-
-
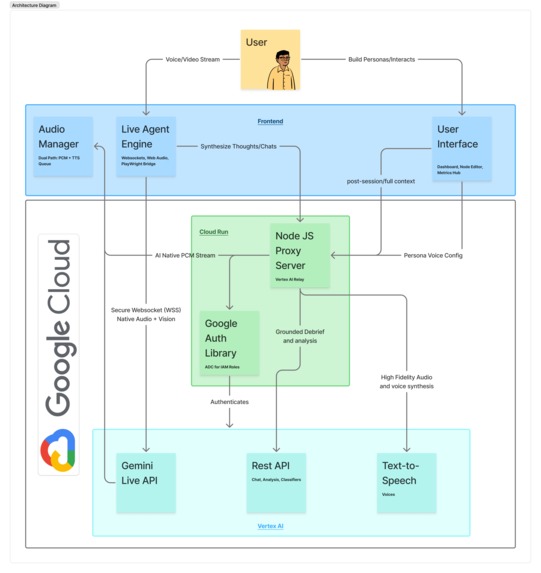
Architecture Diagram
Building Rekvin: From Static Personas to Autonomous UX Agents
Inspiration
The idea for Rekvin was born out of a frustration that every UX researcher quietly carries: personas are fiction dressed up as data.
We've all seen them — the laminated "User Archetypes" pinned to the wall in a product team's office. "Meet Sarah, 34, a busy mom who loves simplicity." They're carefully crafted, thoughtfully designed, and almost entirely useless by the time a real product decision needs to be made. Why? Because Sarah never actually does anything. She just stares at you from the wall.
The question that haunted me was deceptively simple:
What if your personas could move?
Not metaphorically. Literally move — navigate your app, encounter friction, get confused, give up, succeed — and then tell you exactly why.
Modern multimodal AI, specifically Google's Gemini Live API with real-time vision and audio, made this question answerable for the first time. The timing felt like a gift. I set out to build Rekvin.
What I Learned
1. Personas Are Prompt Engineering in Disguise
The most surprising realization was that building a believable synthetic user is fundamentally a structured prompting problem. A persona with vague traits like "tech-savvy" produces an agent that behaves erratically and hallucinates plausible-but-wrong behavior. A persona grounded in specific, connected evidence — real quotes, research findings, explicit tensions — produces an agent that is measurably more consistent.
This led directly to the Quality Score system, where I formalized this intuition into a heuristic. If we define a persona's grounding evidence as a set of nodes $E = {e_1, e_2, \ldots, e_n}$, the quality score $Q$ is roughly:
$$Q = w_c \cdot \text{Coverage}(E) + w_d \cdot \text{Diversity}(E) + w_s \cdot \text{Specificity}(E)$$
where $w_c + w_d + w_s = 1$ are weights tuned empirically, and each sub-score is normalized to $[0, 100]$.
A score below ~40 is a genuine warning signal — the agent will drift.
2. Real-Time Vision Is a Different Paradigm
I had built LLM-powered tools before, but I had never worked with a model that was continuously watching. Streaming the browser viewport at 1 FPS and having Gemini process it as a live stream — rather than a series of static screenshots passed to a chat model — changes everything about how you design the interaction loop.
Static polling architectures ask: "What does the UI look like right now?" Live vision architectures ask: "What is happening to the UI over time?"
The difference is enormous. Animations, loading states, hover effects, toast notifications — none of these are visible in a single frame. The live stream captures them all.
3. Audio Is Harder Than It Looks
Getting gapless, low-latency audio from raw 24kHz PCM chunks turned out to be one of the most technically demanding parts of the project. The Web Audio API's AudioContext is powerful, but scheduling buffer chunks requires careful handling of timing drift. If the gap between scheduled buffers is even a few milliseconds too large, you get an audible click. Too small, and chunks overlap.
The final solution was a hybrid queue: prefer the raw PCM stream from Vertex AI during live sessions (lowest latency), but fall back to a Gemini TTS queuing system for narration, thoughts, and post-session chat (highest reliability).
4. Calibration Is a Research Tool, Not Just a Feature
Post-test behavioral validation — comparing what the agent said it was doing versus what the metrics showed it actually did — turned out to be more valuable than I initially expected. It's not just a sanity check on the agent. It's a sanity check on the persona itself. If an agent with "High Tech Literacy" consistently fails at basic navigation, that's signal: either the UI has a real problem, or the persona's assumptions were wrong.
This duality — using the agent to test the UI and using the UI results to test the agent — was an emergent property I hadn't fully anticipated when I started.
How I Built It
Rekvin is structured as two tightly coupled systems: a visual canvas for persona construction and a live testing engine for autonomous deployment.
The Visual Canvas
The canvas is built on @xyflow/react (React Flow v12), which handles the node graph rendering and edge connections. Each node type — Persona, Research, Assumption, Tension, Idea, Session, Metric — has a specific role in the evidence graph.
When a Persona node is "compiled," the engine traverses the graph, collects all connected evidence nodes, and synthesizes them into a structured prompt using gemini-2.5-pro. The output is a rich cognitive profile that includes:
- Synthesized core insights
- Extracted behavioral metadata (Tech Literacy, Patience, Primary Device)
- A computed Quality Score based on the evidence graph topology
The Testing Engine
The backend is a Node.js / Express server that acts as a secure Vertex AI proxy. It uses google-auth-library with Application Default Credentials (ADC) to authenticate with the Vertex AI Live API, which means no API keys are ever exposed to the frontend.
The testing loop looks roughly like this:
┌─────────────────────────────────────────────────────┐
│ Agent Loop │
│ │
│ Browser (Playwright) │
│ │ │
│ ├─ Captures viewport frame @ 1fps │
│ │ │
│ ▼ │
│ Vertex AI Live API (gemini-live-2.5-flash) │
│ │ ← streams vision + audio │
│ │ → emits function calls + narration │
│ │ │
│ ▼ │
│ Tool Executor (Playwright) │
│ │ click / type / scroll / wait │
│ │ │
│ ▼ │
│ Session Log (breadcrumbs + metrics) │
└─────────────────────────────────────────────────────┘
When a user speaks via microphone, the voice stream is injected into the same Gemini Live session alongside the vision stream. The agent processes all three streams — vision, user audio, and its own output audio — simultaneously, which enables true barge-in support.
The Metrics Hub
Post-session analysis runs on gemini-2.5-pro, which receives the full session breadcrumb log and produces structured metric outputs:
- Time-to-Completion ($T_c$): measured in seconds from session start to goal achievement
- Comprehension Risk ($R_c \in [0, 1]$): a normalized score reflecting moments of apparent confusion
- Dead-end Encounters ($D$): count of navigation dead-ends encountered
Each metric is accompanied by a structured Verdict — an AI-generated expert analysis that ties the metric value back to the specific behavioral traits of the persona that encountered it.
Deployment
The entire application runs on Google Cloud Run with session-affinity enabled. This is critical — the Vertex AI Live API maintains a persistent WebSocket connection for the duration of a test session, and without session-affinity, a load balancer could route mid-session requests to a different instance, severing the connection.
The Docker image is built via gcloud builds submit and deployed with:
gcloud run deploy rekvin-engine \
--image gcr.io/[PROJECT_ID]/rekvin-engine \
--platform managed \
--allow-unauthenticated \
--session-affinity \
--memory 1Gi
Challenges
Challenge 1: Cognitive Context Injection
The Gemini Live API maintains a continuous session, but it doesn't automatically "remember" what happened earlier in a long test. Early versions of the agent would answer questions like "Why did you click that?" with generic responses disconnected from actual session events.
The solution was Cognitive Context Injection: before processing any user turn, the engine automatically prepends a summary of the current Session Log. This is invisible to the user but gives the agent perfect short-term recall.
The tricky part was managing context window size. A long session produces a large log, and injecting the entire thing on every turn is wasteful and eventually hits limits. The final implementation uses a sliding window: the last $k$ events plus any events flagged as "high-signal" (errors, dead-ends, explicit metric triggers).
Challenge 2: Voice Identity Consistency
Giving each persona a consistent voice was more nuanced than just picking a TTS voice. The same Gemini TTS voice sounds very different depending on the style prompt passed to it. I needed the voice to match the persona's personality — a "Skeptical Senior Engineer" should not sound chipper.
The solution was to pass the persona's full description as a Style Prompt to the TTS API. This uses Gemini's instruction-following capability to modulate the tone, cadence, and affect of the output voice — not just the words, but how they're said.
Gender detection for voice assignment was handled by a lightweight AI classifier that reads the persona's name and description and outputs one of three categories: male, female, or neutral, mapping to Charon, Aoede, and Puck voices respectively.
Challenge 3: The "Hallucination Floor"
Every synthetic agent has a hallucination floor — a minimum rate at which it will produce plausible-but-wrong behavior regardless of how well-grounded the persona is. For UX research, this is a real problem: if a researcher can't distinguish authentic confusion from model noise, the results are compromised.
My partial solution was the Expectation vs. Reality comparison in the Metrics Hub. By comparing the agent's narrated intent with the objective technical outcomes, researchers can flag discrepancies that might indicate hallucinated behavior rather than genuine UX friction.
Fully solving the hallucination floor is an open problem. What I built is a tool for detecting it, not eliminating it.
Challenge 4: Building on a GA API That Was Still Evolving
The gemini-live-2.5-flash-native-audio model reached GA status relatively recently, and working with it during development meant navigating a moving target. API behaviors, latency characteristics, and function calling reliability all shifted between versions.
The most resilient architectural decision I made was keeping the Node.js proxy layer thin and stateless — all session state lives in the frontend and is re-injected on each turn. This made it much easier to swap out model versions and adapt to API changes without rewriting the core loop.
What's Next
Rekvin in its current form is a proof of concept for a new category of research tool. The next directions I'm most excited about:
- Multi-agent comparative testing — running the same test with five different personas simultaneously and comparing their behavioral divergence
- Longitudinal persona drift detection — tracking whether a persona's behavior changes as its Quality Score improves through iterative calibration
- Integration with real user session recordings — using actual session data to ground-truth the synthetic agent's behavior and close the feedback loop between synthetic and real UX research
The wall persona is dead. Long live the autonomous one.
Built for the Google Cloud Gemini Live Hackathon. Powered by Vertex AI Gemini, Playwright, React Flow, and a lot of late nights.
Built With
- ai
- cloud-build
- cloud-run
- docker
- express.js
- framer-motion
- gemini
- google-auth
- javascript
- node.js
- playwright
- react
- rest
- tailwind
- tts
- typescript
- vertex
- vite
- webaudio
- webrtc
- websocket
- xyflow

Log in or sign up for Devpost to join the conversation.