-
-
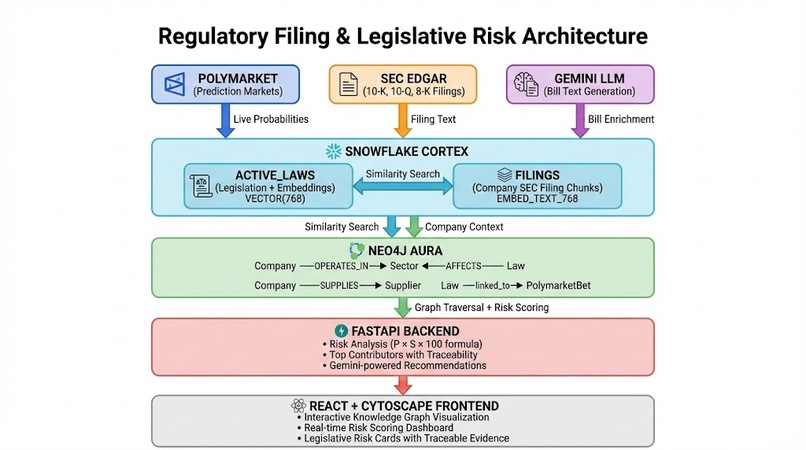
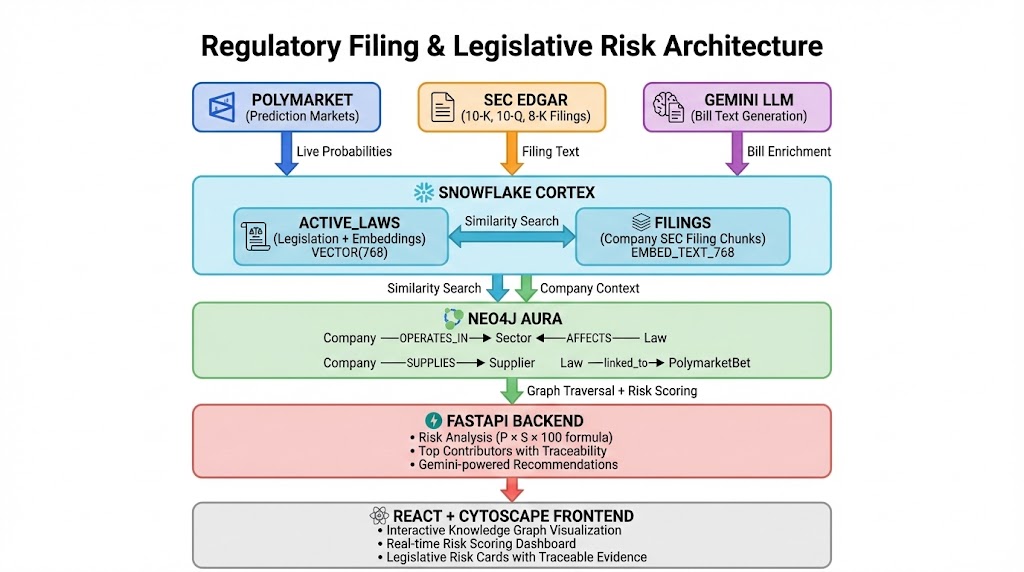
System Overview
-
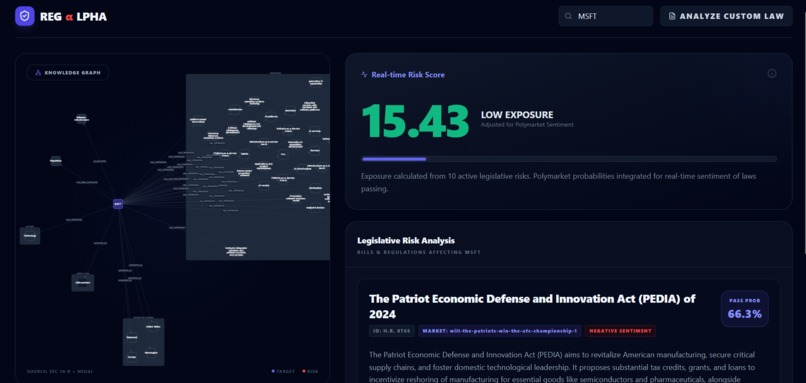
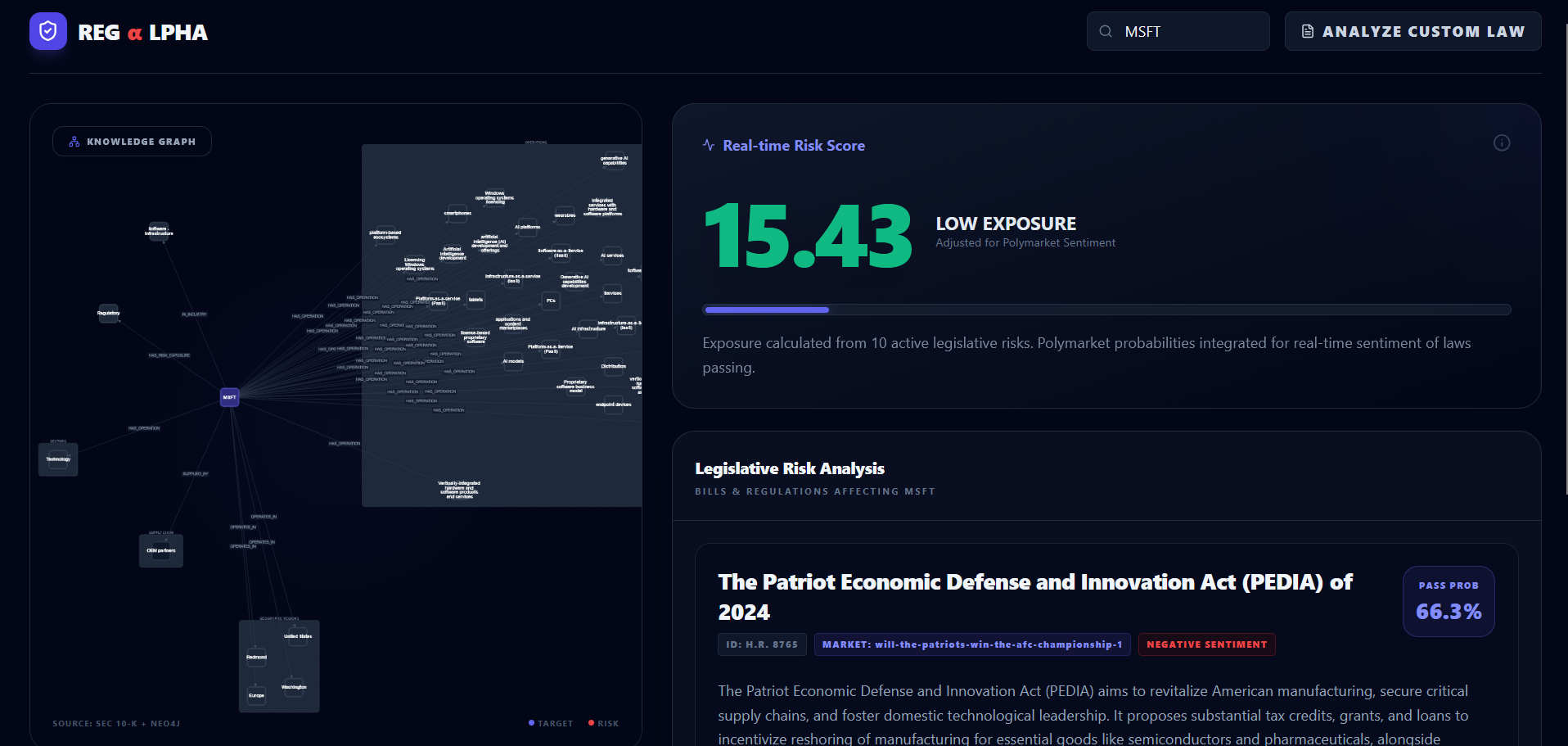
App Overview
-
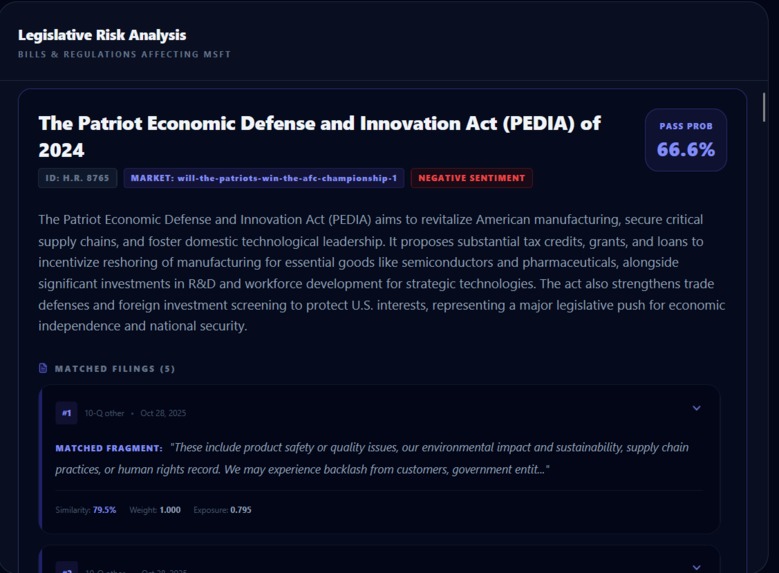
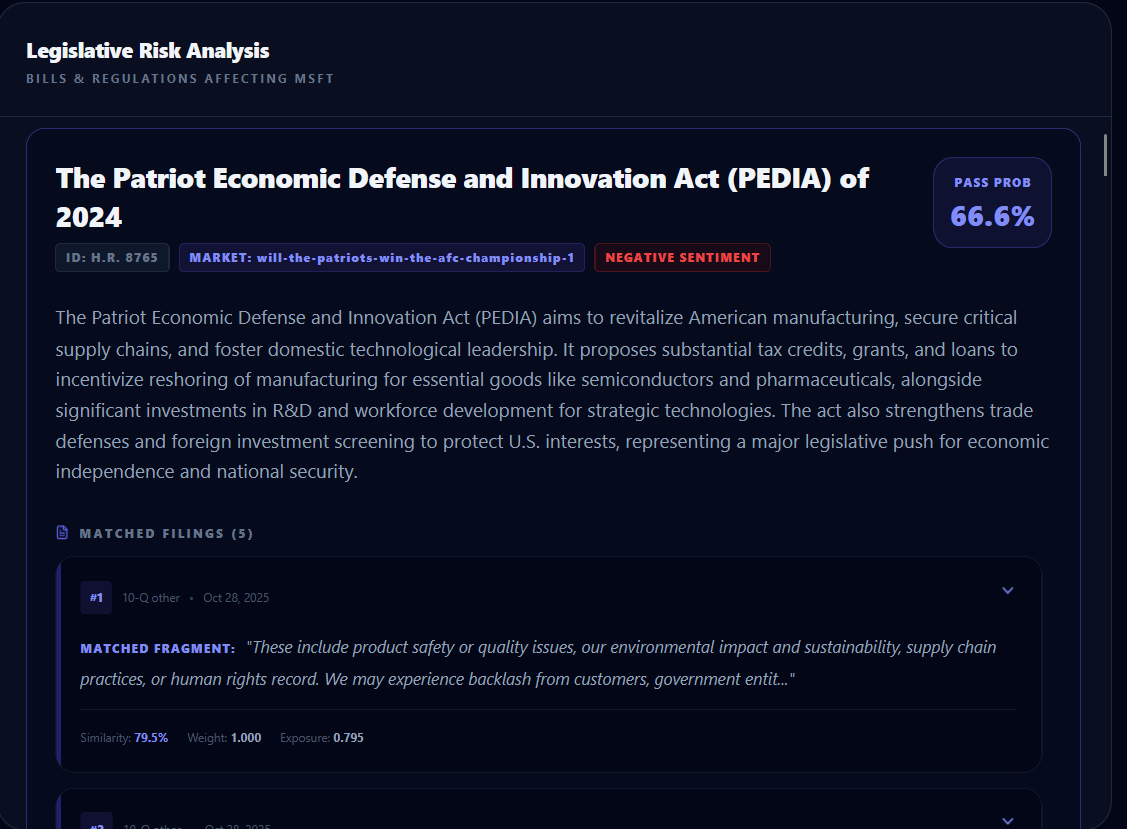
Legislation Matched to SEC filing excerpt
-
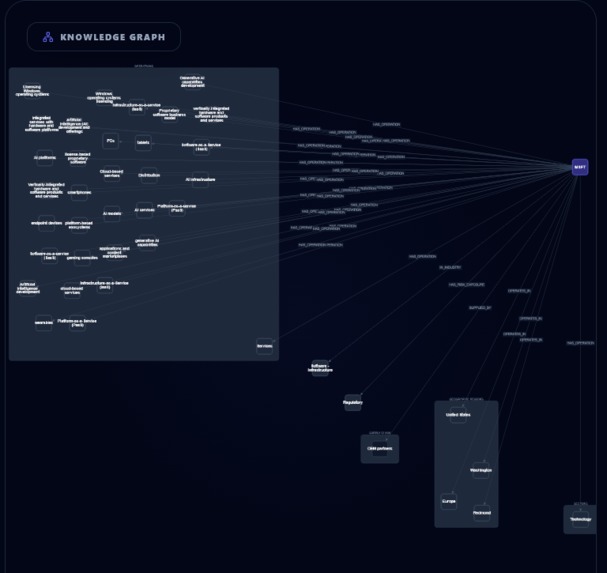
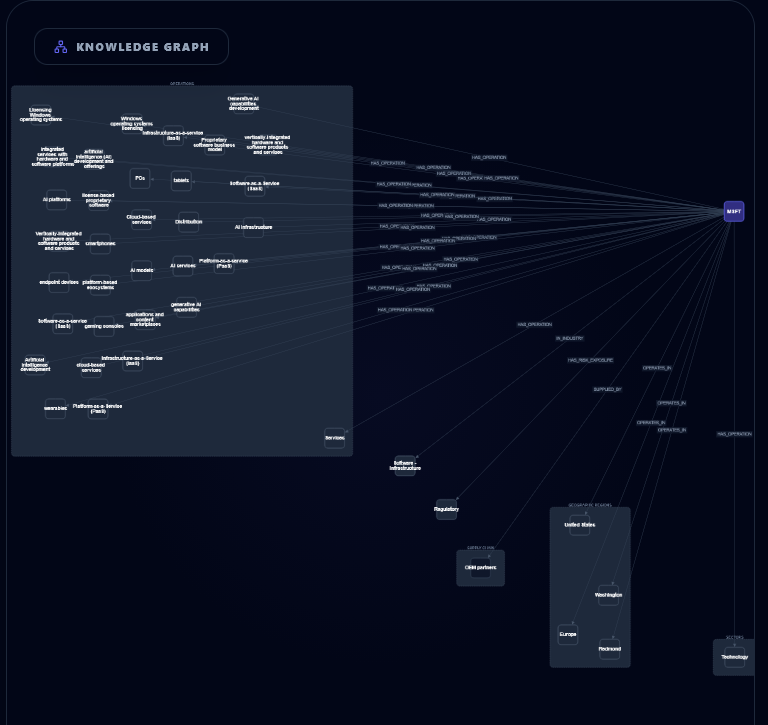
Knowledge Graph
-
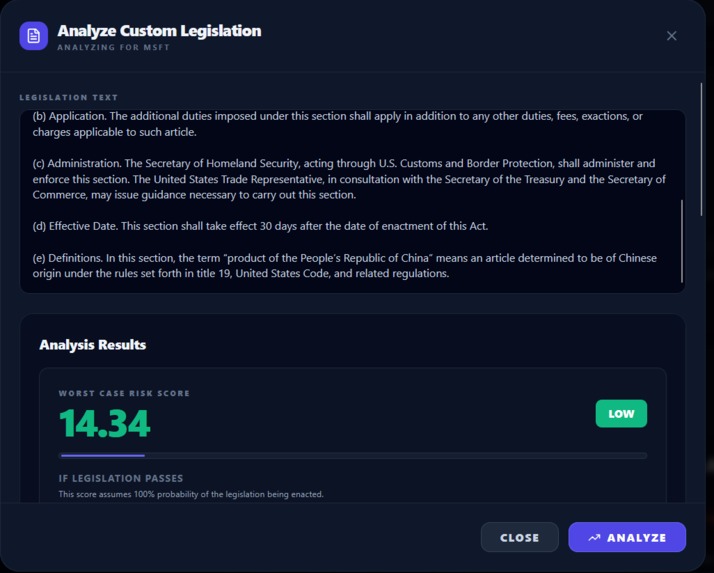
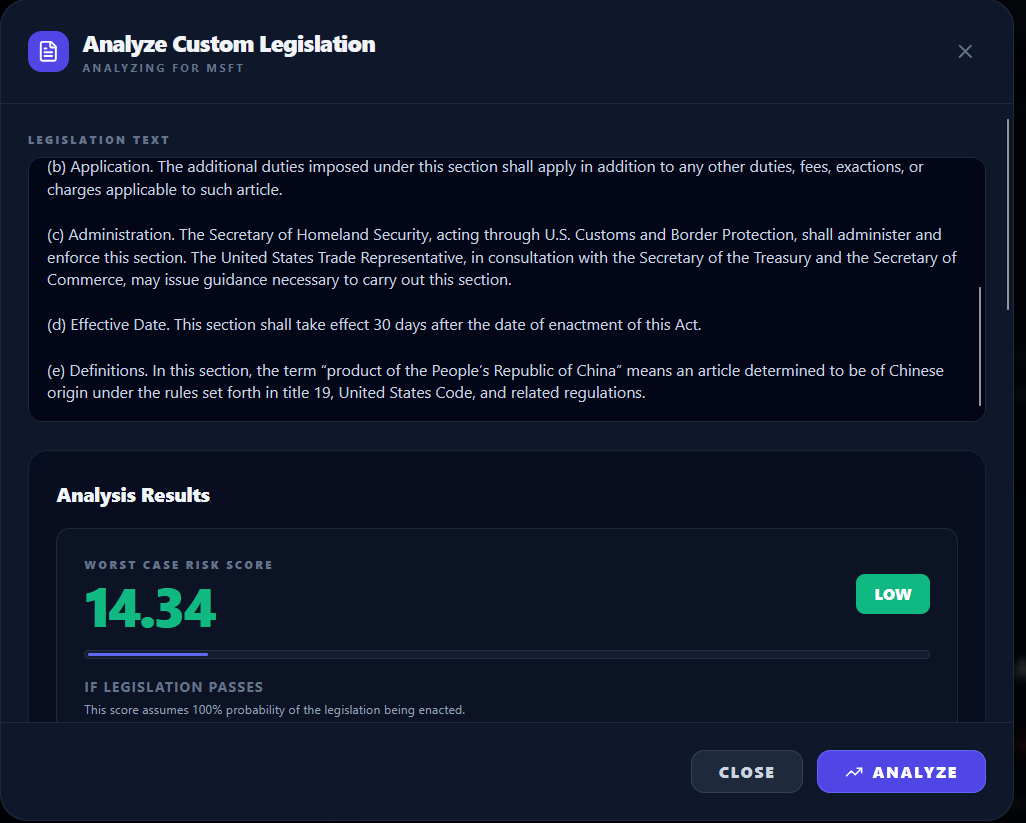
Custom Legislation Analysis
-
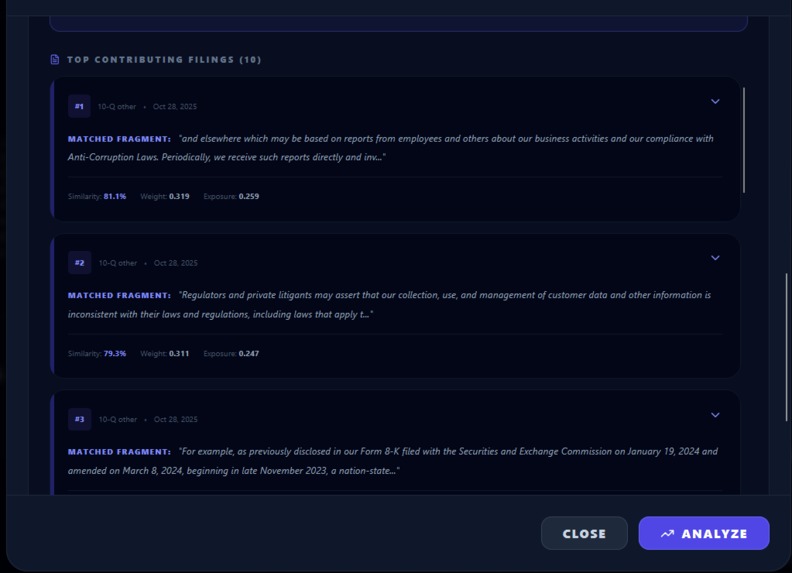
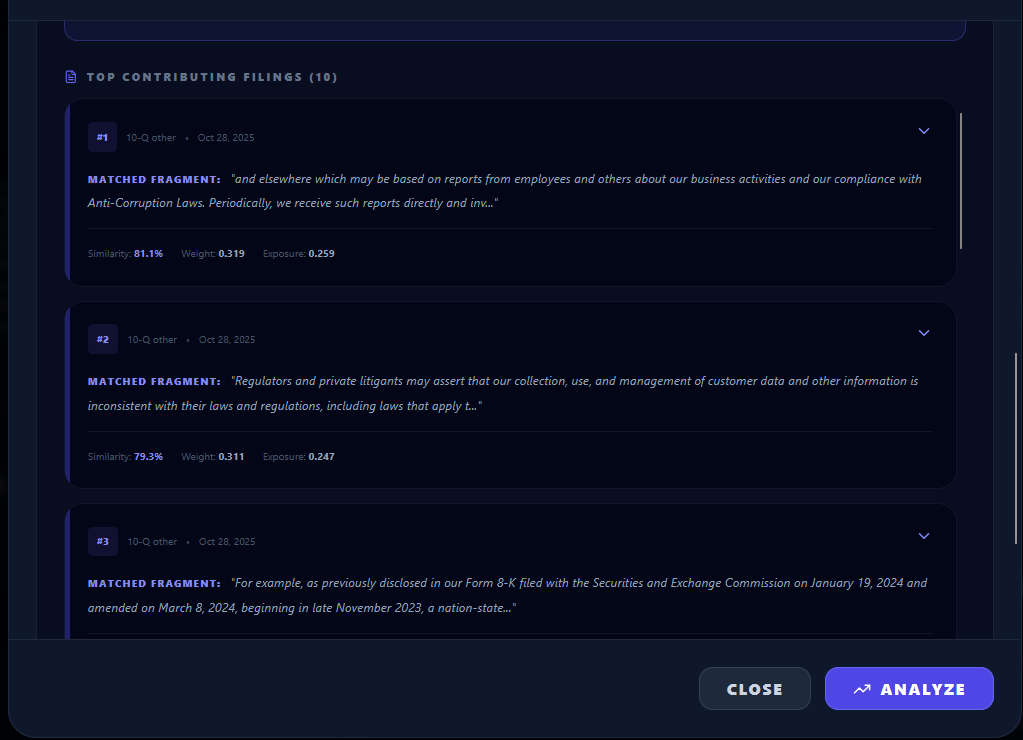
Custom Legislation Matched SEC filings
Inspiration
Legislation moves markets, but the signal is fragmented: the “what” lives in dense 10‑K/10‑Q/8‑K risk factors while the “will it happen?” changes daily. RegAlpha bridges that gap by using Polymarket’s market‑implied odds as a live uncertainty signal and grounding the impact in traceable SEC filing evidence—so you can see both the probability of a law passing and exactly why it matters for a specific company.
What it does
RegAlpha helps you pick a ticker and instantly see:
- Real-time legislative risk for that company, adjusted by Polymarket pass probabilities (a live signal of “how likely this becomes real”)
- The exact SEC filing excerpts that triggered the score (the “why”)
- An interactive knowledge graph linking companies, sectors, suppliers, and laws, surfacing indirect exposure (e.g., sector-level spillover and supplier-chain risk)
- Custom legislation “what-if” mode: paste a proposed bill/regulation (or draft language) and instantly see its company-specific impact, with traceable SEC filing excerpts. (We treat custom laws as worst-case p=1 of passing since there’s no Polymarket market.)
How we built it (deeper)
- Polymarket (live uncertainty signal):
- We pull active prediction markets from Polymarket’s Gamma API and compute the implied pass probability from the “Yes” outcome price.
- That probability becomes the uncertainty layer in the final risk: if the market reprices the likelihood of passage, the expected risk updates automatically (instead of treating every bill as equally likely).
- Gemini (market → legislation enrichment):
- Polymarket markets often start as short questions (“Will X pass?”). We use Gemini 2.5 to transform that sparse prompt into structured legislative metadata: a likely bill identifier, title, a multi-paragraph “bill text / key provisions,” a concise summary, and affected sectors.
- This enrichment makes downstream retrieval possible: instead of embedding only a one-line question, we embed substantive legislative language that can actually match filing risk factors.
- Snowflake Cortex (RAG + vector engine):
- We chunk SEC filings into semantic passages and store them in Snowflake with embeddings generated by Cortex
EMBED_TEXT_768, enabling fast similarity search at scale. - We also chunk enriched legislation and store it in an
ACTIVE_LAWStable with the same embedding dimension, so we can retrieve laws similar to a company’s filings and filing passages similar to a given law. - At query time, we run vector similarity search in Snowflake to retrieve top matches (and their similarity scores) without recomputing embeddings in the app.
- We chunk SEC filings into semantic passages and store them in Snowflake with embeddings generated by Cortex
Risk scoring:
- We compute exposure from matched filing chunks using similarity plus weighting (section importance, recency decay, and chunk size).
- Then we incorporate Polymarket probability to produce an “expected” risk (market-weighted) vs a “worst-case” scenario (assuming passage).
Neo4j knowledge graph (context + indirect risk):
- We populate Neo4j with nodes for Company/Sector/Supplier/Law and relationships like
AFFECTS(Law→Sector) and company context edges. - This adds interpretability and lets us reason about second-order effects (e.g., a law affecting a sector that a supplier depends on).
- We populate Neo4j with nodes for Company/Sector/Supplier/Law and relationships like
Frontend:
- React + TypeScript with a risk dashboard, law cards showing pass probability, and expandable matched-filing evidence.
- The knowledge graph is rendered interactively using Cytoscrape.js so users can “see” exposure paths instead of reading a wall of text.
Challenges we ran into
- Markets aren’t bills: Polymarket questions don’t always map cleanly to an official bill ID. We solved this by using Gemini structured outputs with fallbacks and focusing on generating realistic legislative language for retrieval.
- Scaling to the S&P 500 under hackathon time: Ingesting and embedding the sheer volume of 10‑K/10‑Q/8‑K filings is huge, so for the demo we constrained coverage to a small subset (top ~10 S&P 500 companies) to keep ingestion, vectorization, and iteration feasible.
- Indirect/related-entity scoring: We wanted to score second-order exposure (e.g., suppliers/peers) more comprehensively, but accurately modeling and validating those relationships end-to-end within the time window was challenging—so we focused on getting direct company↔legislation risk and explainability solid first.
Accomplishments we’re proud of
- Real-time sentiment in the scoring loop via Polymarket probabilities (expected vs worst-case framing).
- End-to-end explainability: every risk score is backed by the specific SEC filing excerpts that drove it.
- Knowledge-graph enrichment: the graph turns “risk score” into “risk story,” revealing indirect exposure paths.
What we learned
- Prediction markets are an effective way to represent legislative uncertainty as a numeric signal you can compute with.
- Cortex-style vector search becomes far more persuasive when paired with provenance (top matches) and a visual knowledge graph.
What’s next
- Actionable hedging strategies: generate portfolio recommendations (e.g., sector ETF hedges, options overlays, position sizing) tied directly to each law’s probability and the filing-backed exposure drivers.
- Stronger entity linking + propagation for indirect risk (supplier→sector→law), with better validation.
- Backtesting: compare historical policy outcomes vs. Polymarket odds and post-event stock moves.
Built With
- cytoscape.js
- fastapi
- google-gemini
- neo4j-aura
- react
- snowflake-cortex
- tailwind-css
- tanstack-query
- typescript


Log in or sign up for Devpost to join the conversation.