-
-
Workflow 3
-
Workflow 2
-
Workflow 1
-

Human Review Box Part 1
-

Human Review Box Part 2
-
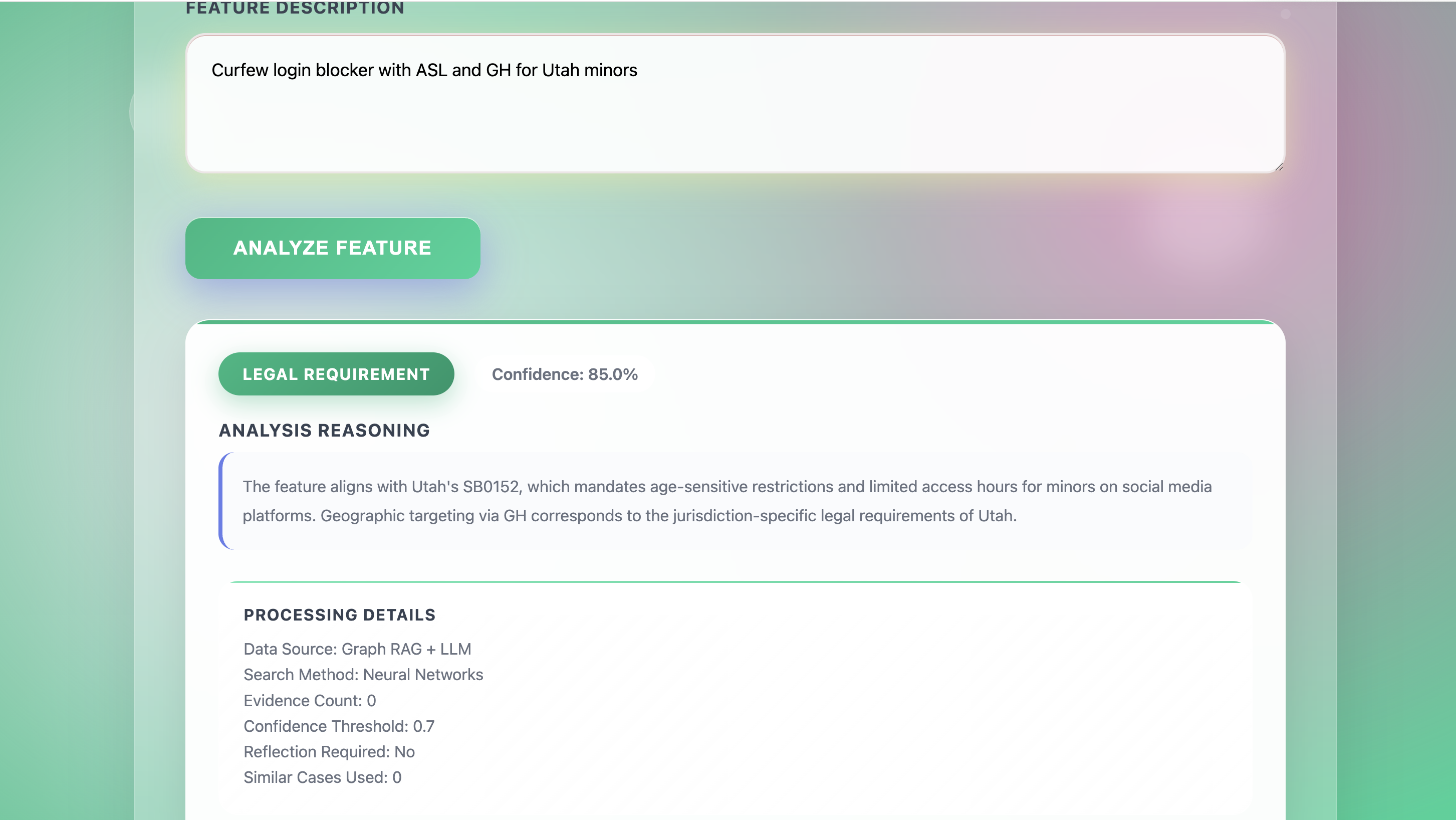
Typical Result
-
Interface


Story: Automated Geo-Compliance Detection and Intelligent Decision System
Inspiration
This project was inspired by the global compliance challenge faced by platforms like TikTok. Every product feature rolled out worldwide must adhere to different legal frameworks—ranging from Brazil’s strict data localization rules to the European Union’s GDPR.
In practice, this meant engineering teams were often left guessing:
- Does this feature offenc region-specific act?
- How many features are already compliant with a given act?
The lack of an automated compliance lens created three risks:
- Legal exposure due to missed obligations.
- Reactive firefighting when regulators or auditors raised issues.
- Scaling pain as manual reviews slowed global rollouts.
We were inspired to reimagine compliance review as not just a legal bottleneck, but as an intelligent, traceable, and auditable AI-driven process. The idea was to simulate an expert team’s decision-making flow through multi-agent collaboration and graph retrieval-augmented generation (RAG).
What it does
The system is a multi-layer AI platform that automatically determines whether a new feature requires geo-specific compliance logic.
Key functions include:
Knowledge-Graph Pre-Indexing for Statutes
- First-800-word snapshot: For each statute in .txt format, extract the first ~800 words so the LLM can infer whether a parent node exists, the jurisdiction (country/state), and the statute citation/identifier.
- More accurate nodes: These inferences enable the knowledge base to auto-generate precise graph nodes.
Automatic Text Cleanup & Chunking
- Normalization: Because raw .txt statutes are often messy, the system auto-cleans them (broken lines, hyphenation, headers/footers, OCR artifacts).
- Better retrieval: After cleaning, documents are chunked, significantly improving downstream retrieval precision.
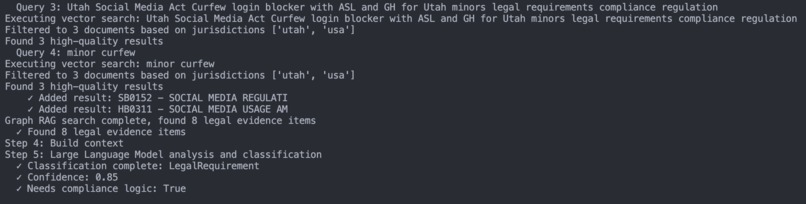
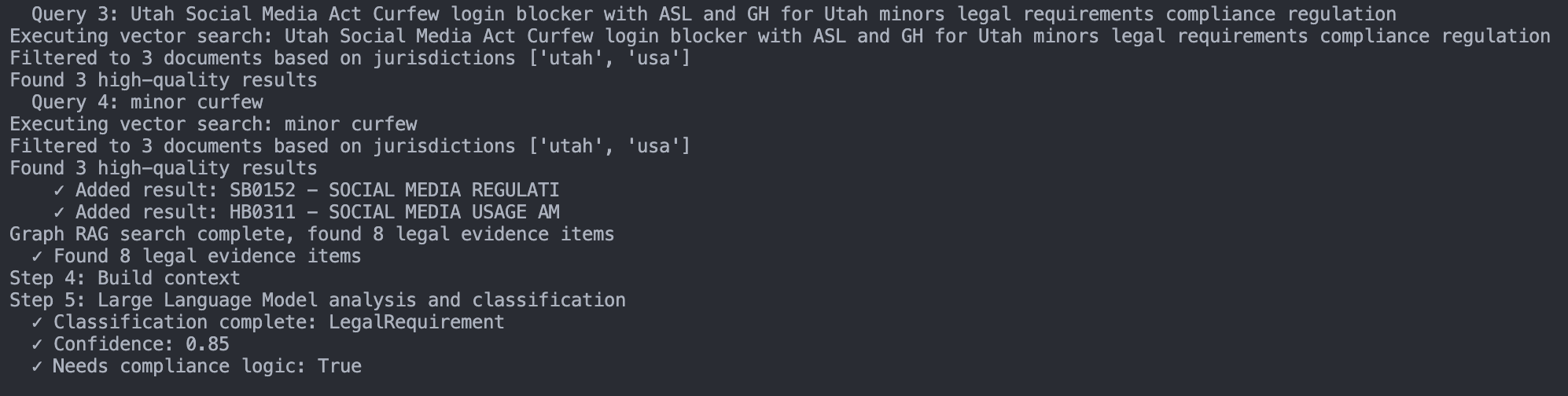
Graph-RAG for Cross-Jurisdiction Reasoning
- Linked compliance layers: A Graph-RAG helps precisely locate related statutes—e.g., California must follow CA state law and U.S. federal law.
- Reduced misjudgment: The graph alleviates standard-RAG misclassification—for example, a feature launching in California may actually be more governed by EU law, and Graph-RAG will prioritize that relevance.
Automated Compliance Analysis (RAG-Powered)
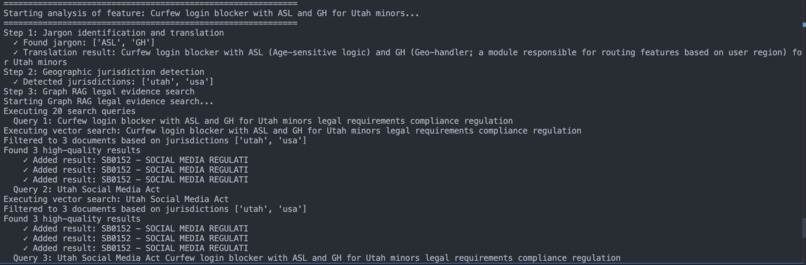
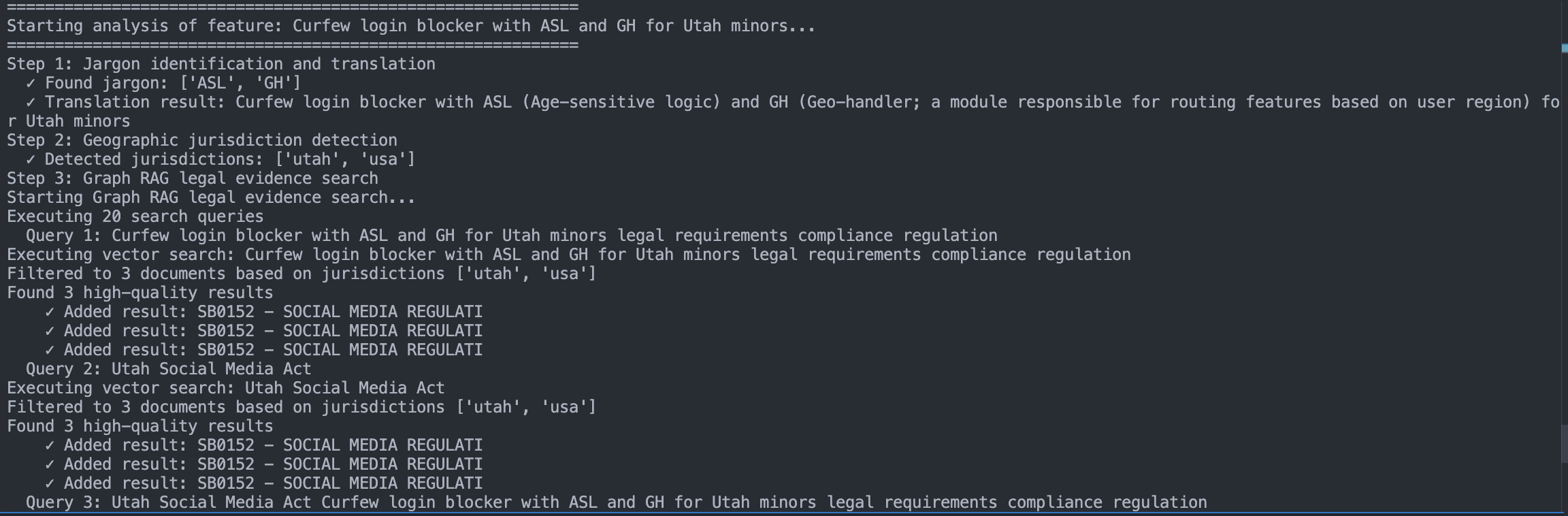
- Context Enrichment: Identifies and explains internal jargon (e.g., "ASL") in product documents.
- Scope Definition: Detects jurisdictions (e.g., "France," "California") and links them to parent entities (e.g., "EU," "USA").
- Evidence-Based Judgment: Retrieves the most relevant legal provisions from a vector database, then passes them to an LLM to decide if compliance logic is required.
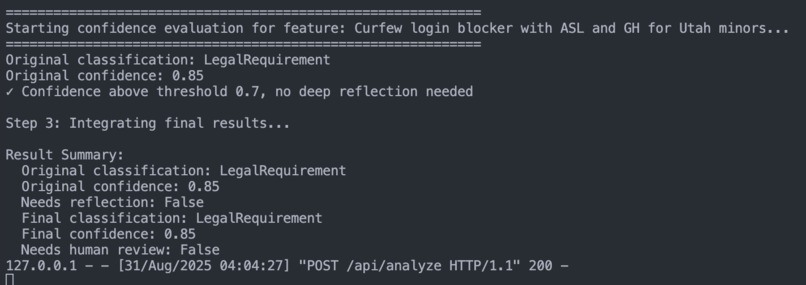
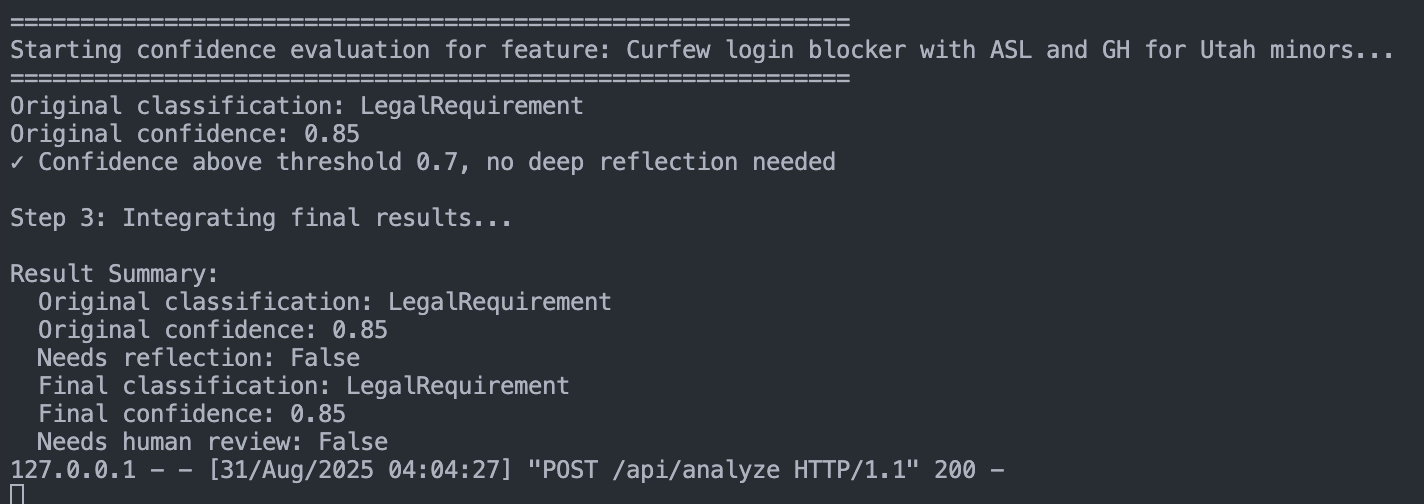
Intelligent Confidence Assessment & Reflection
- Dual-layer review: Each analysis receives a confidence score. If it falls below threshold, a Confidence Agent re-evaluates.
- Reflection on precedent: It consults the Human Feedback Knowledge Base, learning from past human-reviewed cases.
- Refined decisions: Can CONFIRM, REVISE, or ESCALATE to human review.
Closed-Loop Human-in-the-Loop Feedback
/api/feedbackendpoint allows human experts to correct AI outputs.- Corrections are vectorized and stored in the Feedback Knowledge Base, creating a self-improving loop.
API-First Design
/api/analyze→ compliance analysis/api/feedback→ human corrections- Easy integration into CI/CD pipelines, dashboards, or internal tools.
How we built it
We combined LLMs, Graph RAG, and multi-agent reflection into a single modular system.
Development Environment
- Code Editor: Visual Studio Code
- Version Control: Git / GitHub
- Runtime: Python venv
- Code Editor: Visual Studio Code
Technology Stack
- Web Framework: Flask + Flask-CORS
- LLM Orchestration: LangChain
- LLM: Alibaba Tongyi Qianwen (qwen-max-latest)
- Embeddings: BAAI/bge-base-en-v1.5 (Hugging Face)
- Math & Retrieval: scikit-learn (cosine similarity), numpy
- Core Utilities: dotenv, json, re, os, pickle, logging
- Web Framework: Flask + Flask-CORS
Core Assets
- Legal Regulations Knowledge Graph (
./dynamic_legal_graph_db/) documents.json: legal textsjurisdictions.json: mapping of jurisdictions to lawsembeddings.pkl: vector representationsgraph_structure.json: structure of the graph- Human Feedback Knowledge Base (
feedback_knowledge_base.pkl) - Built dynamically during operation from
/api/feedback
- Legal Regulations Knowledge Graph (
Workflow
- Parse feature description → extract jurisdictions.
- Retrieve relevant legal texts using embeddings:
$$\text{sim}(A,B) = \frac{A \cdot B}{|A| |B|}$$
- Parse feature description → extract jurisdictions.
- LLM analyzes retrieved laws to determine compliance requirements.
- If low confidence → Confidence Agent triggers reflection based on historical precedents.
- Store results + corrections → continuously refine system performance.
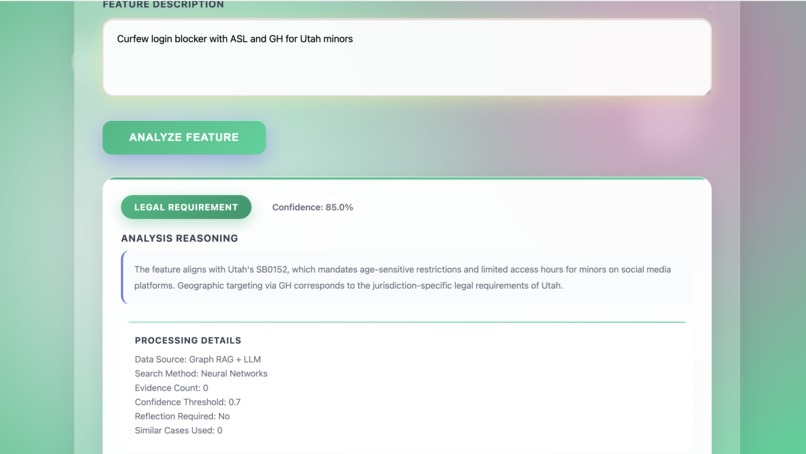
- Output Based on our methodology, the model determines whether a feature is legally required, commercially driven, or unconfirmed. If unconfirmed, a human operator will manually select whether it is legally required or commercially driven. The experience gained from these manual selections is recorded in a backend database. Therefore, the more experience a system has, the less likely it is to require human intervention, and the more accurate and automatic the system will be. For this reason, the final results here are always either Legal Requirement or Business-driven.
Challenges we ran into
Ambiguity of Legal Language
- Many laws are broad, making machine interpretation error-prone.
- Many laws are broad, making machine interpretation error-prone.
Data Creation
- No public dataset existed. We had to curate, clean, and structure legal documents ourselves into a usable knowledge graph.
- No public dataset existed. We had to curate, clean, and structure legal documents ourselves into a usable knowledge graph.
Balancing Automation & Oversight
- Too much automation risked false compliance checks. Too little automation undermined scalability. Designing the right escalation threshold was difficult.
- Too much automation risked false compliance checks. Too little automation undermined scalability. Designing the right escalation threshold was difficult.
Multi-Agent Coordination
- Early prototypes produced contradictory outputs when agents reflected differently. We had to fine-tune thresholds and coordination logic.
- Early prototypes produced contradictory outputs when agents reflected differently. We had to fine-tune thresholds and coordination logic.
Scalability of API Service
- Designing REST endpoints that can serve diverse product pipelines across regions without performance loss required careful architecture.
- Designing REST endpoints that can serve diverse product pipelines across regions without performance loss required careful architecture.
Accomplishments that we're proud of
- Developed a multi-agent reflection framework that simulates human expert deliberation.
- Created a dynamic legal knowledge graph tailored to global operations.
- Implemented a feedback-driven loop that allows the system to learn continuously.
- Encapsulated the complexity into just two REST endpoints, making the system easy to adopt.
- Demonstrated that compliance review can shift from a reactive burden to a proactive safeguard.
What we learned
- How to model legal texts as structured knowledge graphs.
- That human feedback loops are critical for handling ambiguity in compliance.
- How multi-agent reflection can significantly improve decision robustness.
- Practical lessons in API design, ensuring scalability in real-world integration.
- Reinforced the value of combining AI reasoning + human oversight in sensitive domains.
What’s next for ReguLLM
Expanding Jurisdiction Coverage
- Incorporate more countries's acts, especially emerging markets with fast-changing laws.
- Incorporate more countries's acts, especially emerging markets with fast-changing laws.
Advanced Reflection Mechanisms
- Use reinforcement learning to further improve the Confidence Agent’s autonomy.
- Use reinforcement learning to further improve the Confidence Agent’s autonomy.
Integration with CI/CD
- Embed compliance checks directly into feature deployment pipelines.
- Embed compliance checks directly into feature deployment pipelines.
Explainability Features
- Provide human-friendly reports explaining why a compliance flag was raised, to increase trust.
- Provide human-friendly reports explaining why a compliance flag was raised, to increase trust.
Collaboration with Legal Experts
- Build a community feedback model where external experts can contribute to the feedback knowledge base.
- Build a community feedback model where external experts can contribute to the feedback knowledge base.



Log in or sign up for Devpost to join the conversation.