-
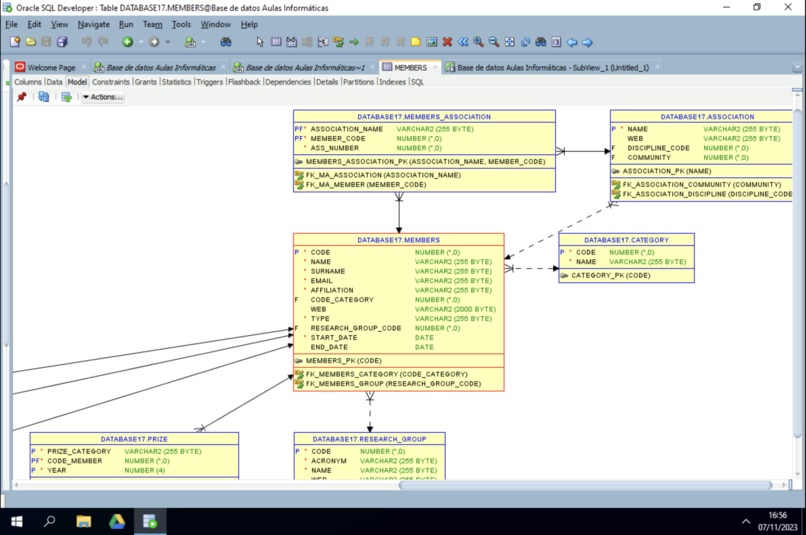
A visual peek into how members (the central attribute) related to most other tables.
-
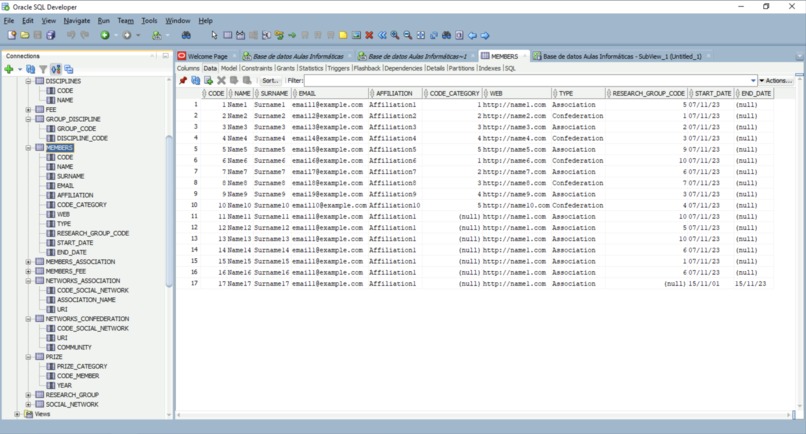
An example of the MEMBERS table with sample data.


Inspiration
Our project was directly developed according to a project outline provided in our Relational Databases course. The project follows a hypothetical "Scientific Confederation" that brings together scientific associations which contain members who contribute to associations, research groups and so on.
What it does
Our relational database represents in its entirety the proposed Scientific Confederation, and allows users to input, modify and delete associations, research groups, members, and all other information.
Each association has a name, perhaps a website, and a discipline to which it belongs. Additionally, the confederation and each association have a board of directors (president, vice president, secretary and treasurer), as well as social network(s). There are also research groups that fall under certain disciplines (software engineering, AI, security, systems architecture, etc). All members belong to the confederation, but not inherently to any association or research group. Information about each member was categorized and organized using foreign keys, so that an individual may be located through an association and vice versa. Aside from basic information (name, surname, member code), additional information about members such as personal websites, employment, retirement dates, member fee payment history and awarded prize history was related and stored.
Our database allows users to insert, modify and delete associations, research groups, disciplines, members and all other related tables whilst adhering to delete/update cascade and insertion constraints. We also developed queries to relay basic information about the data base, such as "returning the name of the associations, the year and the sum of dues for each year paid by their members, sorting the result by association name in alphabetical descending order." Triggers to maintain the integrity of the confederation were likewise implemented. One such trigger stated, "When associating a researcher to a research group, check that at least one association to which the researcher belongs has at least a discipline in common."
How we built it
We first designed a visual schema that represented the database in its entirety. This gave us a clear picture of where to start, and where to end. In this sense, we were guided by foreign key relations. Members, for instance, had the most foreign keys in other tables, so in order to create those tables, it was ideal to begin there. Afterwards, minor tables such as MEMBERSHIP_PAYMENTS which didn't host foreign keys in other tables were incorporated.
For the architectural implementation of the database in MySQL, our workflow proceeded as creating: tables, foreign keys, triggers, queries , inserting/modifying data, and dropping tables to ensure they could be deleted.
Challenges we ran into
One of our biggest challenges was determining how to implement logical constraints (delete/update options and triggers) into code. Leaning on our trigger from earlier, when deciding how to ensure a researcher could be added to a research group, we had to check common disciplines among any association to which they belonged, and the group to which are intending to add them. We had to think about how our associations were related to the disciplines column, which was not directly, but rather through an external table called GROUP_RESEARCH related to MEMBERS. Likewise, there were external cases to consider, such as members who did not belong to any consideration, or were retired.
Another hurdle was figuring out the order in which to create tables and assign foreign keys. Of course, we couldn't create tables which included keys yet to exist. So we had to carefully analyze our schema and go table by table, starting with tables that incorporated few or none foreign keys, finalizing with tables which included all possible combinations (paths from one table to another) of foreign keys required.
Accomplishments that I'm proud of
I'm most proud of our ability to communicate and resolve both logical and semantic issues within the database in a constructive way that helped us deepen our understanding of the task at hand. This consistent back and forth feedback on our contributions to the project is what fueled a smooth and consistent development process.
What I learned
Through this project, I learned how to first conceptualize a relational database from the ground up, by creating a visual schema and dictating semantic/logical assumptions. I then learned how to build such a database from scratch in MySQL (Oracle SQL Developer) and follow a workflow that maximized efficiency and consistent development. On top of this, I learned how to design different aspects of a database (and debug) while collaborating with a partner so that our individual segments would connect seamlessly in the final product.

Log in or sign up for Devpost to join the conversation.