-
-

Hardware side of the Reactor
-
Landing Page
-

Landing Page cont.
-
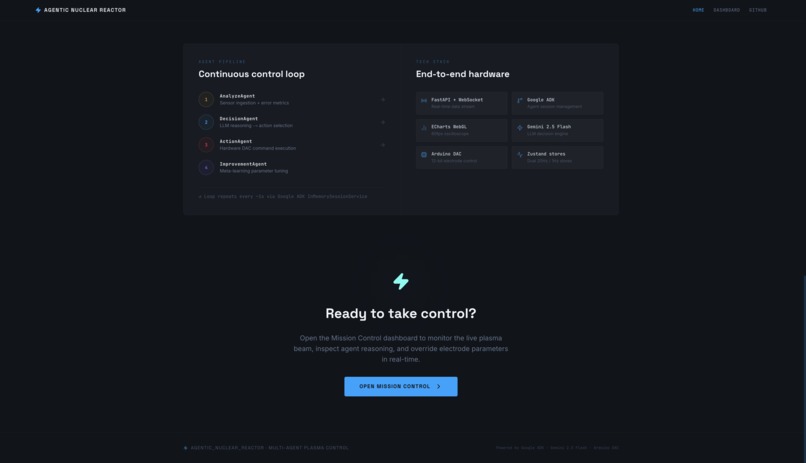
Landing Page cont.
-
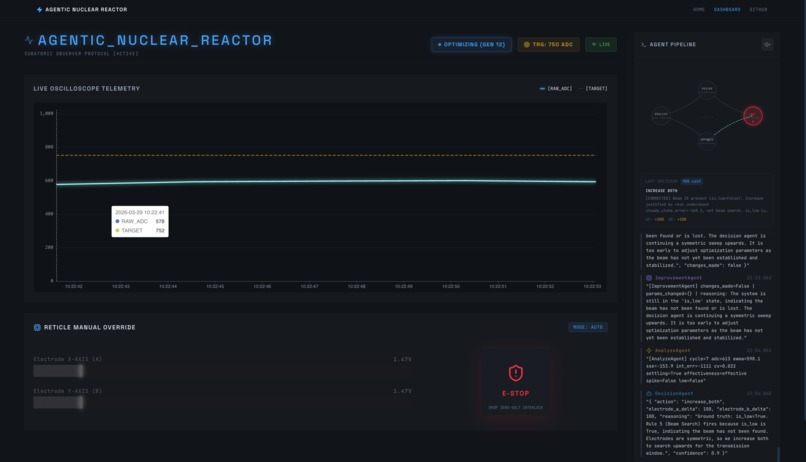
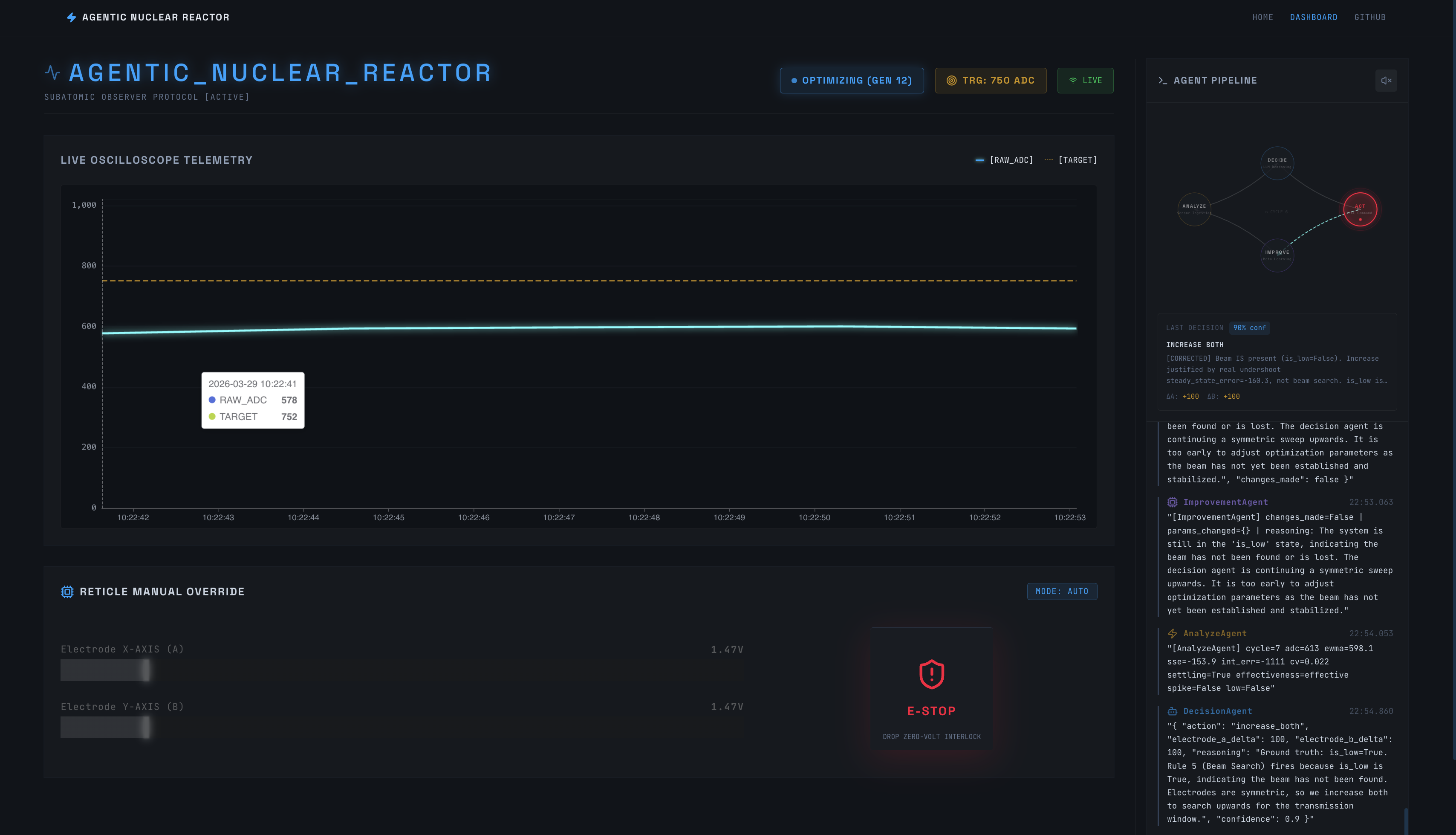
Dash Board with real time data
-
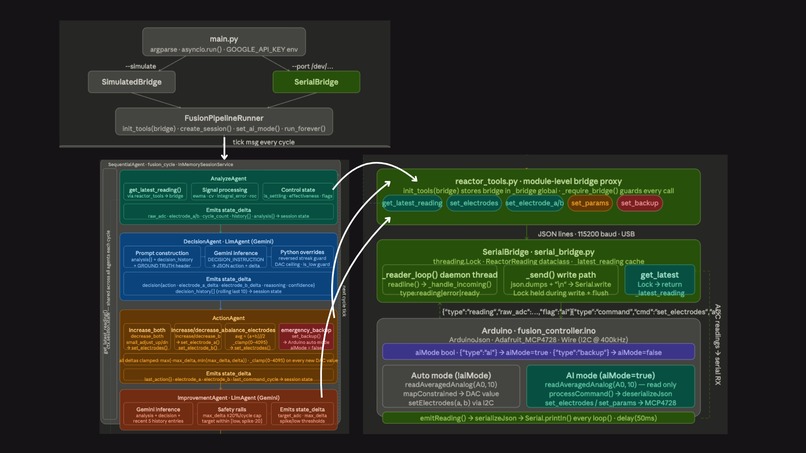
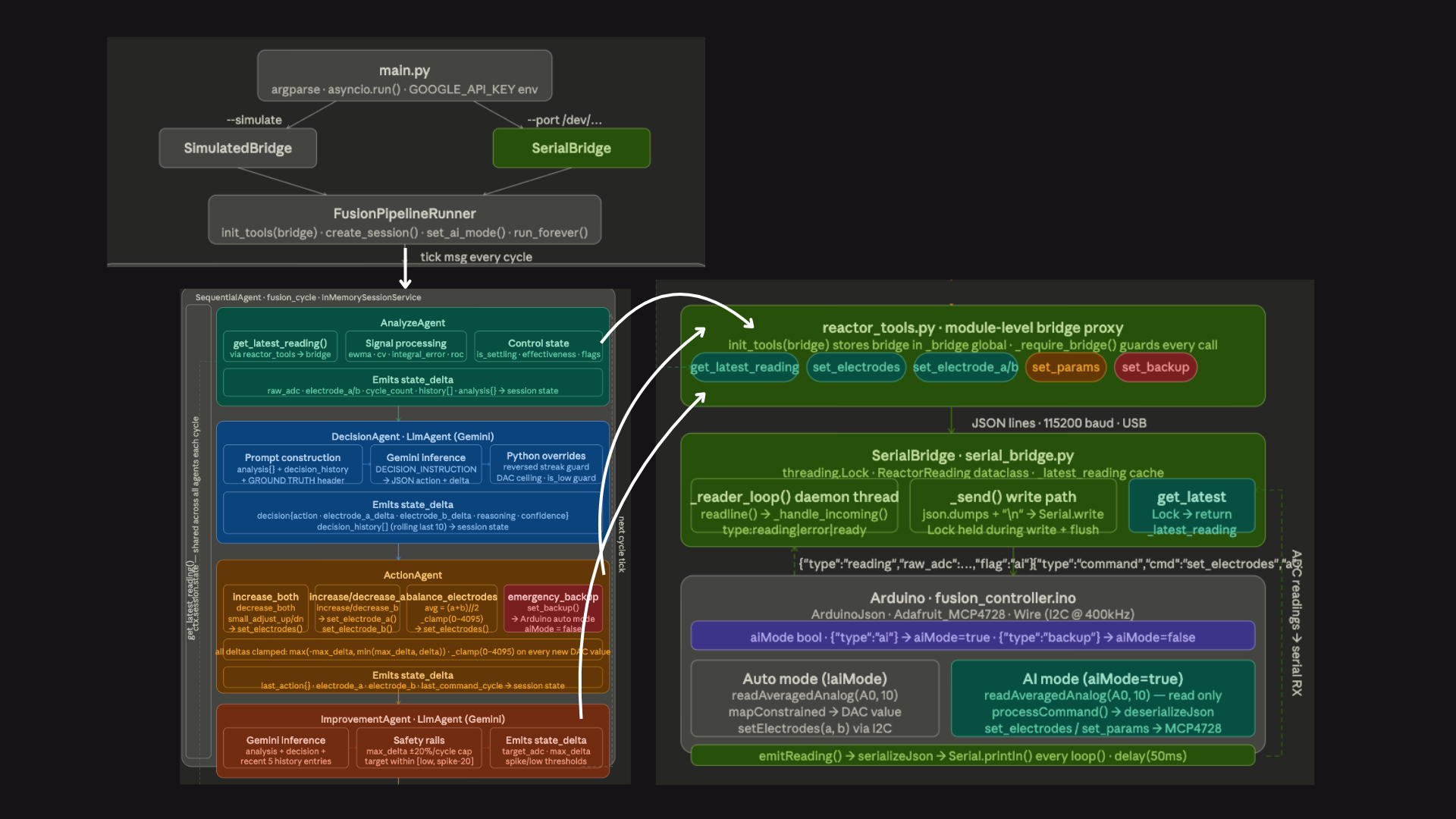
ADK Agents Pipeline


Inspiration
Nuclear physicists spend countless hours manually tuning electrostatic fields to focus charged particles in experimental reactors. Inspired by inertial electrostatic confinement (IEC) devices like fusors, we asked: can a Large Language Model autonomously steer a high-voltage particle beam in the physical world?
We combined vacuum physics, embedded microcontrollers, and Google's AI Agent framework to build a completely self-optimizing smart reactor demo.
What it does
Our system fires a 3kV electron beam toward a Faraday cup inside a vacuum chamber. Two electrostatic steering rings surround the beam. A swarm of four AI agents continuously monitors electron collision counts via an LM358 op-amp and autonomously adjusts the 12V steering ring voltages in real time , no human turning knobs.
How we built it
Three deeply integrated engineering layers: Hardware — A vacuum chamber with a copper nail cathode and copper ring anode powered by a 3kV supply. An Arduino reads micro-currents from the Faraday cup and controls two DAC channels connected to 12V steering supplies. Intelligence Engine (Python / FastAPI / Google ADK) — A middleware pipeline built on FastAPI and Google's Agent Development Kit. Four specialized agents share a blackboard session state:
AnalyzeAgent — deterministic signal processing (EWMA, integral error, settling detection)
DecisionAgent — Gemini LLM reasoning about physics and choosing electrode adjustments
ActionAgent — hardcoded safety boundary clamping between the LLM and the hardware
ImprovementAgent — meta-LLM that tunes control thresholds across cycles
Mission Control Dashboard (Next.js / React / Tailwind) — A dark-mode lab UI with live ECharts oscilloscopes, electrode control sliders, and a terminal-style agent brain log. Connected to the Python layer via WebSockets for high-framerate real-time telemetry.
Accomplishments that we're proud of
We're most proud of the strict architectural safety boundary. The ActionAgent acts as an absolute physical safeguard between the LLM and the hardware, the LLM can reason about whatever it wants, but the max_delta clamp and DAC ceiling ensure voltage boundaries are structurally impossible to breach, regardless of what the model decides.
Challenges
The latency vs. physics problem was the core challenge. Beam experiments run in short discrete bursts. With LLM API calls taking ~500ms per decision cycle, the AI only gets a handful of real decisions before the experiment ends. We solved this with cross-run state memory , the system saves the best trajectory coordinates from each run and injects them as starting conditions for the next, letting the AI iteratively dial in the physics across multiple bursts.
What we learned
How to decouple slow LLM reasoning from high-speed hardware polling. Using WebSockets, asyncio event buses, and Zustand state stores, the UI oscilloscope never lags even when Gemini is mid-inference. The bridge between the ADK session state and the physical serial port taught us exactly where software time and hardware time need to be treated as completely separate concerns.
What's next?
The same feedback loop that steers electrons into a Faraday cup can steer a therapeutic particle beam onto a tumor. We want to explore applying this architecture to radiation therapy, where millimeter-precise targeting of cancerous cells is the difference between treatment and collateral damage. Instead of maximizing Faraday cup current, the optimization target becomes dose conformality: getting maximum radiation onto the tumor volume while minimizing exposure to surrounding healthy tissue. The AI agent pipeline, the safety boundary architecture, and the real-time steering control are all directly transferable. Multi-modal perception is the next step , adding camera and imaging feeds so the LLM can process visual tissue density alongside numerical beam measurements to make smarter, safer targeting decisions in real time.
 Ho")










Log in or sign up for Devpost to join the conversation.