-
-
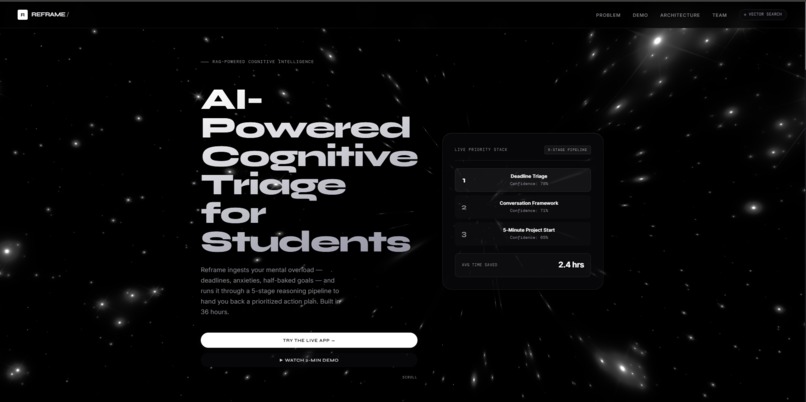
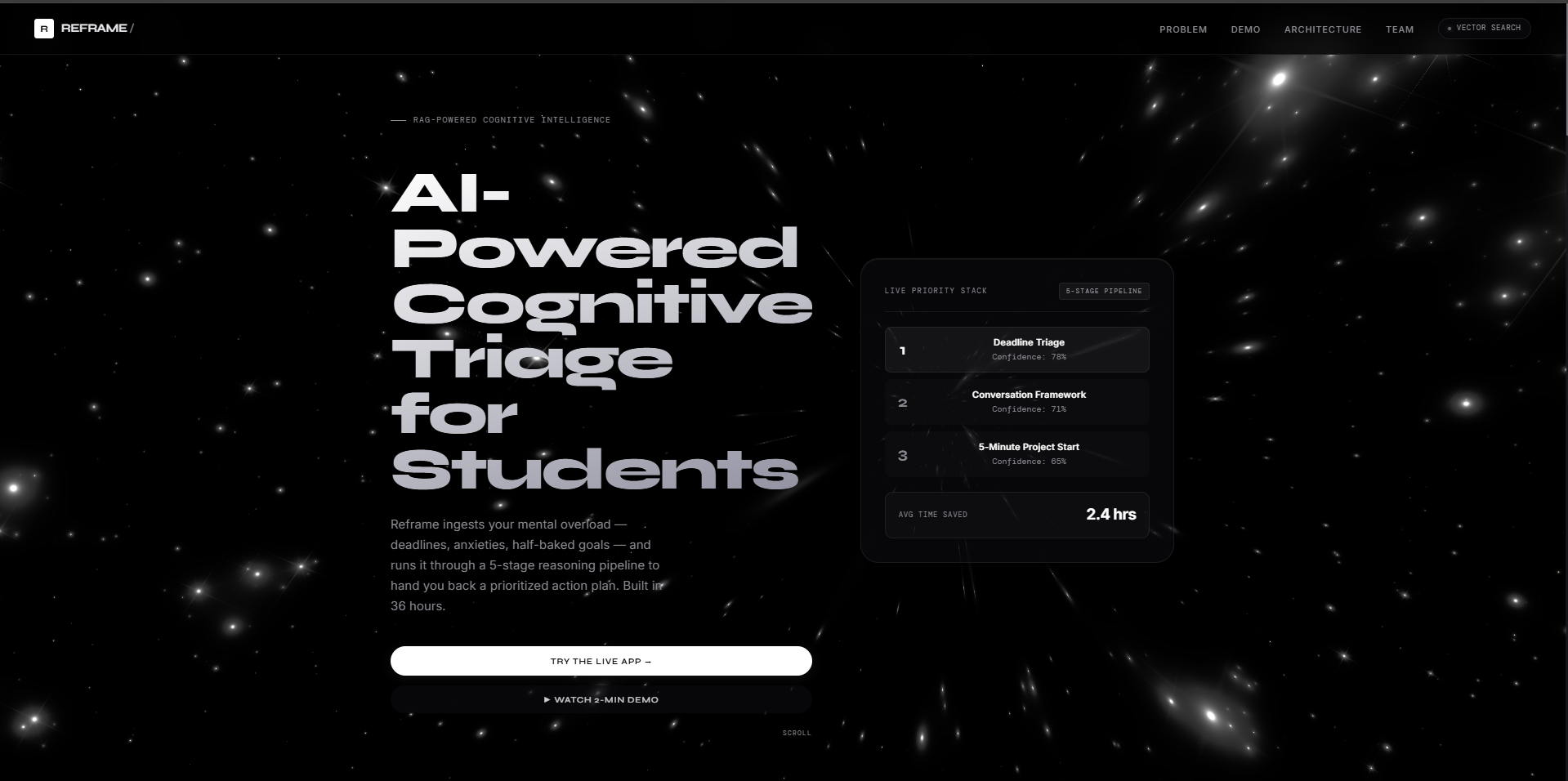
Reframe's landing page: AI-powered cognitive triage that turns deadlines and anxiety into a confidence-scored priority stack.
-
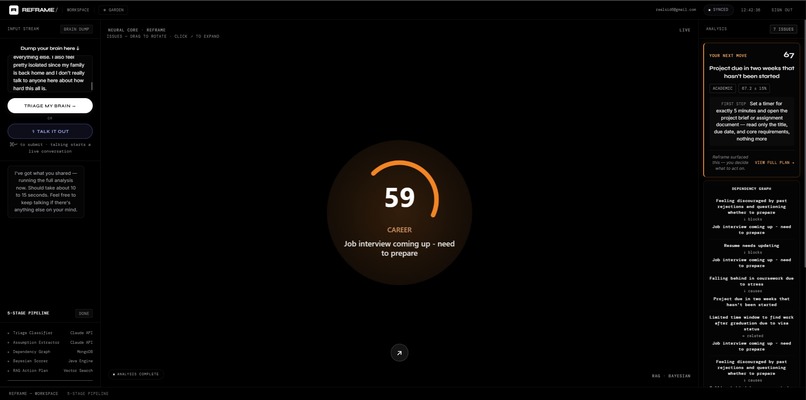
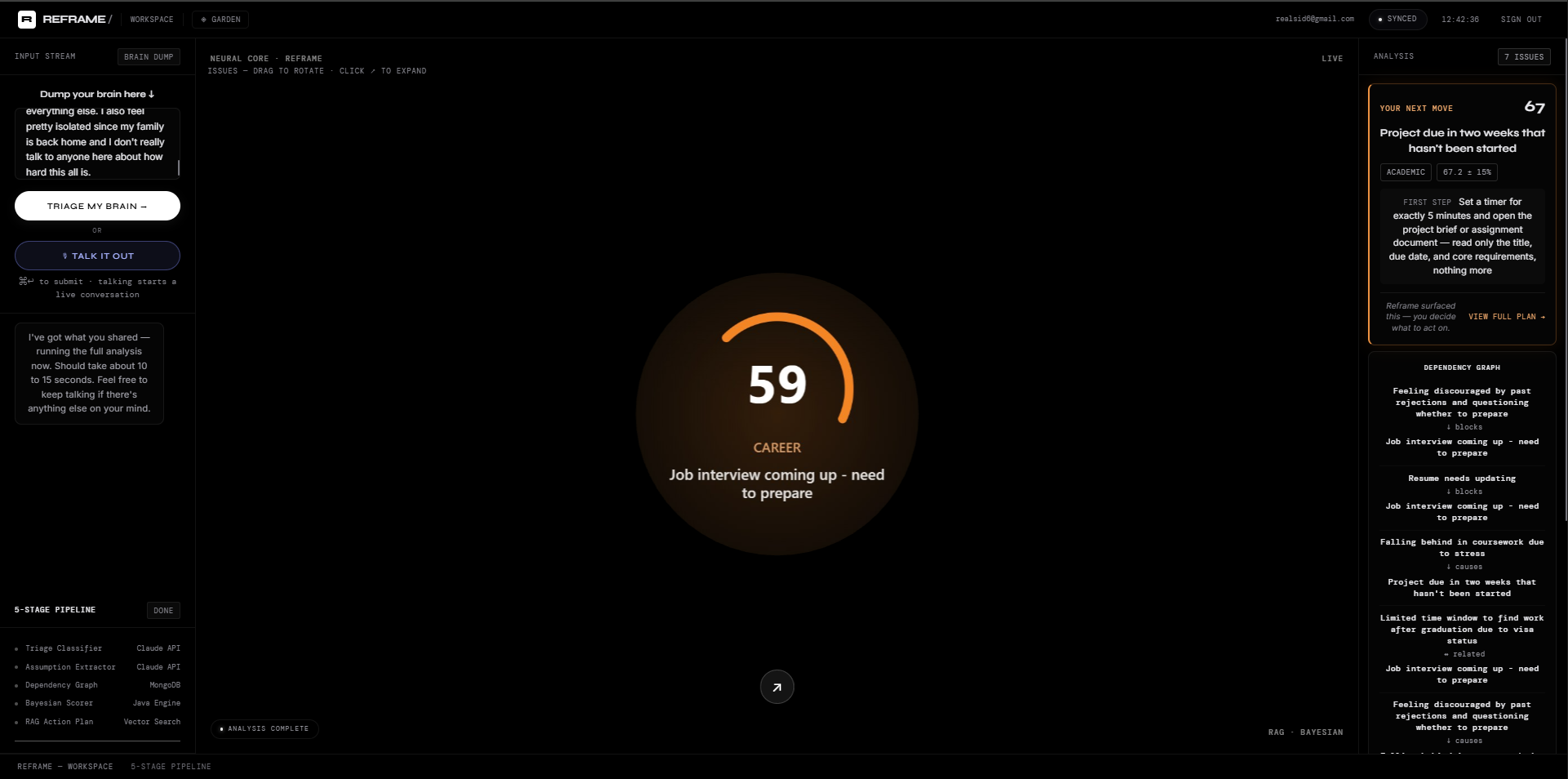
Your Next Move surfaces one clear, confidence-scored action, backed by a live dependency graph showing what's actually blocking what.
-
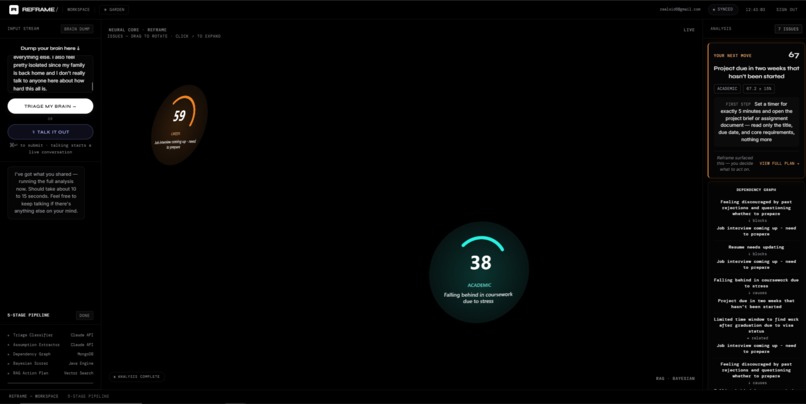
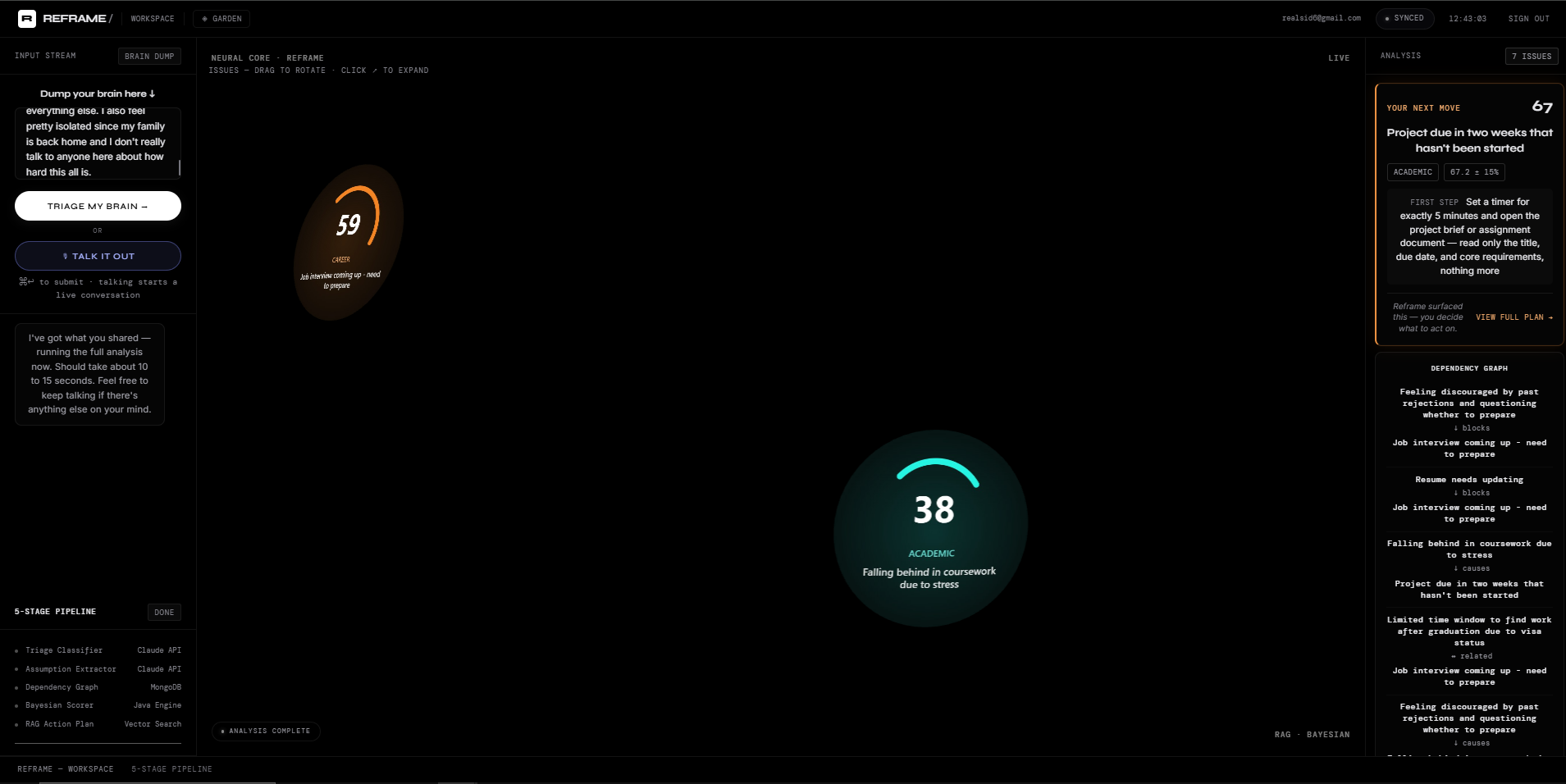
Multiple issues from one brain dump, each scored and visualized in real time as the 5-stage pipeline completes.
Inspiration
This project almost wasn't Reframe. I went into this hackathon wanting to build a second-brain tool for people living with dementia. Once the full challenge brief came out, it was clear that idea didn't actually fit what this hackathon was asking for, so we pivoted, fast, into something that did.
The real inspiration came from somewhere closer to home: me.
I'm an international student in Canada doing a CS degree, and the job search has been brutal. Rejection after rejection. On top of that I'm far from my family, which gets lonely in a way that's hard to explain unless you've lived it. Add academic pressure, visa status hanging over everything, and money stress, and what I kept running into wasn't a lack of effort. It was freeze. Too many overlapping problems at once, no clear sense of which one to actually act on first, so I'd just stall.
I wished I had something that could take all of that noise and hand me back one honest answer: here's what actually matters right now, here's what's blocking what, and here's the one thing to do next. That tool didn't exist, so we built it. Reframe is for students, early professionals, or really anyone who's overwhelmed enough that they've stopped moving, not because they don't care, but because there's too much to even know where to start.
What it does
You talk to Reframe, or type to it if you'd rather, and just dump everything that's stressing you out. No formatting, no structure, just however it comes out of your head.
Behind the scenes, a 5-stage pipeline takes that mess and turns it into something usable:
- It splits your brain dump into distinct issues and classifies each one.
- For every issue, it surfaces the hidden assumptions you're carrying that you didn't say out loud, the unspoken fears and beliefs underneath the worry.
- It maps how your issues actually relate to each other, what's blocking what, what's causing what.
- It scores priority using real, deterministic math, not a black-box AI guess, and tells you exactly how confident it is and why.
- It retrieves a genuinely relevant coping or productivity framework using real vector search, and builds a concrete action plan grounded in that framework instead of generic AI advice.
You end up with one clear next move. Not a wall of reorganized chaos. One thing to actually do.
How we built it
The backend is Spring Boot (Java 25) with MongoDB for persistence. Claude handles the reasoning stages: triage, hidden-assumption extraction, and dependency mapping. The priority score itself is plain Java arithmetic, on purpose, so it's reproducible and explainable instead of an AI just asserting a number.
For the action plan stage, we built real retrieval-augmented generation. We have a small corpus of real frameworks (GTD, CBT cognitive defusion, the Eisenhower Matrix, and others), embed them with Voyage AI, and use cosine similarity to find whichever framework actually matches the meaning of your specific issue before handing that to Claude as grounding. It's not just picking a framework off a fixed category list; it's reading the actual content of what you wrote.
The frontend is React with a custom WebGL sphere that renders your issues as nodes you can rotate and click into. Voice input runs on the browser's native Speech API, completely free and separate from any paid service. Voice output (the assistant actually talking back) runs through ElevenLabs.
Challenges we ran into
The hardest bug of the hackathon looked like a network problem and wasn't. After building the real RAG pipeline, our embedding calls started failing intermittently. Testing the exact same request with curl worked every single time, which sent us chasing a phantom flaky-connection theory for a while. The real cause turned out to be Voyage AI's free tier rate limit of 3 requests per minute. Our pipeline was making 4 separate embedding calls per analysis in quick succession, blowing through that limit every time, while our isolated curl tests never came close to it because they weren't replicating the actual call volume. The fix was batching all the queries into a single call instead of retrying harder, which is the right lesson generally: when you hit a rate limit, reduce how many calls you're making before you reach for more retries.
We also ran our ElevenLabs free-tier credits down to almost nothing mid-build, which surfaced as a confusing 401 Unauthorized error instead of a clear quota message, so it briefly looked like our API key had broken rather than just running out of budget.
On the voice side, speech-to-text kept mishearing the user's own name, which meant the assistant would respond to the wrong person entirely. We had to build a phonetic correction to catch that reliably without it accidentally mangling unrelated words.
Accomplishments that we're proud of
We built retrieval-augmented generation for real, not just relabeled a hardcoded lookup table and called it RAG. The system genuinely reads the meaning of an issue and retrieves a framework that fits it.
The scoring system is fully explainable. Every priority number traces back to a formula you can read, not a number an AI decided and asked you to trust.
We made human-in-the-loop feedback actually mean something. When you tell Reframe one of its assumptions about you is wrong, that rejection is saved to the database and the confidence score is recalculated for real, not just adjusted cosmetically in the browser.
Voice and text are both first-class. Talking to Reframe never locks out typing, and typing never feels like the fallback option.
What we learned
That a small, in-memory vector search is a completely legitimate way to build real RAG at this scale, you don't need a hosted vector database to do this honestly.
That rate limits deserve to be designed up front, not patched over with retries after the fact.
And, honestly, building the tool I wished I'd had during my own worst weeks of overwhelm taught me a lot about my own patterns too. Writing the assumption-extraction prompts meant sitting with what kinds of hidden beliefs actually drive freeze, which was uncomfortable in a useful way.
What's next
Expanding the framework corpus so retrieval gets even more precise across more types of overwhelm. Persisting more of the human-in-the-loop feedback so the system actually adapts to a specific person over time instead of just within one session. And eventually, deploying it properly so it's not just a hackathon demo but something a stressed-out student could actually bookmark and use.



Log in or sign up for Devpost to join the conversation.