Inspiration
A compliance officer asking "what's the DORA major-incident reporting deadline?" spends ~45 minutes grepping regulation PDFs — and in this domain a wrong article number is itself a reportable error. Generic chatbots make it worse: they hallucinate plausible-looking article numbers with total confidence, and they only know the current text of a rule — useless when an auditor asks "what applied when the incident actually happened?" We built RegQuery to answer regulatory questions the way a careful analyst does: grounded in the exact source text, cited, time-aware, and honest about what it doesn't know.
What it does
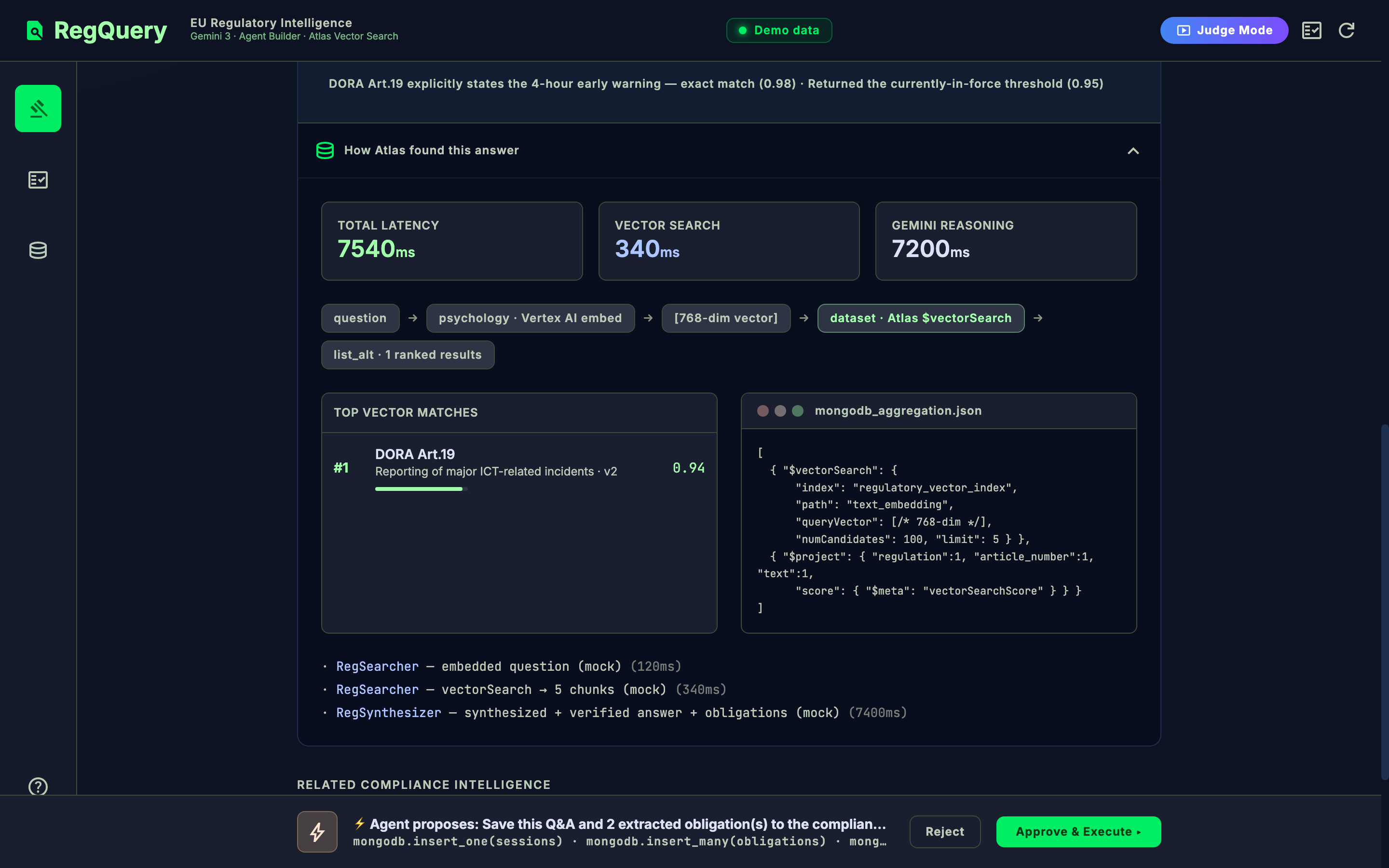
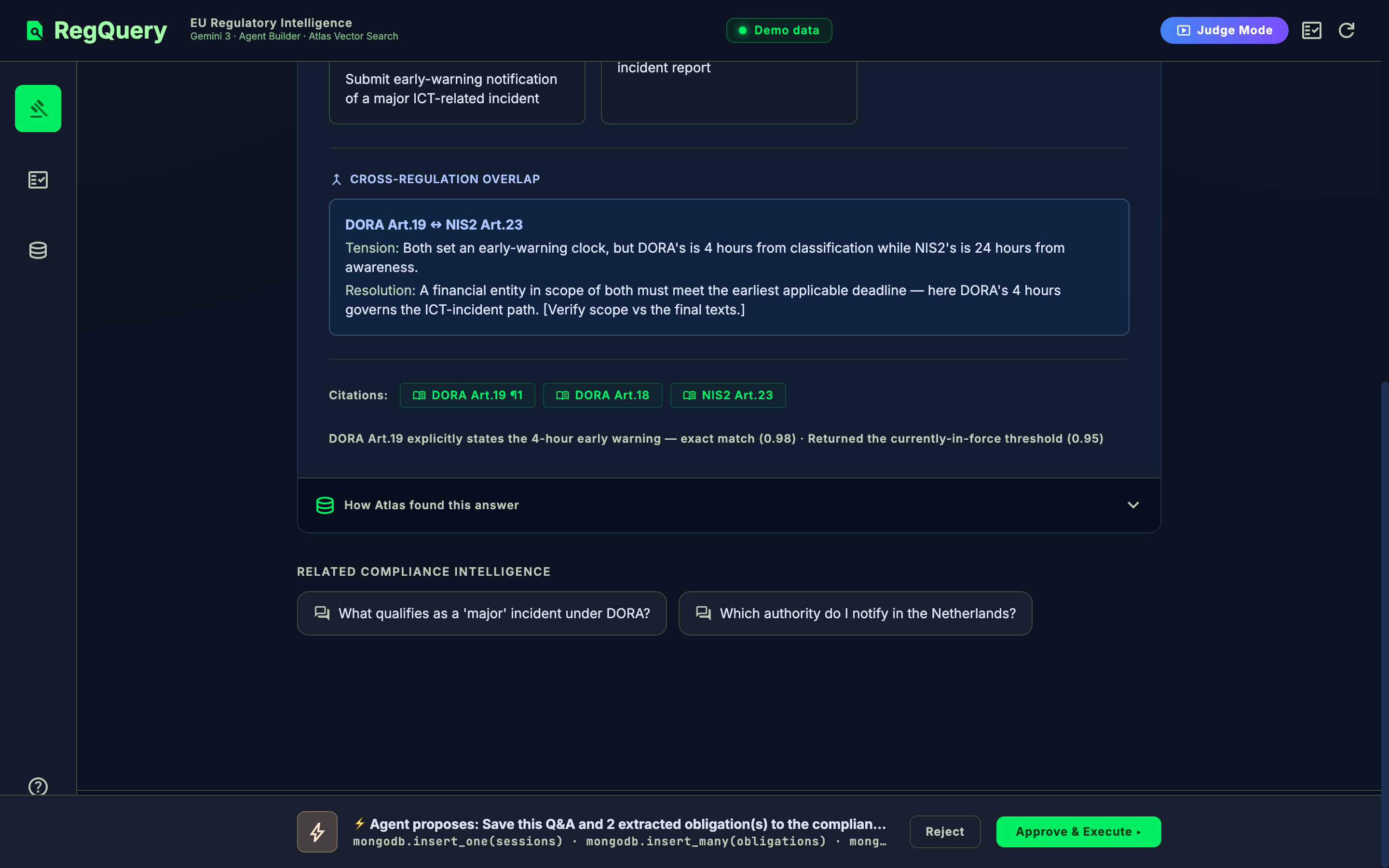
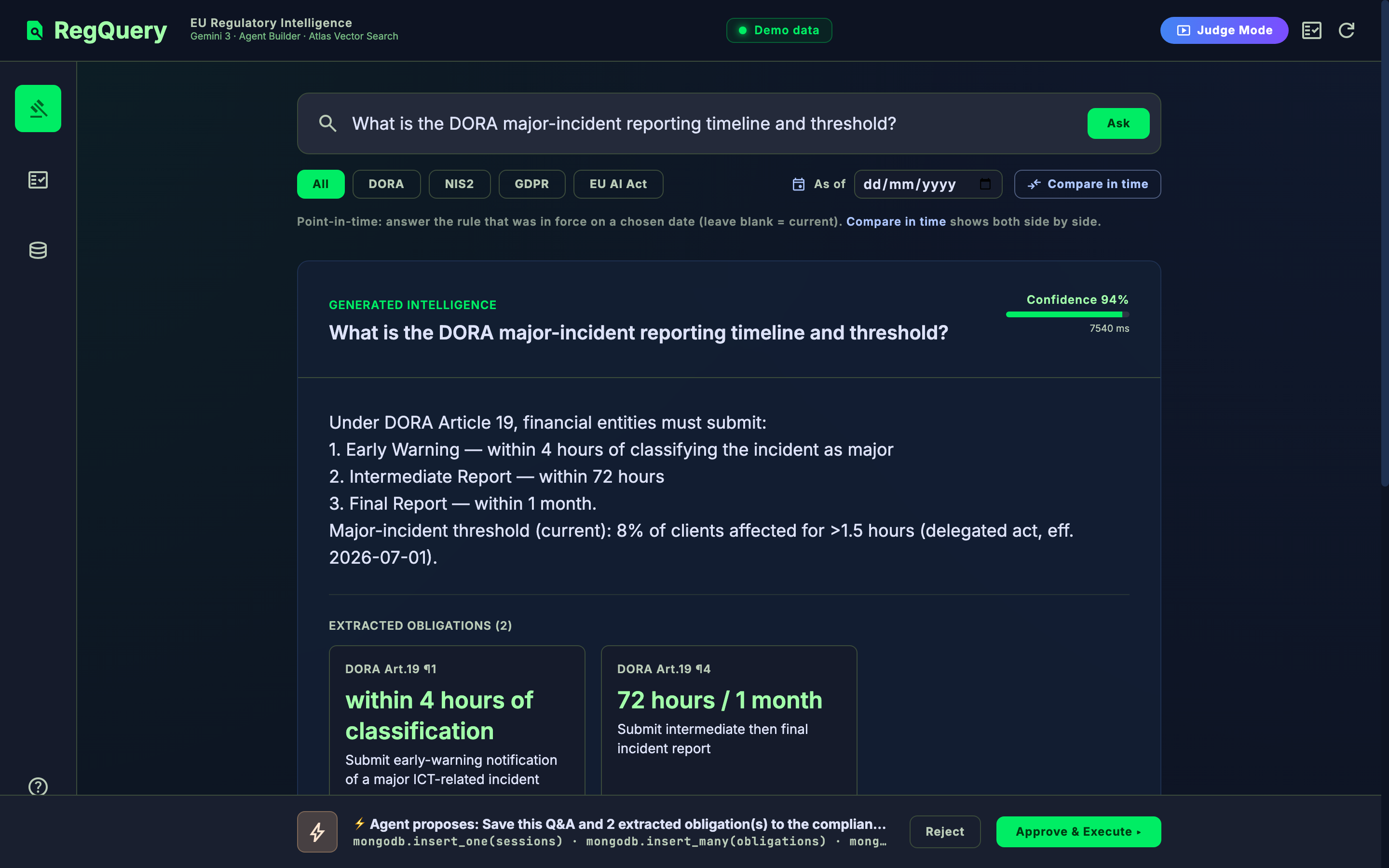
- Grounded, cited answers. Embeds the question (Vertex AI), retrieves the top regulation article chunks from MongoDB Atlas Vector Search, and Gemini synthesizes an answer only from those chunks — every claim cited to an exact article (e.g. "DORA Art.19 ¶1").
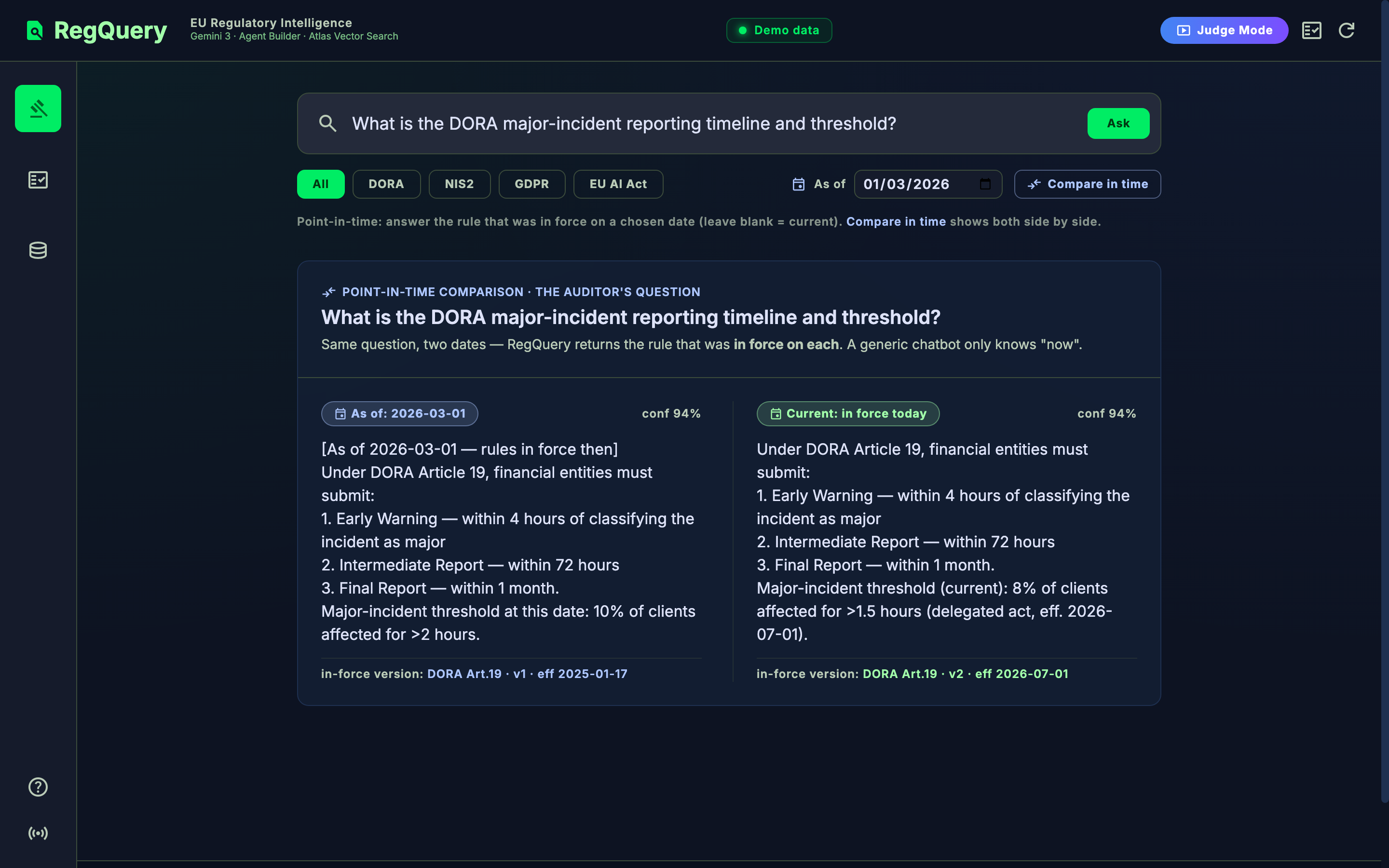
- Point-in-time retrieval (the superpower). Pass an
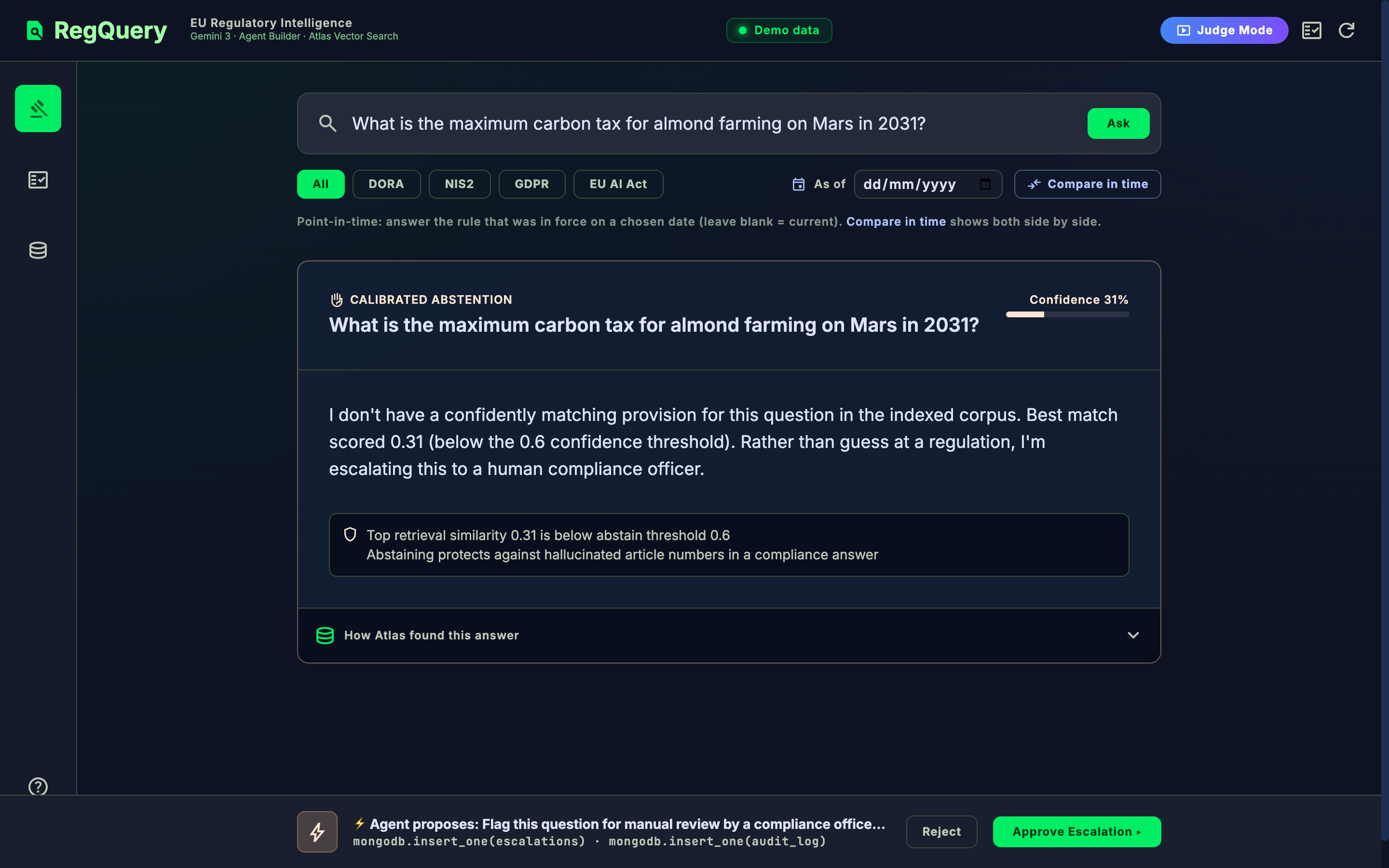
asOfdate and Atlas returns the provision that was in force on that date (effective_date ≤ asOf < superseded_date) — the exact question an auditor asks. Same question, March 2026 vs today, returns two correctly different thresholds. - Calibrated abstention. If the best retrieval similarity is below threshold, RegQuery refuses and escalates to a human instead of inventing an article number. Knowing when it doesn't know is the #1 trust signal for a compliance tool.
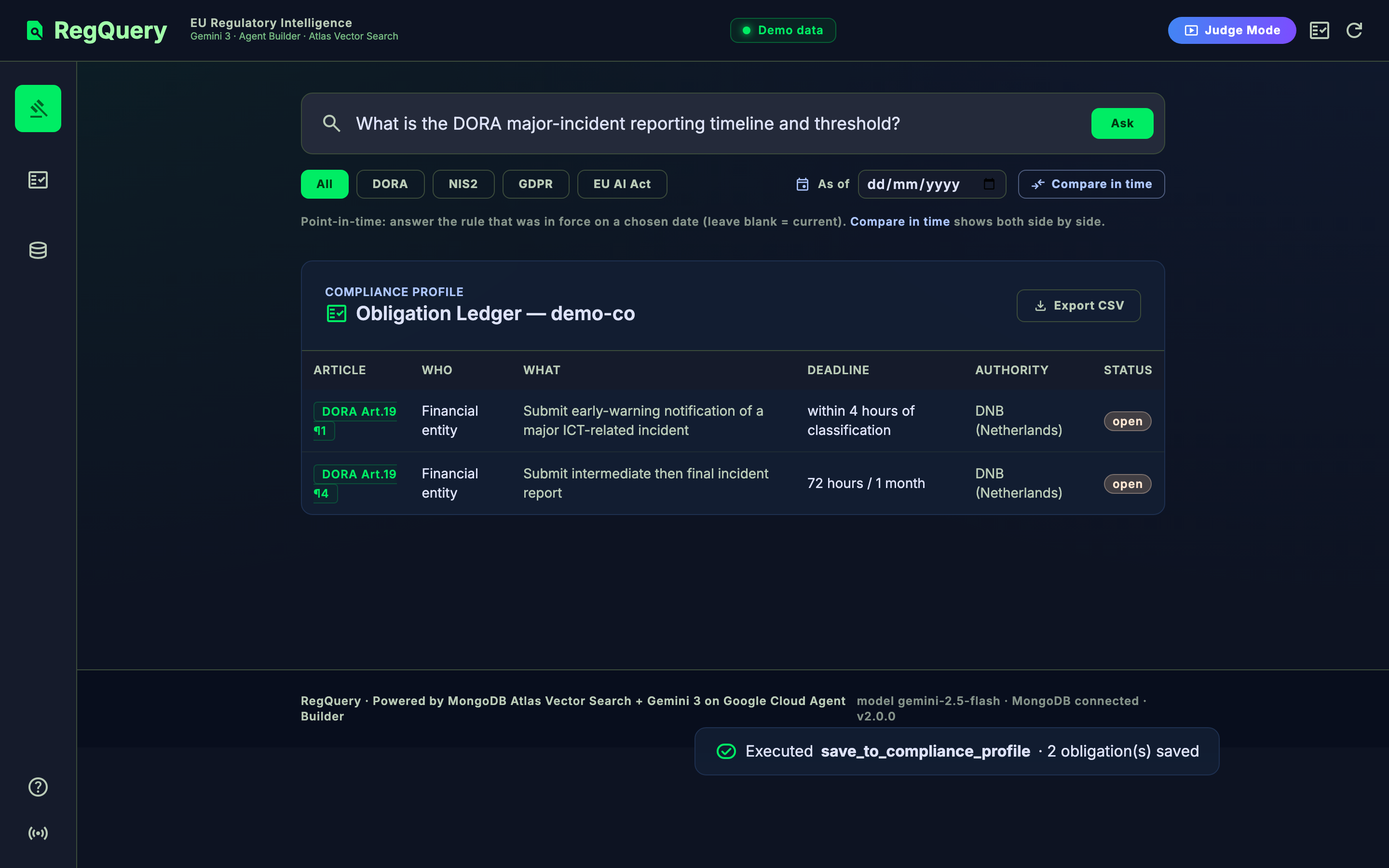
- Human-gated write-back + audit trail. It extracts structured obligations (who · what · deadline · authority · trigger) and proposes a write — but persists nothing until a human approves. Every approved write lands in a shared obligation ledger plus an immutable audit log, exportable to CSV for a GRC tool.
How we built it
- Gemini (Vertex AI) — multi-hop synthesis, citation discipline, structured obligation extraction (strict JSON), and confidence + reasoning.
- Google Cloud Agent Builder — the judged agent (
agent-builder/agent.json): Gemini model + MongoDB MCP as the tool source, withinsert_one/update_onegated behind human approval. - MongoDB Atlas Vector Search via the MongoDB MCP server — semantic retrieval over the regulation corpus, the obligation ledger, and the audit log.
- Cloud Run — hosts the Express demo UI that mirrors the agent end-to-end.
- Vertex AI
text-embedding-004— 768-dim embeddings for retrieval.
Challenges we ran into
- Article-number accuracy is non-negotiable. A single wrong citation discredits the whole tool, so we constrained Gemini to answer strictly from retrieved excerpts and built the abstention gate.
- Point-in-time correctness. Modeling
effective_date/superseded_dateversioning and a retrieval pipeline that over-fetches, filters by the time window, then trims — robust even when the vector index has no filter fields. - Consequential-action safety. Wiring a hard human-approval gate so no write to a compliance profile ever happens autonomously.
What we learned
- For high-stakes domains, abstention and citation discipline beat raw fluency — trust is the product.
- Time-awareness ("as of" retrieval) is what separates a regulatory assistant from a chatbot.
- A clean propose → approve → execute → audit loop is reusable across every partner bucket.
What's next
Expand the corpus to full DORA RTS/ITS, add cross-regulation contradiction detection, and reuse the obligation/audit spine across the other partner agents.
Built With
- cloud-build
- css
- express.js
- gemini
- gemini-3.5-flash
- google-cloud-agent-builder
- google-cloud-run
- html
- javascript
- model-context-protocol
- mongodb
- mongodb-atlas
- mongodb-atlas-vector-search
- mongodb-mcp
- node.js
- rag
- secret-manager
- tailwindcss
- text-embedding-004
- vertex-ai

Log in or sign up for Devpost to join the conversation.