📖 About the Project
🎯 What Inspired Us
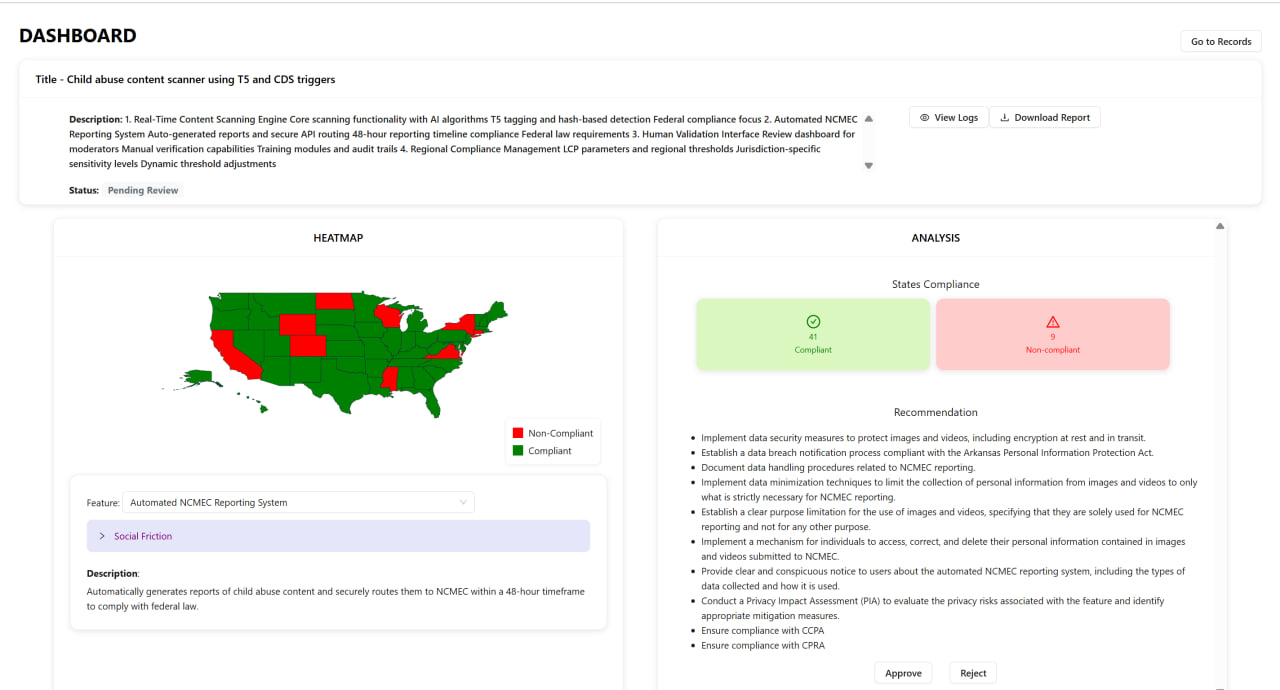
The inspiration for TechJam came from a critical gap we identified in the software development industry: the lack of automated compliance analysis for Product Requirements Documents (PRDs). As regulations become increasingly complex across different US states (GDPR, CCPA, PIPL, LGPD, and state-specific laws), manually ensuring compliance has become a time-consuming and error-prone process.
We were particularly motivated by:
- Real-world pain points: Development teams spending weeks manually reviewing PRDs for compliance
- Regulatory complexity: The growing web of state and federal regulations affecting software products
- Risk mitigation: The need to identify compliance issues early in the development lifecycle
- Scalability challenges: Manual compliance review doesn't scale with modern development velocity
🧠 What We Learned
Multi-Agent System Architecture
Building a multi-agent LangGraph workflow taught us valuable lessons about:
- Agent specialization: Each agent needs a clear, focused responsibility
- State management: Complex workflows require careful state tracking and persistence
- Error handling: Robust error handling is crucial when dealing with LLM responses
- Type safety: Strong typing prevents runtime errors in complex data flows
Compliance Analysis Challenges
We discovered that compliance analysis involves:
- Regulation mapping: Matching features to relevant regulations requires deep domain knowledge
- State-specific nuances: Each US state has unique compliance requirements
- Cultural sensitivity: Features must be evaluated for potential social friction
- Risk assessment: Quantifying compliance risk requires sophisticated analysis
Technical Architecture Insights
- Microservices communication: HTTP-based communication between backend and LangGraph
- Real-time processing: Handling long-running analysis workflows
- Data persistence: Managing complex nested data structures in MongoDB
- Frontend state management: Coordinating multiple data sources in React
🔨 How We Built It
Phase 1: Core Infrastructure
We started by building the foundational components:
# LangGraph workflow structure
class ComplianceWorkflow:
def __init__(self):
self.prd_parser = PRDParserAgent(self.llm)
self.feature_analyzer = FeatureAnalyzerAgent(self.llm)
self.regulation_matcher = RegulationMatcherAgent(self.llm)
# ... additional agents
Phase 2: Multi-Agent Development
Each agent was developed with specific responsibilities:
- PRD Parser: Extracts features using RAG (Retrieval Augmented Generation)
- Feature Analyzer: Analyzes individual features for compliance implications
- Regulation Matcher: Maps features to relevant regulations
- Risk Assessor: Evaluates compliance risk levels
- Cultural Sensitivity Analyzer: Identifies potential social friction points
- State Compliance Agent: Checks state-specific compliance requirements
Phase 3: Integration & Optimization
We integrated the components and optimized for:
- Performance: Batch processing for state-by-state analysis
- Reliability: Robust error handling and fallback mechanisms
- Scalability: Efficient MongoDB queries and data structures
- User Experience: Intuitive React dashboard with real-time updates
Phase 4: Advanced Features
Added sophisticated capabilities:
- Executive Report Generation: Automated comprehensive compliance reports
- Status Management: Approval/rejection workflows with reasoning
- PDF Export: Professional report generation with markdown support
- Cultural Sensitivity Analysis: US-focused social friction detection
🚧 Challenges We Faced
1. LLM Response Parsing
Challenge: LLMs often return malformed JSON, causing workflow failures.
Solution: Implemented robust JSON extraction with multiple fallback strategies:
def _extract_json_from_response(self, response_text: str) -> Dict[str, Any]:
# Multiple parsing strategies with detailed error logging
# Aggressive cleaning and field-specific extraction
# Graceful degradation with default structures
2. Type Safety in Complex Workflows
Challenge: Type mismatches between agents caused runtime errors.
Solution: Added comprehensive type conversion and validation:
# Ensure all numeric fields are properly converted
overall_score = float(us_score.overall_score)
risk_scores = [float(f.get("risk_score", 0.5)) for f in feature_state_results]
3. State-by-State Compliance Complexity
Challenge: Each US state has unique regulations and requirements.
Solution: Built a centralized state regulations cache with standardized interfaces:
class StateRegulationsCache:
def get_state_regulation(self, state_code: str) -> StateRegulation:
# Cached state regulations with standardized structure
# Support for dynamic updates and regional variations
4. Real-time Frontend-Backend Coordination
Challenge: Coordinating long-running analysis with responsive UI.
Solution: Implemented asynchronous processing with status tracking:
// Frontend handles async operations gracefully
const handleStatusUpdate = async (status: string, reason: string) => {
setStatusUpdateLoading(true);
try {
await updatePrdStatus(prdId, { status, reason });
message.success('Status updated successfully');
await refreshData();
} catch (error) {
message.error('Failed to update status');
}
};
5. Cultural Sensitivity Analysis
Challenge: Quantifying cultural sensitivity across diverse US populations.
Solution: Developed US-specific cultural factors framework:
self.us_cultural_factors = {
"diversity_and_inclusion": {
"racial_diversity": ["African American", "Hispanic/Latino", ...],
"gender_identity": ["LGBTQ+ rights", "Gender equality", ...],
# ... comprehensive cultural mapping
}
}
6. Executive Report Generation
Challenge: Converting complex analysis results into readable reports.
Solution: Built markdown-aware PDF generation with structured content:
// Markdown processing for professional reports
export function markdownToStructuredText(text: string): Array<{ type: string; content: string; style?: any }> {
// Parse markdown and apply appropriate styling
// Support for headings, lists, bold text, and formatting
}
🎯 Key Achievements
- ✅ Multi-Agent Workflow: Successfully orchestrated 8 specialized agents
- ✅ State Compliance: Comprehensive analysis across all 50 US states
- ✅ Cultural Sensitivity: US-focused social friction detection
- ✅ Real-time Processing: Asynchronous analysis with status tracking
- ✅ Professional Reports: Automated executive report generation
- ✅ Robust Error Handling: Graceful degradation and detailed logging
- ✅ Type Safety: Comprehensive type conversion and validation
- ✅ Scalable Architecture: Microservices with efficient data management
🔮 Future Enhancements
- International Compliance: Extend beyond US to global regulations
- Machine Learning: Train custom models for better compliance prediction
- Real-time Monitoring: Continuous compliance monitoring for deployed features
- Integration APIs: Connect with existing development tools and workflows
- Advanced Analytics: Predictive compliance risk modeling
This project represents a significant step toward automating compliance analysis in software development, reducing manual effort while improving accuracy and coverage. The multi-agent approach demonstrates how AI can be effectively orchestrated to solve complex, domain-specific problems.











Log in or sign up for Devpost to join the conversation.