-
-
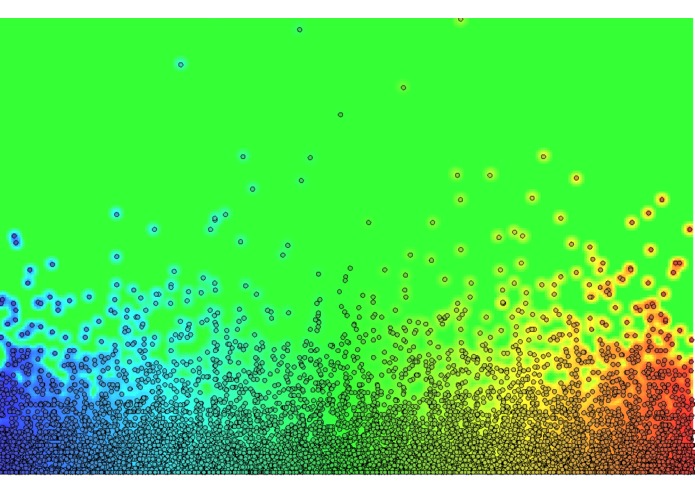
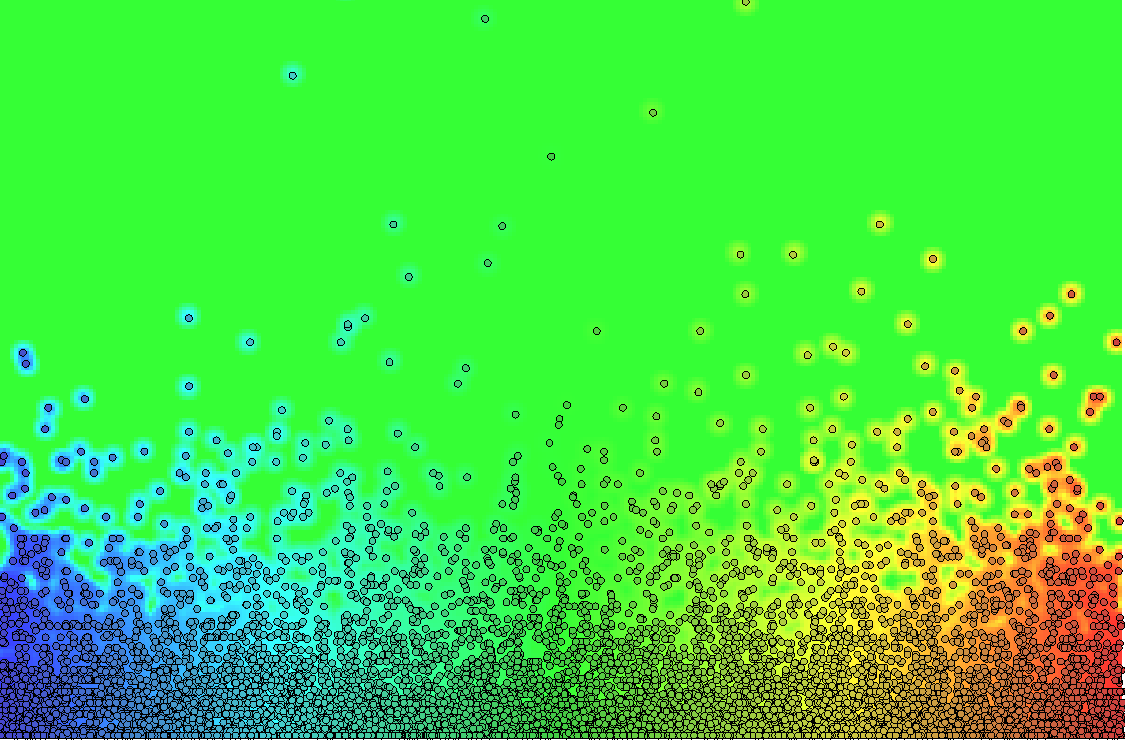
Rain Heatmap
-

Panthera Data Set
-
Darwin Core Visualization
-
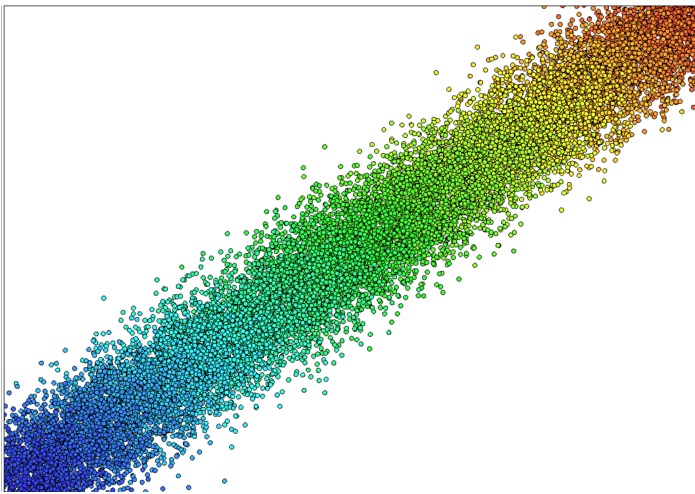
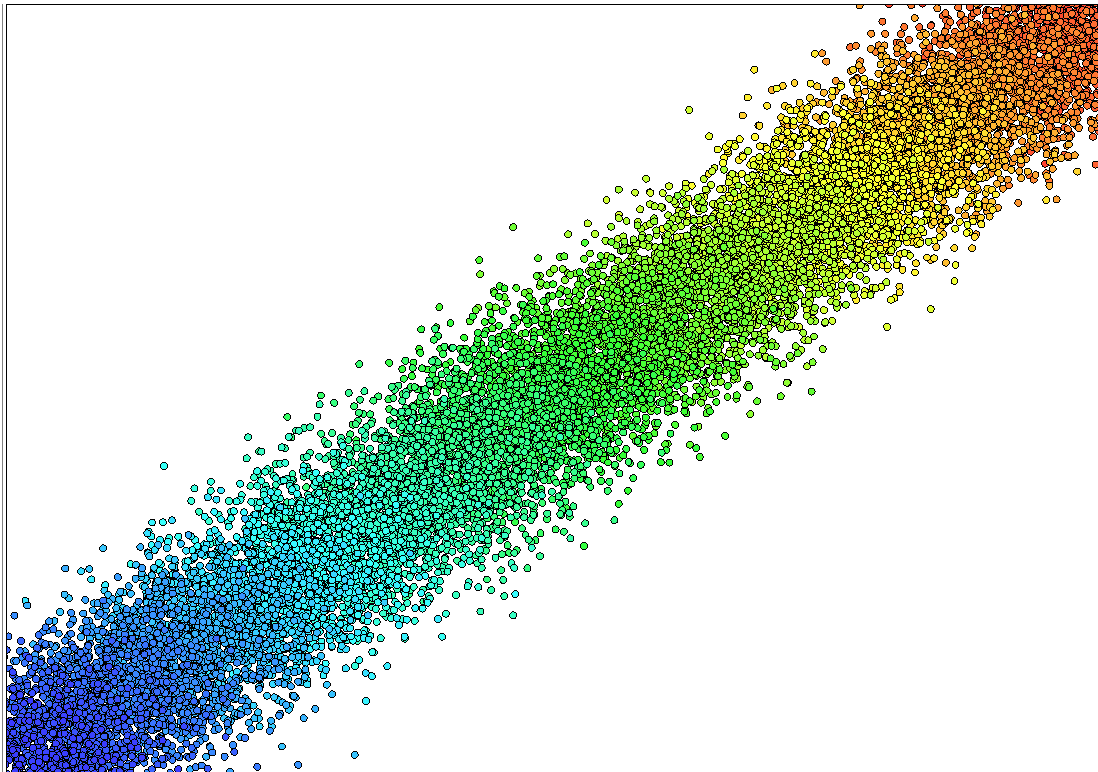
Correlation Plot
-
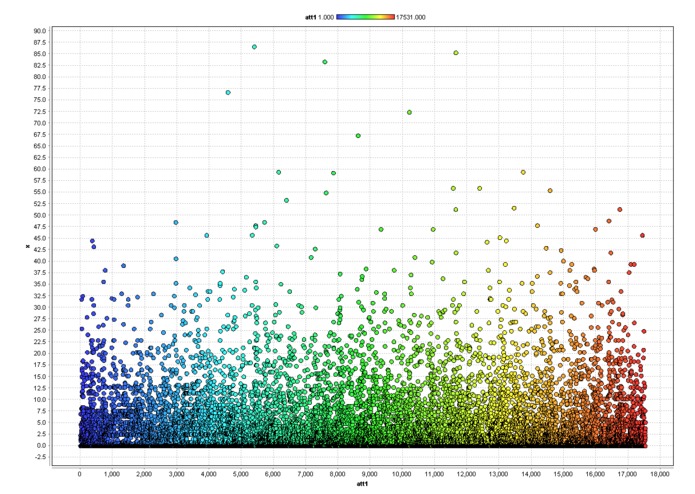
Rain Measurments
Inspiration
I have done a lot of data mining in the past and most of what I do involves AI, R, or utilizing my different analytical skills. I think the ability to turn open data sets to the Darwin core format and analyzing them is really important in predicting ecological and environmental trends.
What it does
Utilizing R and GPlot with Rapid Miner Studio's API and its Hadoop extension we are able to predict correlations for different ecological trends using AI. This means lots of the data sets available now, even if you look at finding averages or going through millions of species, you can end up finding the stats, averages, and correlations in minutes.
How I built it
For data set and predictive analysis we were utilizing Rapid Miner Studio's Hadoop extension and create a custom process in Rapid Miner. For different trends, converting, or cleaning up the data we utilized R and GPlot.
Challenges I ran into
We did have some problems in the beginning in terms of processing speeds on the computer, and sometimes the program did crash but we were quickly able to fix it, and work around that
Accomplishments that I'm proud of
I was able to mine so much data, come up with statistics, perform regressional & predictive analysis, and visualize large ecological data sets
What I learned
I learned how to debug R better, as well as got introduced to Darwin Core's Meta format
What's next for Regressional Analysis for Ecological Datasets
It is in its Hackathon stage, but eventually I want to do more complex programs and create my own interface programs in the future



Log in or sign up for Devpost to join the conversation.