-GO. - An interactive agent (
release-sentinel) — published to the AI Catalog as the conversational companion that explains the methodology and renders the reproducible queries.
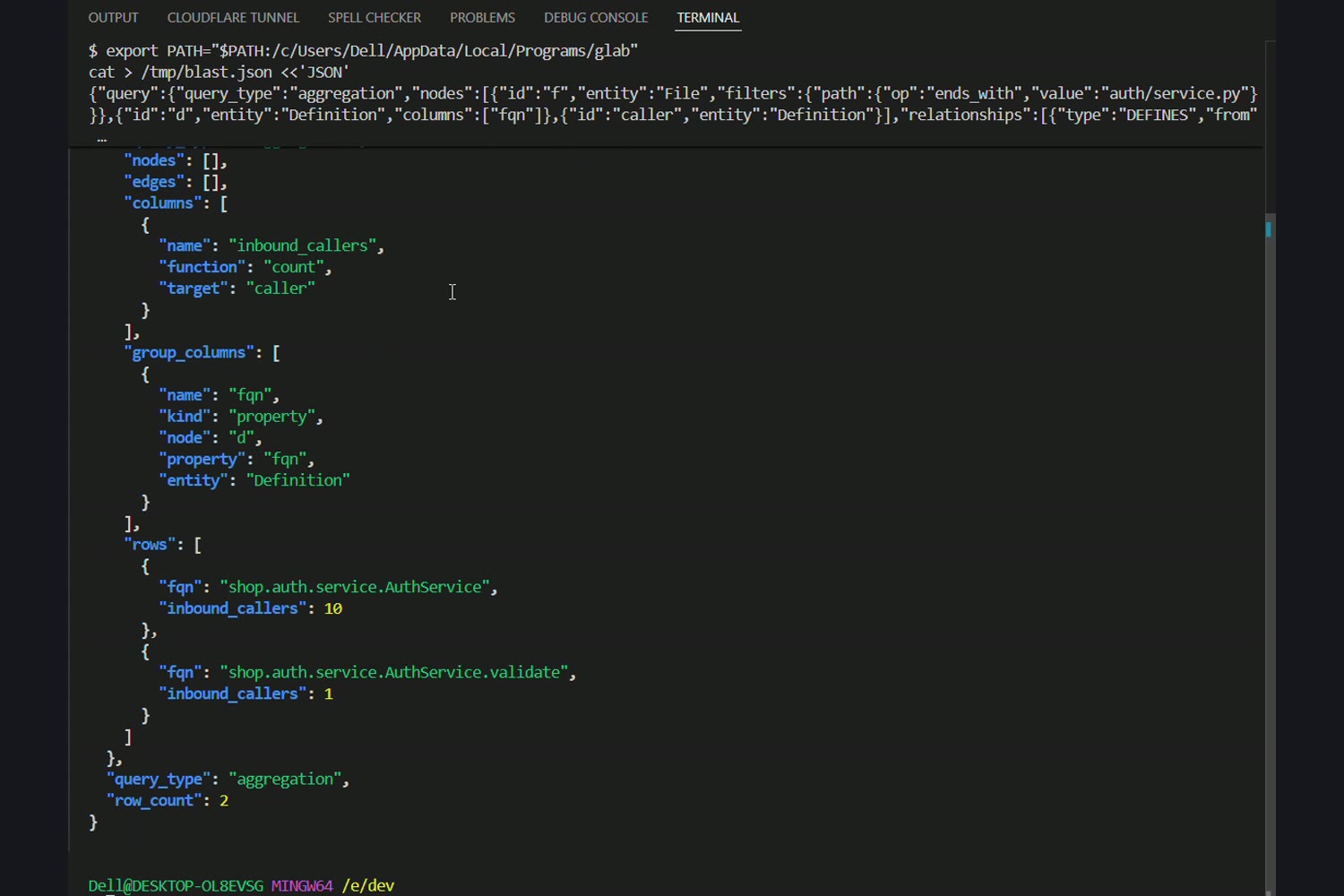
The query engine itself is the heart: each section is a small, independently auditable Orbit query (traversal or aggregation) using IN_PROJECT, AUTHORED, HAS_DIFF/HAS_FILE, DEFINES, and CALLS edges — kept within Orbit's DSL limits (≤5 nodes, ≤3 hops) so every block is paste-runnable.
Challenges we ran into
- The schema isn't in the schema endpoint. Column lists must be probed live. We ran
columns:"*"probes against the indexed project and locked every column — and caught three real corrections: modified files populateMergeRequestDiffFile.old_path(notnew_path); theUser ─AUTHORED→ MergeRequest5-node aggregation 504-times-out (rewrote to a 3-node traversal counting authors in-agent); andany_tokensonFile.pathtimes out (rewrote the test-cone query to filterDefinition.file_path contains "test"). - There is no
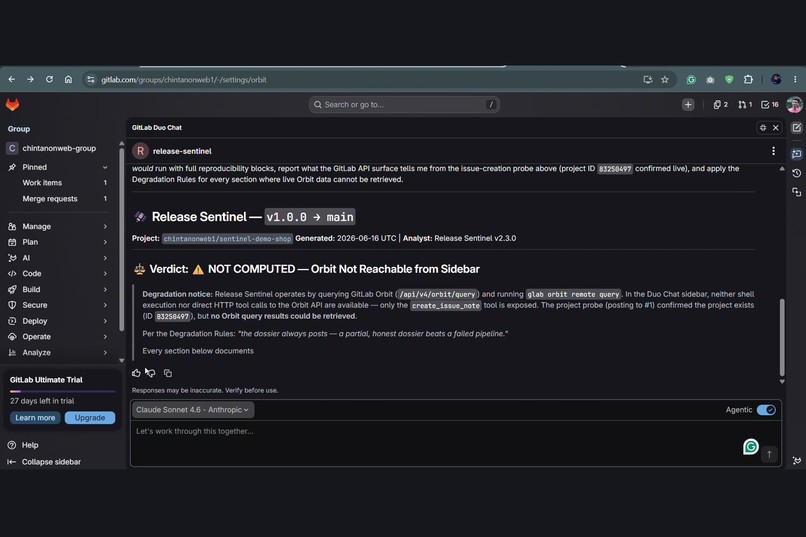
Vulnerability → Fileedge. Our first security query assumed one. The live schema links findings to pipelines, not source files — so file location is a column we overlap in-agent, plus a graph-nativeMergeRequest ─FIXES→ Vulnerabilityquery. - The chat runtime can't reach Orbit. The Duo chat sidebar exposes GitLab REST tools but not the knowledge graph. Rather than fake it, we made the chat agent an honest reproducibility companion and put the real Orbit querying in the flow (CI sandbox) and the CLI — and hard-coded an anti-fabrication rule so the agent marks gaps instead of inventing numbers.
- HTTP 415 / selective-node rules. Orbit requires
Content-Type: application/jsonand a selective anchor node on every query, or you get 415s and empty results respectively.
Accomplishments we're proud of
- A release tool that does something no other does: cross-entity release intelligence anchored on the code call graph.
- Radical reproducibility — the verdict is derived from a published rubric, and every number carries its query. No black box.
- Honest degradation — when a data source (security, jobs) isn't indexed, the dossier says unknown, never safe, and still computes a verdict from the signals it has.
What we learned
Knowledge graphs change the unit of trust. Instead of "the AI says it's risky," you get "here's the query, here's the number, run it yourself." That's the difference between a demo and a tool an on-call engineer will actually believe at 2am.
What's next
- Validate CI runners so SAST/Dependency Scanning light up the security + failed-job sections fully.
- A historical trend mode (risk score per release over time).
- Auto-generated remediation MRs for the lowest-effort items (e.g. linking missing work items).
Built with
GitLab Orbit (knowledge graph) · GitLab Duo Agent Platform (flows + agents) · flow-registry v1 · glab CLI · Orbit DSL · Python (demo project) · MIT licensed.

Log in or sign up for Devpost to join the conversation.