Inspiration
Our inspiration came from seeing recurring headlines of big tech companies facing multi-million dollar lawsuits over privacy and regulatory non-compliance, often stemming from geo-specific features. We realized that in a global company, the challenge isn't a lack of legal expertise, but a gap in communication and tooling between legal teams and product development. We were motivated to build a project that could bridge this gap and have the most significant real-world impact: moving companies from a reactive, "firefighting" stance on compliance to a proactive, preventative one.
What it does
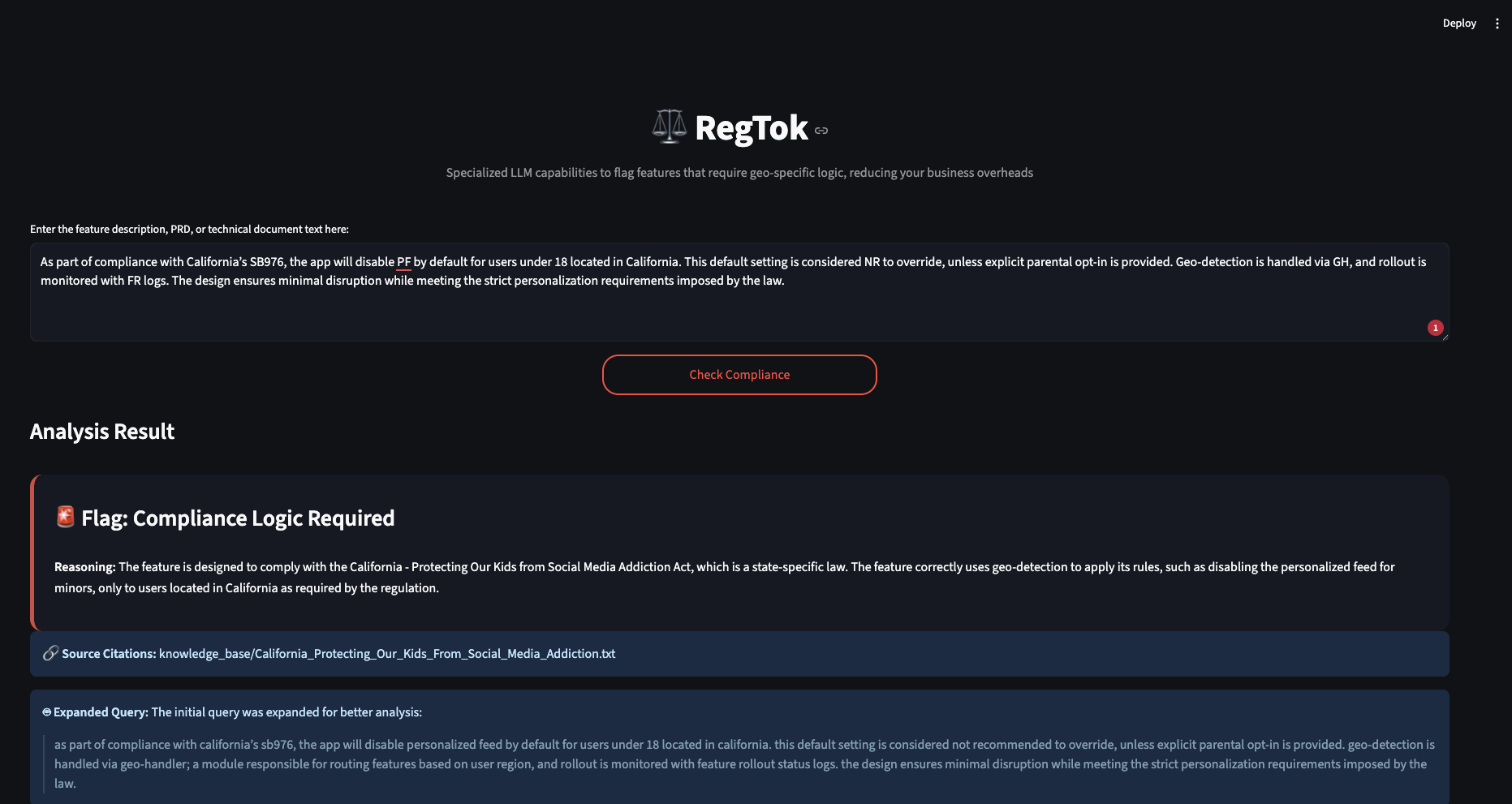
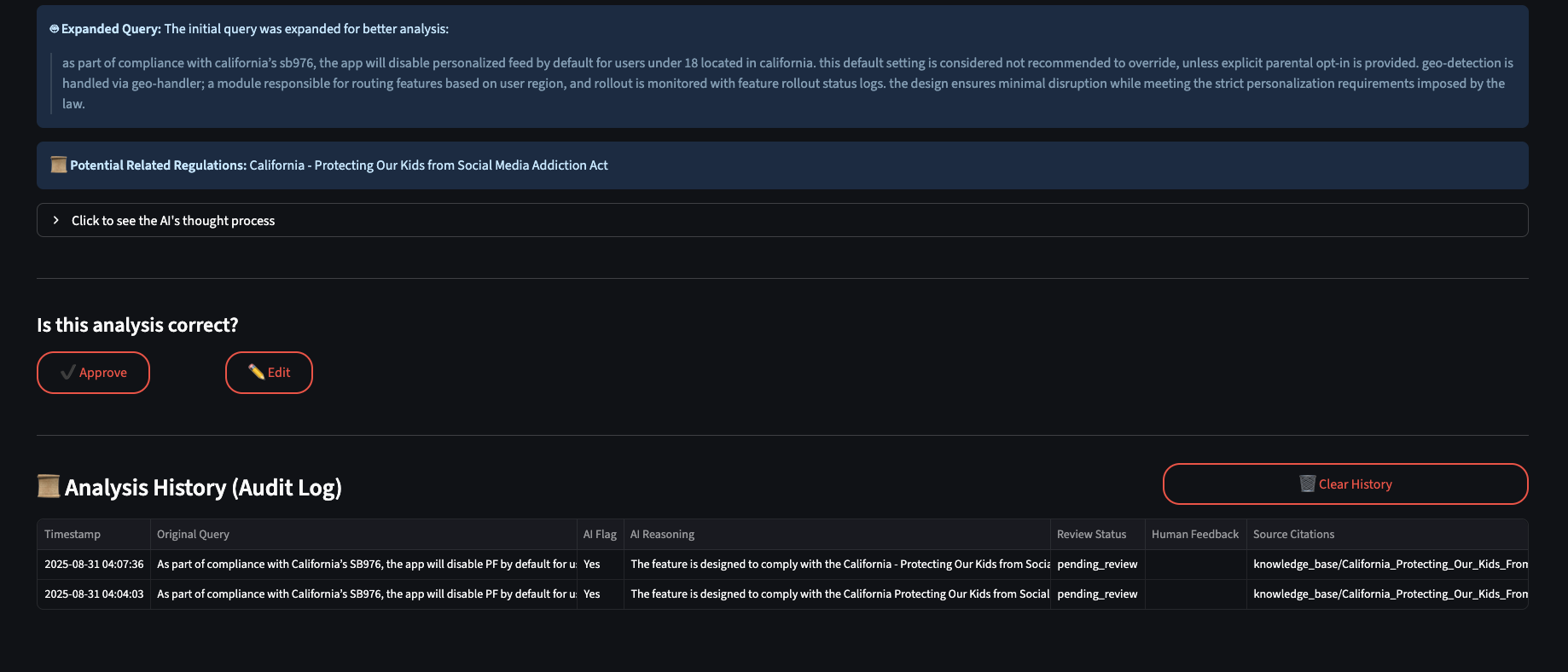
RegTok directly answers the hackathon's problem statement by providing an automated, auditable system to detect geo-specific legal requirements for new software features. An engineer or product manager simply pastes a feature description, PRD, or technical document into the web app. RegTok then performs a multi-step analysis: It retrieves relevant legal texts from a curated knowledge base of regulations. It uses a powerful LLM (Gemini) to reason over the feature description and the retrieved legal context. It produces a structured, actionable output, including: A clear Flag (Yes, No, or Uncertain) indicating if compliance logic is needed. Concise Reasoning explaining its decision. Source Citations that link the reasoning directly back to the specific legal document it used, making the result fully auditable. A list of potentially Related Regulations. Finally, it features a complete Human-in-the-Loop system where experts can approve or correct the AI's findings, with all interactions logged in a persistent audit trail. This feedback is then used to make the AI smarter on future analyses.
How we built it
We built RegTok by leveraging our collective technical skills from previous internship experiences and a passion for building practical AI solutions. The core of our project is a Retrieval-Augmented Generation (RAG) architecture, chosen specifically to ground the LLM in factual, up-to-date legal data and enable our critical citation feature. Our process involved: Setting up the Knowledge Base: We used ChromaDB Cloud as our vector database to host embeddings of summarized legal documents. This decoupled storage allows the knowledge base to be updated independently. Designing the RAG Pipeline: We used Python to build the end-to-end pipeline. When a query comes in, it's vectorized and used to search ChromaDB. The retrieved context is then dynamically inserted into a prompt. Advanced Prompt Engineering: We went beyond basic prompting by integrating several techniques. We used Few-Shot Prompting by fetching human-corrected examples from our SQLite audit log to create a self-evolving system. We also guided the model with Chain-of-Thought instructions, telling it to "think step-by-step" and compare the user's query to the provided examples before making a final decision. Building the UI: We used Streamlit to create a clean, intuitive, and fully functional user interface, complete with the feedback mechanism and a real-time audit log display. The entire system is powered by the Google Gemini API through Google AI Studio.
Challenges we ran into
Vector Database Nuances: As our first time building a RAG system from scratch, the initial setup and data ingestion pipeline for ChromaDB was a significant learning curve. Ensuring our metadata was correctly structured to enable the citation feature required careful design and multiple iterations. API Rate Limiting: Working within the budget constraints of the Google API's free tier presented a real-world challenge. We frequently hit rate limits during development and testing, which forced us to be more efficient with our code, implement gentle delays in our batch evaluation scripts, and build a robust system that could handle potential API interruptions.
Accomplishments that we're proud of
We are incredibly proud of building a complete, end-to-end system that not only works but also directly addresses the core requirements of the hackathon prompt in a sophisticated way. Specifically: Building a Full RAG System: We successfully implemented a complex RAG pipeline from scratch, integrating a cloud vector DB with a powerful LLM. Creating a Self-Evolving Agent: The Human-in-the-Loop feedback mechanism isn't just for show—it actively makes the AI smarter by feeding corrected examples back into the prompt, demonstrating a practical path to continuous improvement. Achieving Audit-Ready Transparency: The source citation feature is our biggest accomplishment. It elevates the tool from a simple "checker" to a trustworthy, auditable system that could genuinely be used by a compliance team.
What we learned
This hackathon was a deep dive into building impactful, real-world AI products. Our key takeaways were: The Power of Grounding LLMs: We learned firsthand that the true power of LLMs in an enterprise context comes from grounding them in factual, private data through RAG. This is the key to building trustworthy and reliable AI. Human-AI Collaboration is Key: An AI is most effective when it serves as a co-pilot for a human expert. Designing the HITL feedback loop taught us the importance of building systems that learn from and collaborate with their users. Product-Minded Engineering: We learned to think beyond the code and focus on the user experience—from designing an intuitive UI with Streamlit to ensuring the final output (with citations and clear reasoning) was genuinely useful and solved the user's core problem.

Log in or sign up for Devpost to join the conversation.