-
-
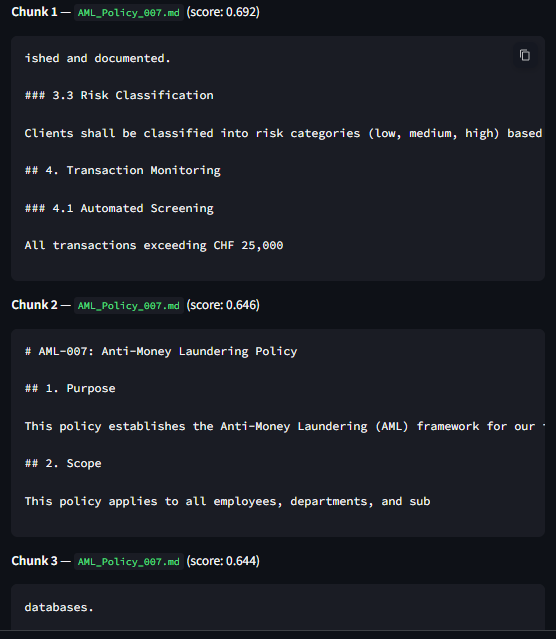
Chunks (RAG)
-
Dashboard
-
Key Requirements
-
Ticket Alert/Notification
Inspiration
Living and working in Zürich—a global hub for banking and insurance—we see firsthand the massive burden of regulatory compliance. Every time FINMA, the Swiss Federal Council, or the EU drops a new regulation, compliance teams at banks like UBS or ZKB spend weeks manually reading 80-page PDFs, cross-referencing them against hundreds of internal policies, and writing gap analyses.
A single missed update can result in millions in fines. But here is the catch: Swiss banks cannot just upload their highly confidential internal policies to ChatGPT. Due to banking secrecy and the revised Swiss Data Protection Act (revDSG), cloud-based AI is a non-starter. We realized the industry needed a powerful AI agent that runs entirely on-premise.
What it does
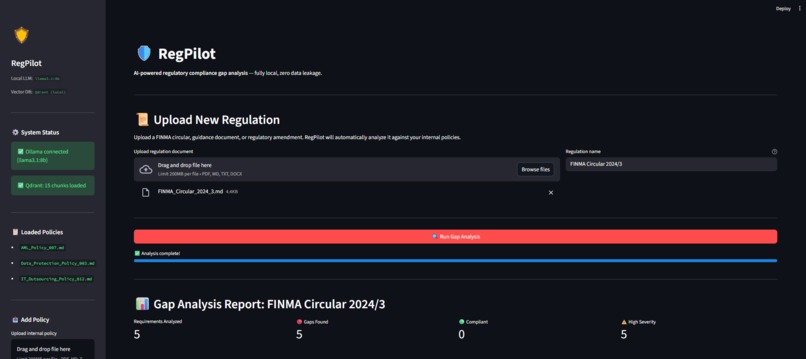
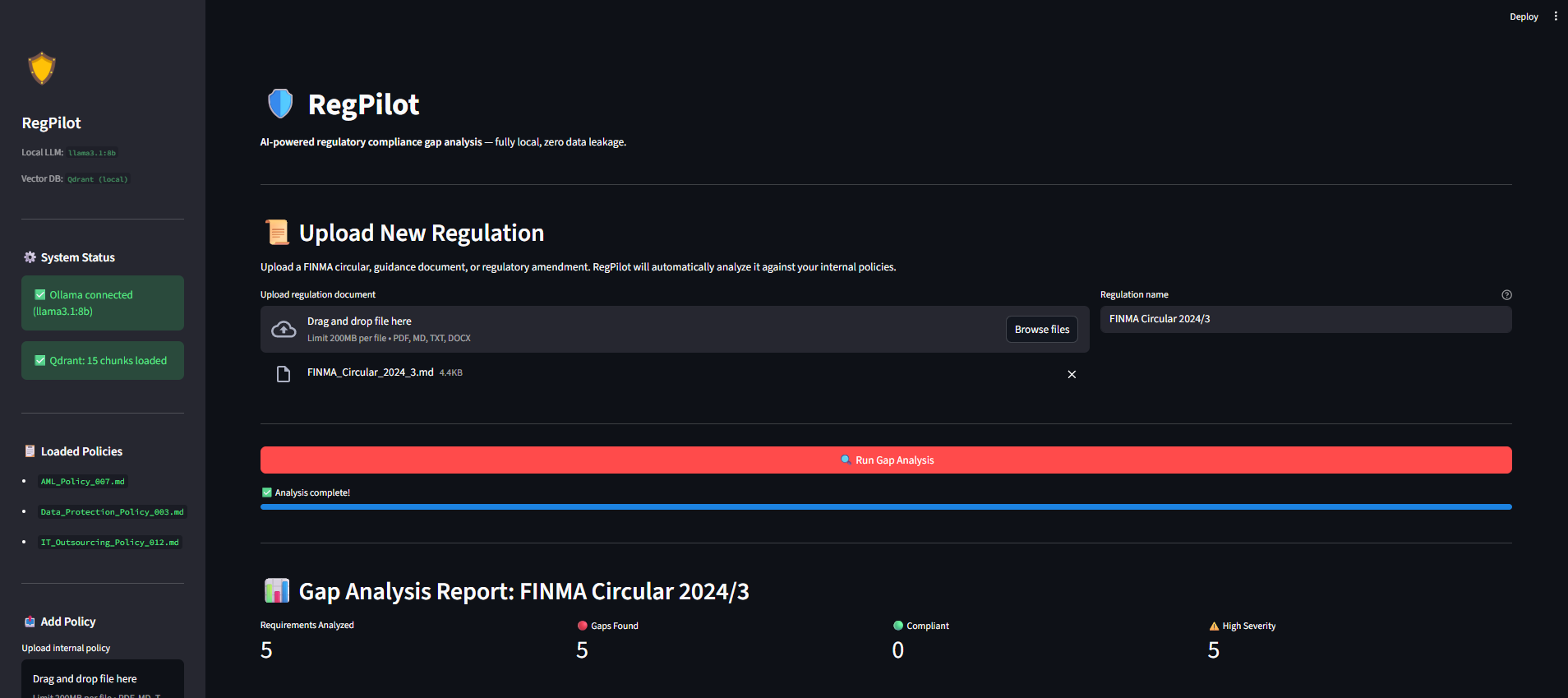
RegPilot is an automated compliance gap-analysis agent that runs 100% locally with zero data leakage.
- Ingestion: It securely embeds a bank's existing internal policies (AML, IT Outsourcing, Data Protection) into a local vector database.
- Analysis: When a new regulation is published (e.g., FINMA Circular 2024/3), you upload it to RegPilot.
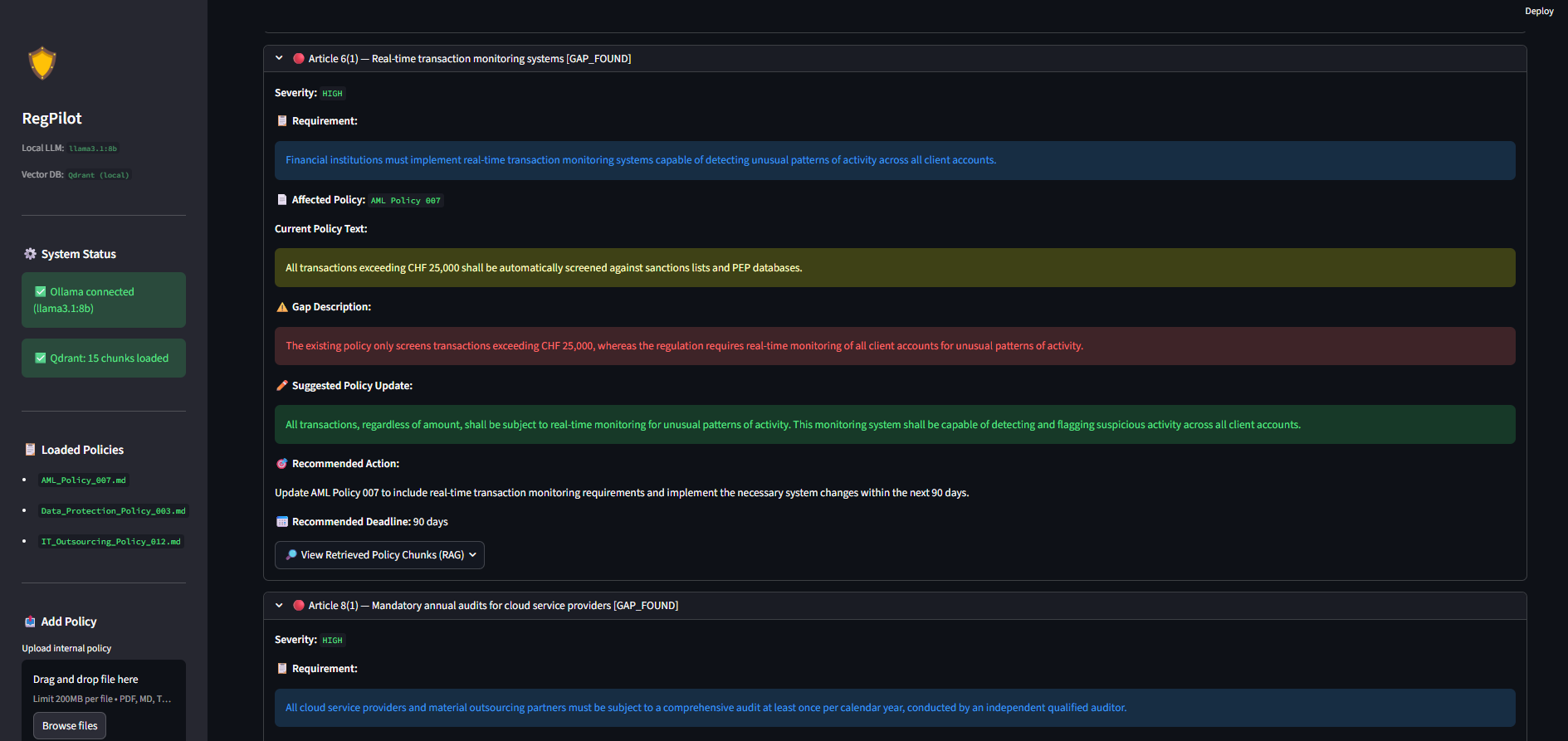
- Extraction: The local AI parses the regulation and extracts the core mandatory requirements.
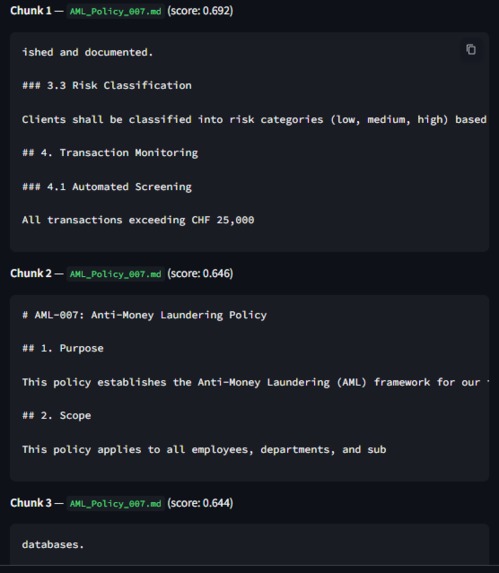
- RAG Pipeline: It searches the internal policies for paragraphs related to each new requirement.
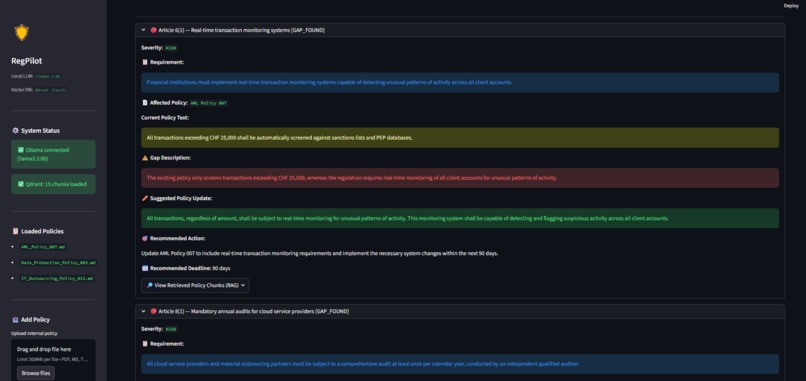
- Gap Detection: It compares the regulation against the current internal policy, identifies if there is a compliance gap, flags the severity, and automatically drafts the corrected policy text.
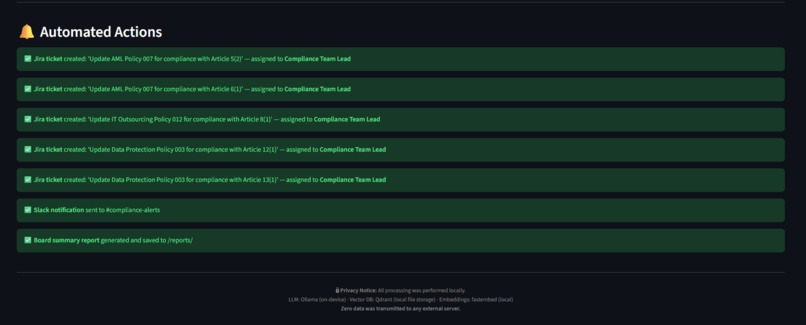
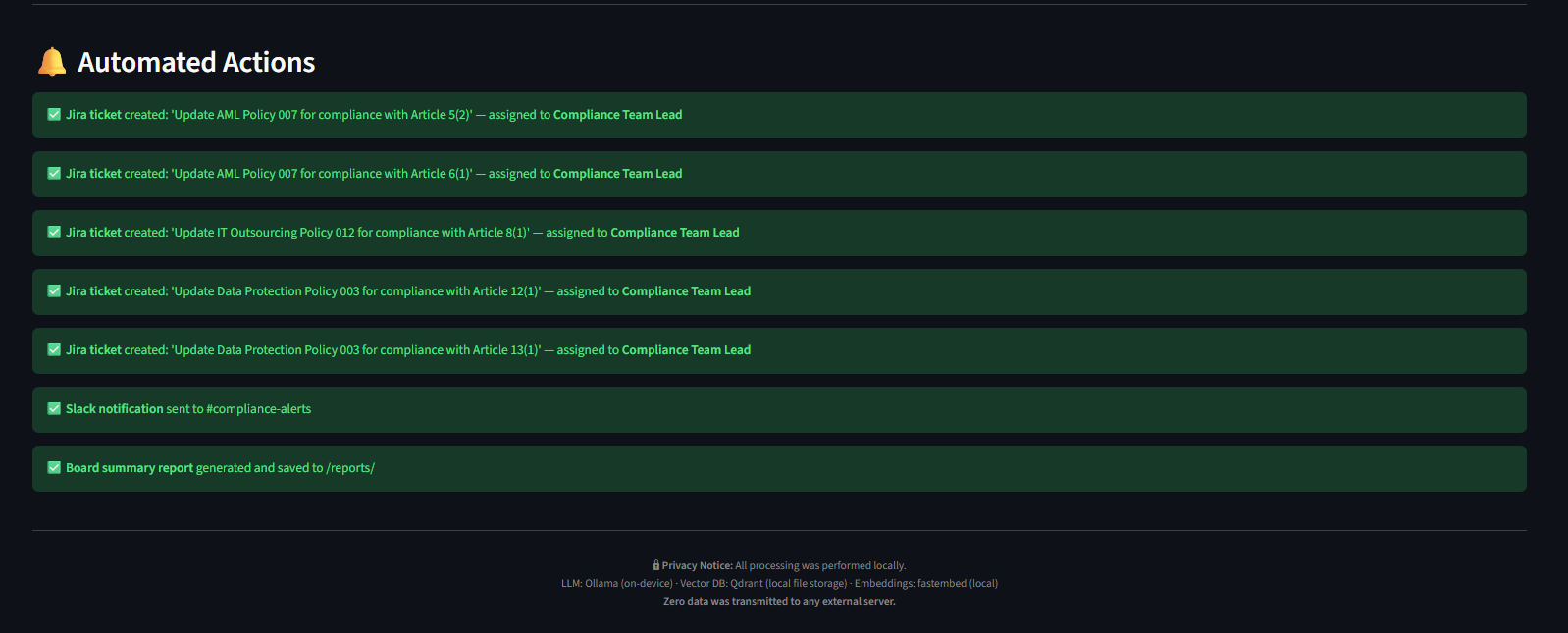
- Agent Actions: It simulates enterprise workflows by generating automated Jira tickets and Slack alerts for the compliance team.
How we built it
We focused on building a robust, privacy-first Retrieval-Augmented Generation (RAG) architecture:
- Vector Database: We used Qdrant (running purely via local file storage) to store our document embeddings.
- Embeddings: We used
fastembed(BAAI/bge-small-en-v1.5) to generate high-quality text embeddings directly on the CPU without any API calls. - LLM Engine: We used Ollama running the Llama 3.1 (8B) open-source model locally to perform the reasoning and gap analysis.
- Frontend: We built a sleek, responsive UI using Streamlit.
- Document Parsing: We used
PyMuPDFto handle complex formatting in legal PDFs and Markdown files, implementing a semantic chunking strategy with a 50-character overlap to prevent losing legal context.
The math behind our semantic search relies on Cosine Similarity within Qdrant:
Mathematical Foundation
The semantic retrieval process relies on cosine similarity to measure the relevance between document embeddings.
Cosine similarity is defined as:
$$ \text{CosineSimilarity}(A,B) = \frac{A \cdot B}{|A||B|} $$
Where:
- A = embedding vector of the regulatory requirement
- B = embedding vector of an internal policy paragraph
- A · B = dot product of the vectors
- ‖A‖ and ‖B‖ = magnitudes (Euclidean norms) of the vectors
The similarity score ranges from -1 to 1, where:
- 1 → identical semantic meaning
- 0 → unrelated
- -1 → opposite meaning
Qdrant ranks the most relevant internal policy chunks based on this similarity score, enabling RegPilot to efficiently identify potential compliance gaps.
Built With
- fastembed
- llama-3
- ollama
- pymupdf
- python
- qdrant
- streamlit



Log in or sign up for Devpost to join the conversation.