-
-
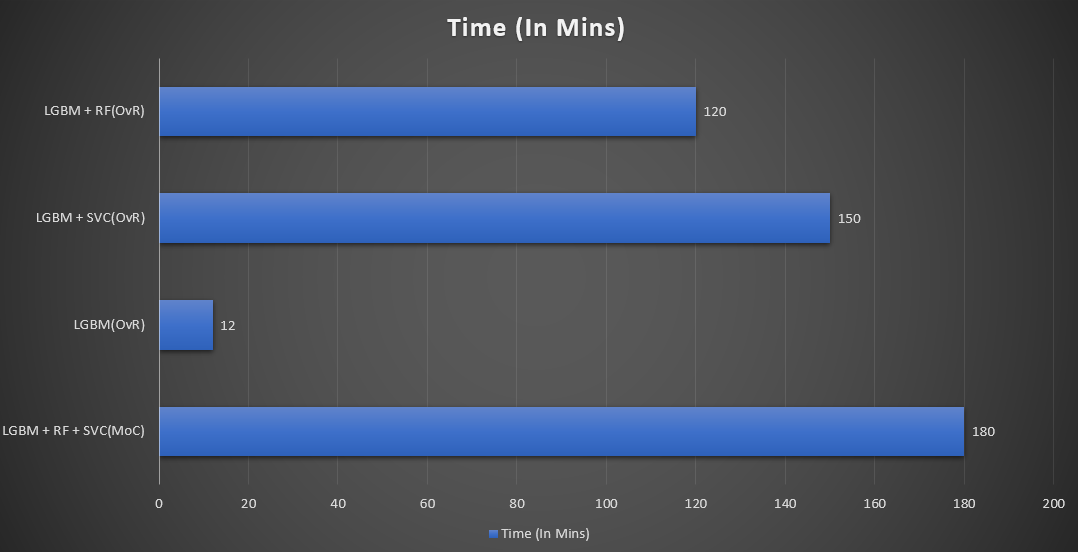
Time
-
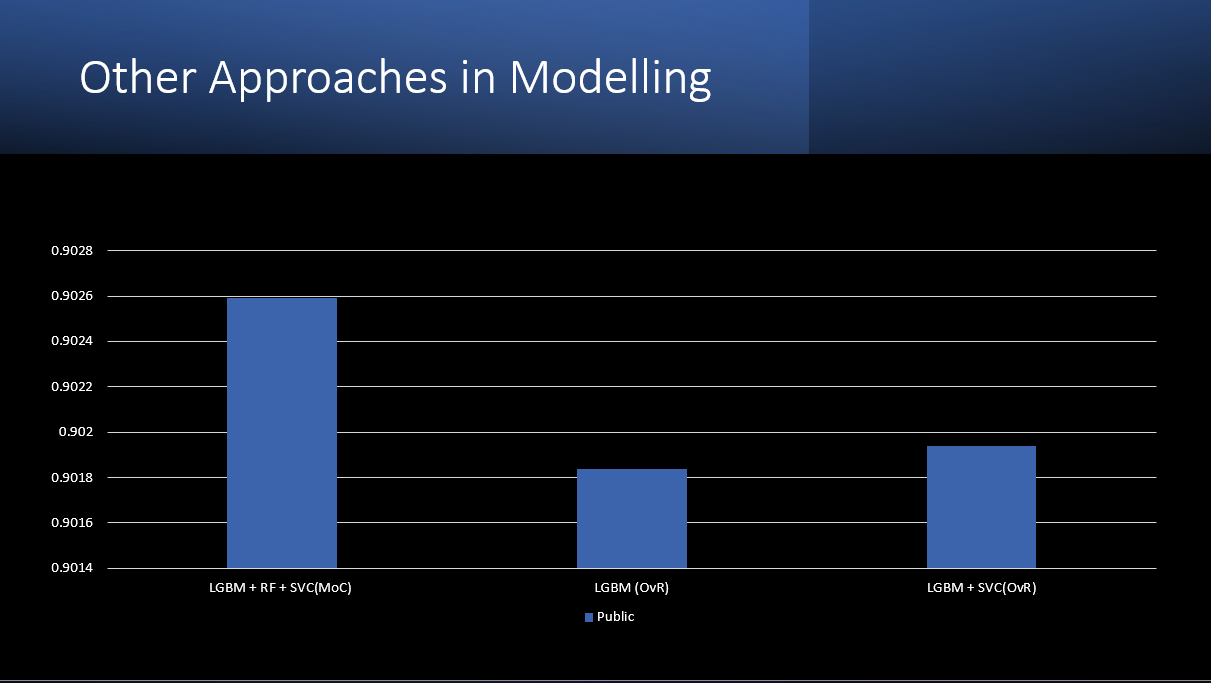
Other Modelling Aproaches
-
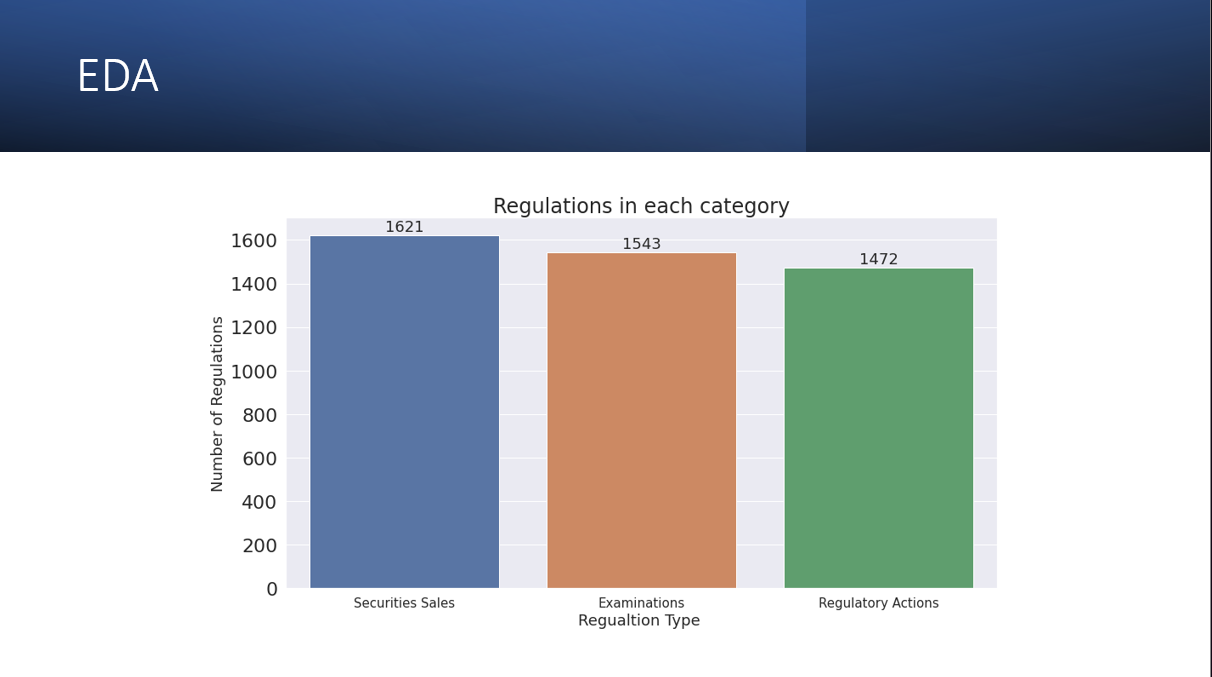
EDA
-
Inspiration
An employee working in a Multinational Company or a huge firm must go through tons of files and paperwork to find out the rules/ regulations. It is natural for him to be confused and distressed as there is a vast amount of data that he will have to traverse to find out the information he is looking for.
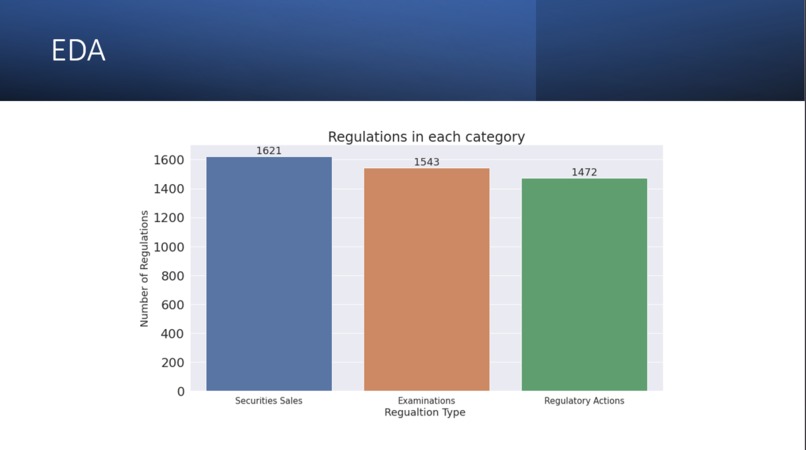
This leads us to our business problem. All organizations are obliged to be abreast of regulatory developments occurring in their industries and must adhere to these rules and regulations. We need the regulations to be categorized into several categories so that we can understand which regulations are crucial for our business.
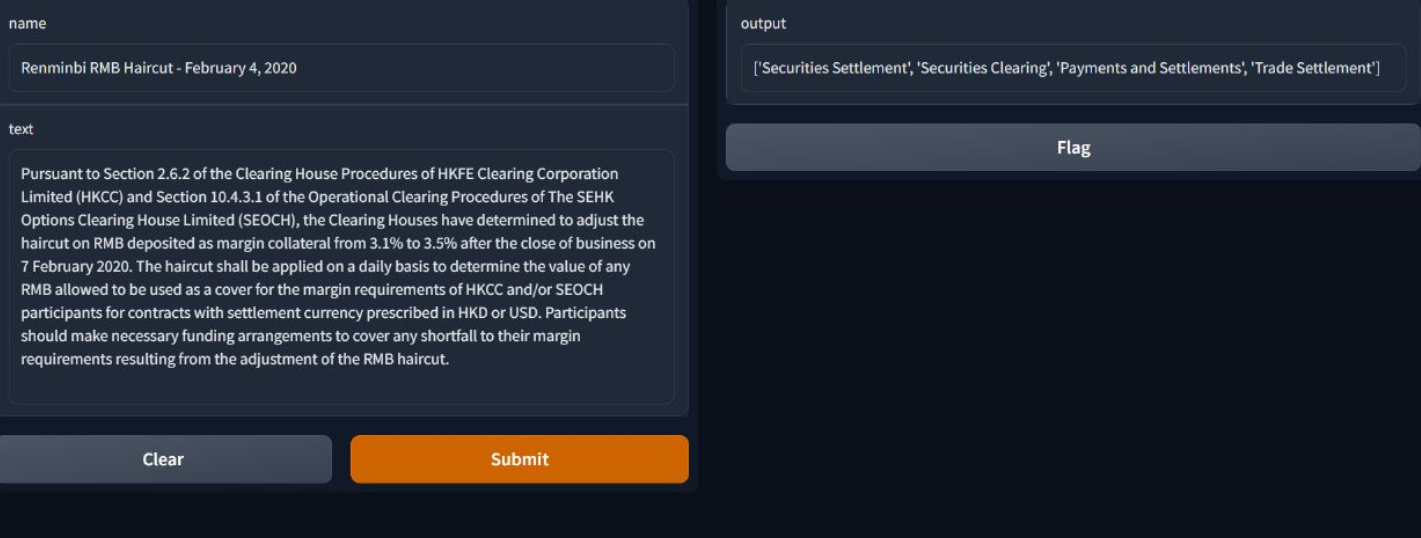
The given problem relates to regulatory updates for providers of banking, insurance, and financial services that have been made public by various regulators. We require NLP models to analyze the content of the Name and Summary of each regulatory update and to apply tags (classification) based on this analysis to solve the classification challenge.
Businesses can simply identify updates that are vital and can even automate their assignment to the correct people/areas if they can identify the correct tag. This will make it easy to manage compliance policies and track all regulatory revisions.
How we built it
The dataset was fetched from Kaggle which included the "Law" and "Category Names". The text was then pre-processed by: 1) Converting text to lowercase. 2) Removing White Spaces. 3) Removing Punctuations. 4) Removing Digits. 5) Removing Stop Words. Next, a TFIDF vectorizer was used to convert the text data into vectors. After this, most basic ML models which included Logistic Regression, KNN, and Naive Bayes were applied to the pre-processed data. These models did not give us outstanding results thus we moved further for tree-based models which included LGBM, Random Forest, and Gradient Boosting. After a lot of experimentation, an ensemble of LGBM with its best parameters and Random Forest using a One Vs Rest Classifier gave us the highest Score. Finally, for demonstrator purposes, we used Gradio Library.
Challenges we ran into
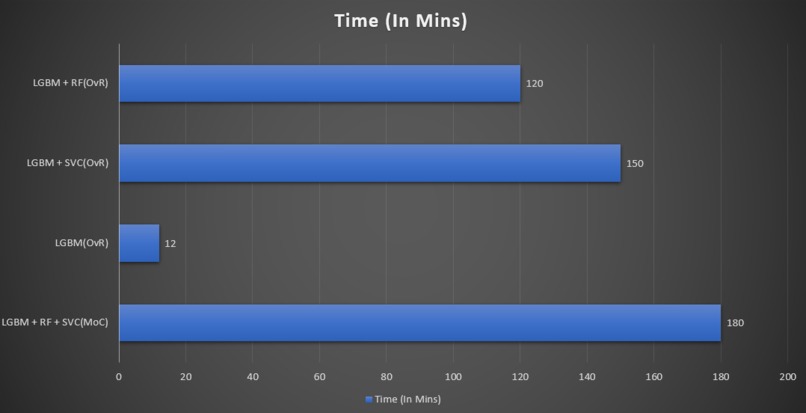
- Hyper Parameter Tuning using exhaustive Grid Search CV for finding the best parameters was challenging as it took a huge amount of time.
- The model training time for ensemble learning was enormous.
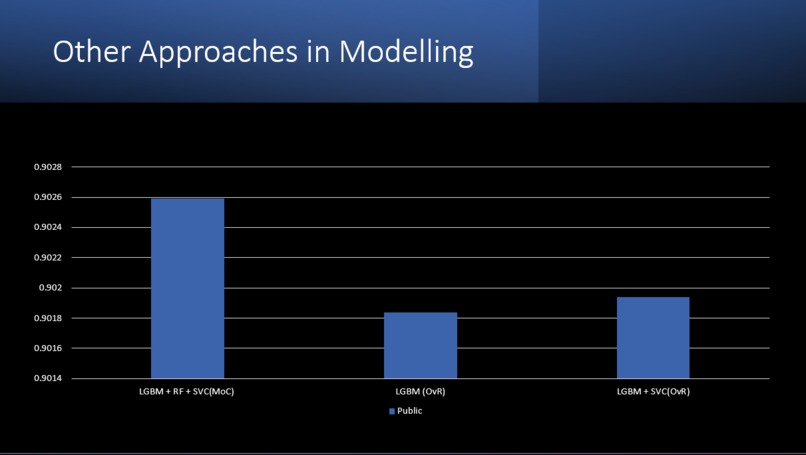
- In the future we would try, LGBM using MoC, we believe it would be a more robust model.
- Since policies are subject to amendments, the data update is really important as well.
Accomplishments that we're proud of
The model can classify the by-laws by assigning them tags with 90 % accuracy and an F1 score of 0.903.
Key Take Away from the Hackathon
- A combination of a Tree-Based Model along with a Linear Model is a good approach as an ensemble takes care of the high variance in tree models and high bias in linear models, thus creating a good fit.
- Training time should also be considered an important parameter when resources are at stake.
- we conclude that LGBM (OvR) is the most optimized model as requires very less training time and gives at-par results.
Future Scope
- Retrain the models using newly updated data.
- Provide customization to companies for classifying theirs by laws.
Built With
- gradio
- python


Log in or sign up for Devpost to join the conversation.